Before "gather" instructions were available, did this require 4 separate loads, one for each instance?
rohany
If we could execute this program on multiple cores, then I think this method would be the best? If one instance grabs the contiguous four elements, then on multiple cores it would have the whole cache line to itself and be more efficient than the interleaved instances as previous
PhiLo
I remember the prof said all instances are mapped to a single core. To run it on multiple cores, I think you have to use ISPC task?
Cake
Yes, this is the launch keyword that is covered in Assignment 1 from Program 3 onwards.
lilli
Blocked assignment with gather is more expensive, but sometimes the algorithm you implement requires using it.
rrudolph
What controls whether this us run on a single SIMD core or four indepentent cores? Is that handled by the OS or the ISPC interface? It seems like this scheme would work better (considering cache misses) in the case that it is run on multiple cores.
yeq
This version did not make good use of memory locality.
BestBunny
@yeq Just to qualify your response, it doesn't make use of spatial locality within the same time step although it still has good use of spatial locality across time. So, the inefficiency is also largely a result of having to access these different memory/cache locations at the same time step and the "gather" instruction that is mentioned on the slide.
kapalani
@rrudolph I believe its the ISPC interface. Specifically if we use the launch keyword, the program runs on multiple cores asynchronously and possibly concurrently, while the traditional SPMD parallelism runs the gang on the same SIMD core utilizing vector instructions.
nemo
Conclusion from this discussion:
If no tasks, then the processing happens on the same core.
'Gather' is better than 4 loads but worse than one packed load.
Caching is useful but number of instructions being run to access the data is also important.
rrp123
I remember Kayvon saying in class that in general, worker 0 in a gang generally uses vector lane 0 to run all it's load. Is this always true or was that the case just in this example?
tarabyte
Upon my first inspection, I thought this program would result in better use of the cache and spatial locality. However, it's actually the opposite. The program will instead cause a bunch of cache misses as the different instances overwrite the cache with the piece of the array it needs.
Levy
If you choose this kind of assignment, the ISPC compiler will throw a warning to you: [Performance Warning] ...
It also works for storing values.
whitelez
This reminds me another problem. In ISPC, the cache is shared through all gang members. However, in the pthread version of it, which assignment would have better locality? Does it depends on how OS schedule the threads context switch?
bschmuck
Does the term "gang" refer specifically to only the operations that are run in parallel using SIMD, or does it also refer to the tasks that we explicitly launch to multiple cores?
machine6
@bschmuck An ISPC task upon launching is performed by a single gang of instances. The gang instances themselves are executed by vector instructions.
Think of it this way, to run a gang, you need an execution context.
To run a launched ISPC task, we need an entire core.
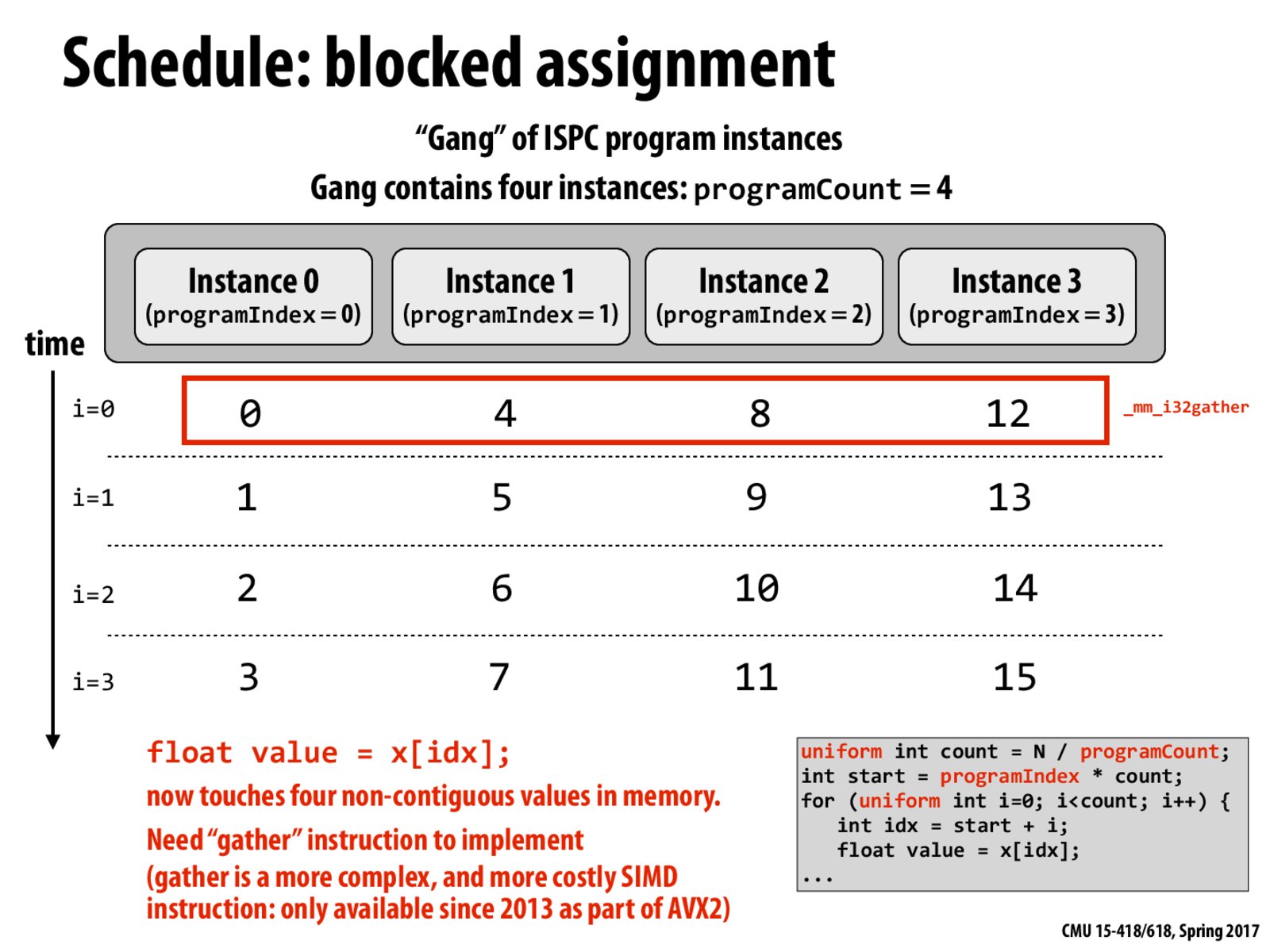
Before "gather" instructions were available, did this require 4 separate loads, one for each instance?
If we could execute this program on multiple cores, then I think this method would be the best? If one instance grabs the contiguous four elements, then on multiple cores it would have the whole cache line to itself and be more efficient than the interleaved instances as previous
I remember the prof said all instances are mapped to a single core. To run it on multiple cores, I think you have to use ISPC task?
Yes, this is the launch keyword that is covered in Assignment 1 from Program 3 onwards.
Blocked assignment with gather is more expensive, but sometimes the algorithm you implement requires using it.
What controls whether this us run on a single SIMD core or four indepentent cores? Is that handled by the OS or the ISPC interface? It seems like this scheme would work better (considering cache misses) in the case that it is run on multiple cores.
This version did not make good use of memory locality.
@yeq Just to qualify your response, it doesn't make use of spatial locality within the same time step although it still has good use of spatial locality across time. So, the inefficiency is also largely a result of having to access these different memory/cache locations at the same time step and the "gather" instruction that is mentioned on the slide.
@rrudolph I believe its the ISPC interface. Specifically if we use the launch keyword, the program runs on multiple cores asynchronously and possibly concurrently, while the traditional SPMD parallelism runs the gang on the same SIMD core utilizing vector instructions.
Conclusion from this discussion:
I remember Kayvon saying in class that in general, worker 0 in a gang generally uses vector lane 0 to run all it's load. Is this always true or was that the case just in this example?
Upon my first inspection, I thought this program would result in better use of the cache and spatial locality. However, it's actually the opposite. The program will instead cause a bunch of cache misses as the different instances overwrite the cache with the piece of the array it needs.
If you choose this kind of assignment, the ISPC compiler will throw a warning to you: [Performance Warning] ... It also works for storing values.
This reminds me another problem. In ISPC, the cache is shared through all gang members. However, in the pthread version of it, which assignment would have better locality? Does it depends on how OS schedule the threads context switch?
Does the term "gang" refer specifically to only the operations that are run in parallel using SIMD, or does it also refer to the tasks that we explicitly launch to multiple cores?
@bschmuck An ISPC task upon launching is performed by a single gang of instances. The gang instances themselves are executed by vector instructions.
Think of it this way, to run a gang, you need an execution context. To run a launched ISPC task, we need an entire core.