Apart from caching, I think the efficiency of this 'interleaved assignment' strategy also comes from the 'packed load' instruction. In 'blocked assignment' strategy, even if the data is cached, you still have to decode and execute four load instructions. While in this case only a single 'packed load' instruction is needed.
pajamajama
It was mentioned in lecture that this version of sin(x) would be preferable to one on the next slide (with the blocked assignment strategy) because of spatial locality--at each time i, the instances are accessing blocks that are contiguous in memory. Are there any cases in which a blocked assignment might perform faster than interleaved?
paracon
In some ways, the packed load SSE instruction has been provided to overcome the cache miss cost that could be encountered in each loop. If it weren't for this efficient instruction, the blocked interleaved assignment would show better locality in the cache. The placement policy used by the cache will also affect the throughput.
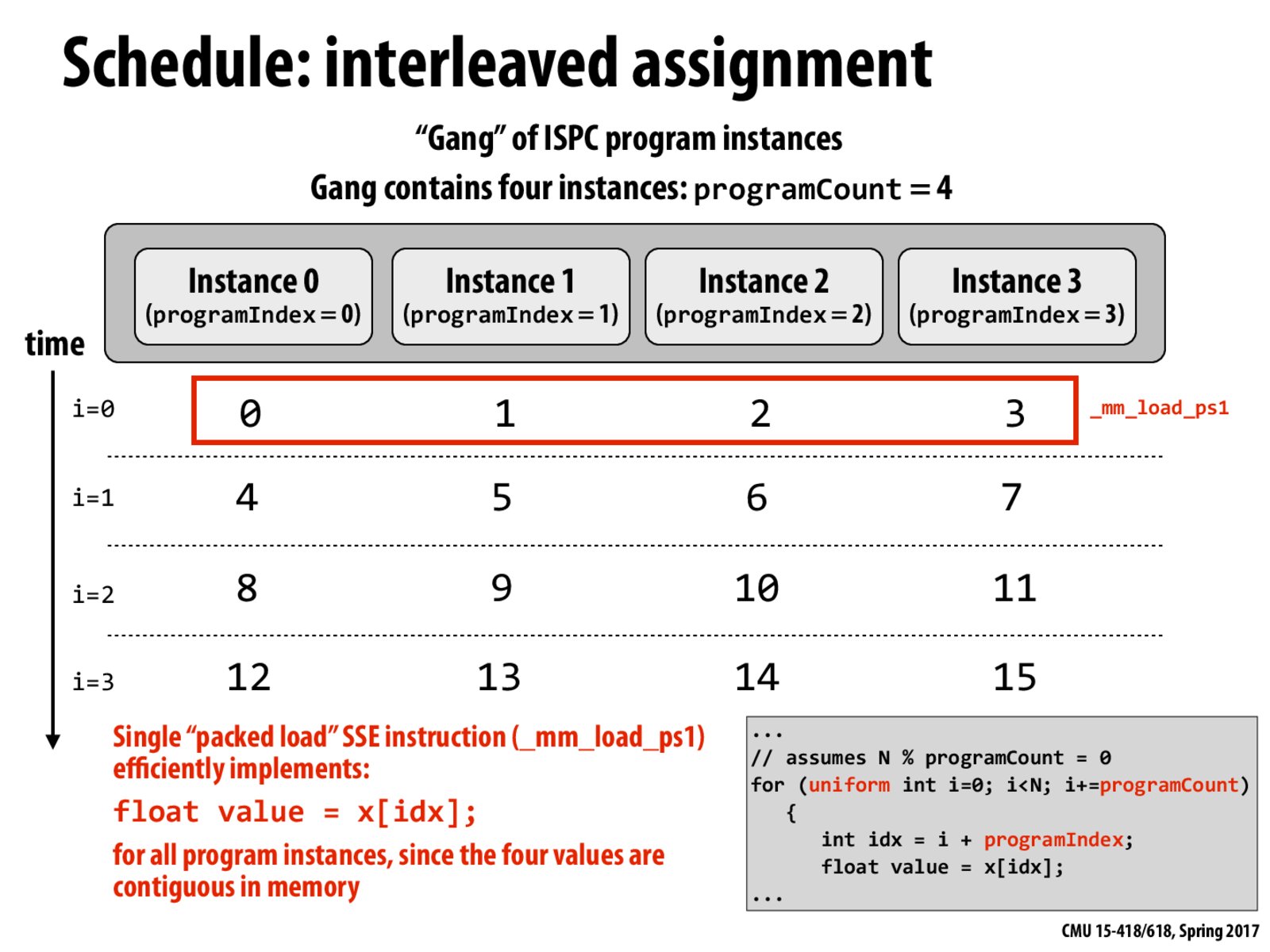
Apart from caching, I think the efficiency of this 'interleaved assignment' strategy also comes from the 'packed load' instruction. In 'blocked assignment' strategy, even if the data is cached, you still have to decode and execute four load instructions. While in this case only a single 'packed load' instruction is needed.
It was mentioned in lecture that this version of sin(x) would be preferable to one on the next slide (with the blocked assignment strategy) because of spatial locality--at each time i, the instances are accessing blocks that are contiguous in memory. Are there any cases in which a blocked assignment might perform faster than interleaved?
In some ways, the packed load SSE instruction has been provided to overcome the cache miss cost that could be encountered in each loop. If it weren't for this efficient instruction, the blocked interleaved assignment would show better locality in the cache. The placement policy used by the cache will also affect the throughput.