A distributed set of work queues means that there is less contention for top-level scheduling resources, than if we only had a single work queue. As long as the worker threads don't need to steal too much, this can often be more efficient in distributing work with low overhead.
Qiaoyu
Does that mean we will get some overhead on assigning subproblems to work queues? But this overhead is far less than the overhead caused by a single work queue locking?
nemo
Can we also consider a similar semi-static assignment where we create 2 work queues and assign 2 threads to each queue? The work assignment for 2 threads on the same queue will be completely dynamic. How can we compare the performance of these two schemes (one in the slide and the one I mentioned)?
cluo1
One drawback of distributed queues is that the worst case complexity to steal a work would be O(n) where n is the number of threads. That complexity results from randomly pick a queue to steal. This approach may be better when each thread works on their own queue and there is no sync cost.
boba
Having a work queue per thread decreases contention for locks but a thread may have to check multiple queues now to steal work.
SR_94
Can there ever be a scenario where stealing work from another thread's queue can lead to starvation of one of the threads?
For example, worker threads keep stealing work from one particular thread and that thread has no work to do?
sreevisp
@SR_94: Based on this slide, the situation you described should definitely be possible. I don't see what would be wrong with it though. If there was only one task left for two threads to complete, it doesn't really matter which thread does the work, as long as one of them does, and the other would have to remain idle in any case.
rrp123
In the case that one thread runs out of tasks to do and doesn't find any work in the first worker's queue it tries to steal from, does it keep going and try to steal work from other work queues? If so, isn't there a very large overhead involved with this?
sreevisp
@rrp123: I believe the idle thread would continue looking for work in other queues, and yes, you do incur more and more overhead by doing this. The alternative, however, is to simply sit idle while waiting for other threads to complete their tasks, which is not better. The way I understand it, we never really need to concern ourselves with overhead in this model since otherwise threads that finish early will simply do nothing.
Firephinx
@rrp123 In 210, we talked about work stealing, but instead of targeted work stealing, we talked about randomized work stealing. Kayvon touched on this briefly in class, but in the 210 notes on concurrency, it states that: "It has been proven that randomized work-stealing algorithm, where idle processors randomly select processors to steal from, deliver close to optimal schedules in expectation (in fact with high probability) and furthermore incur minimal friction. Randomized schedulers can also be implemented efficiently in practice." So in practice, if one thread runs out of tasks to do, it tries to steal work from a random other queue. If it fails to steal work from another thread's work queue, then it just waits until the next time step to try stealing again if work is still not put in its work queue instead of trying to steal work from another work queue after seeing that its first target's work queue is empty.
Levy
It is the way Golang schedule its goroutines: each goroutine is a task and each executors (by default the same number as CPU cores) keep their own queues. Goroutine will not yield context until block I/O or lock acquiring... It is different from pthreads which are scheduled fairly and switched on a time basis.
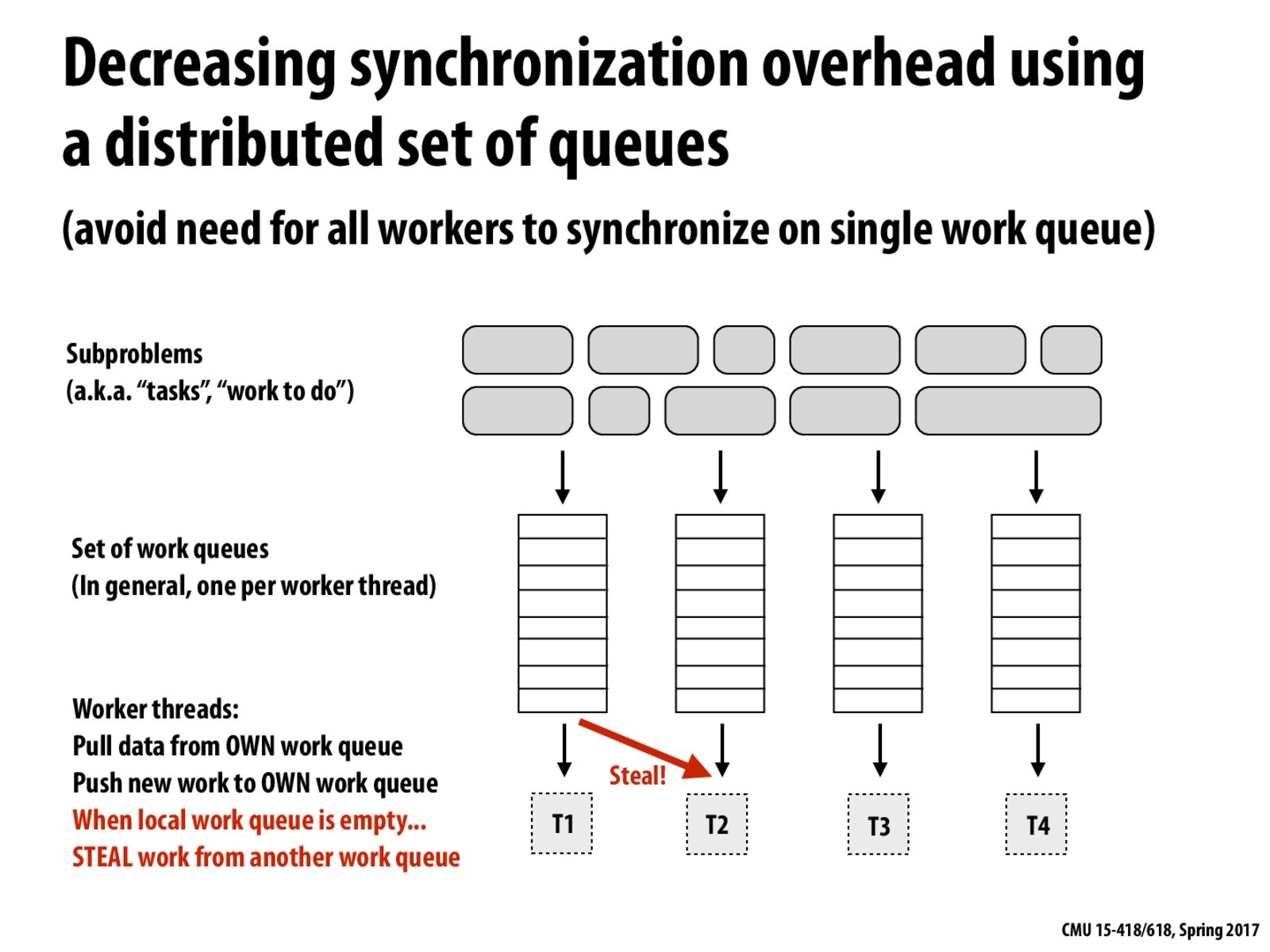
A distributed set of work queues means that there is less contention for top-level scheduling resources, than if we only had a single work queue. As long as the worker threads don't need to steal too much, this can often be more efficient in distributing work with low overhead.
Does that mean we will get some overhead on assigning subproblems to work queues? But this overhead is far less than the overhead caused by a single work queue locking?
Can we also consider a similar semi-static assignment where we create 2 work queues and assign 2 threads to each queue? The work assignment for 2 threads on the same queue will be completely dynamic. How can we compare the performance of these two schemes (one in the slide and the one I mentioned)?
One drawback of distributed queues is that the worst case complexity to steal a work would be O(n) where n is the number of threads. That complexity results from randomly pick a queue to steal. This approach may be better when each thread works on their own queue and there is no sync cost.
Having a work queue per thread decreases contention for locks but a thread may have to check multiple queues now to steal work.
Can there ever be a scenario where stealing work from another thread's queue can lead to starvation of one of the threads? For example, worker threads keep stealing work from one particular thread and that thread has no work to do?
@SR_94: Based on this slide, the situation you described should definitely be possible. I don't see what would be wrong with it though. If there was only one task left for two threads to complete, it doesn't really matter which thread does the work, as long as one of them does, and the other would have to remain idle in any case.
In the case that one thread runs out of tasks to do and doesn't find any work in the first worker's queue it tries to steal from, does it keep going and try to steal work from other work queues? If so, isn't there a very large overhead involved with this?
@rrp123: I believe the idle thread would continue looking for work in other queues, and yes, you do incur more and more overhead by doing this. The alternative, however, is to simply sit idle while waiting for other threads to complete their tasks, which is not better. The way I understand it, we never really need to concern ourselves with overhead in this model since otherwise threads that finish early will simply do nothing.
@rrp123 In 210, we talked about work stealing, but instead of targeted work stealing, we talked about randomized work stealing. Kayvon touched on this briefly in class, but in the 210 notes on concurrency, it states that: "It has been proven that randomized work-stealing algorithm, where idle processors randomly select processors to steal from, deliver close to optimal schedules in expectation (in fact with high probability) and furthermore incur minimal friction. Randomized schedulers can also be implemented efficiently in practice." So in practice, if one thread runs out of tasks to do, it tries to steal work from a random other queue. If it fails to steal work from another thread's work queue, then it just waits until the next time step to try stealing again if work is still not put in its work queue instead of trying to steal work from another work queue after seeing that its first target's work queue is empty.
It is the way Golang schedule its goroutines: each goroutine is a task and each executors (by default the same number as CPU cores) keep their own queues. Goroutine will not yield context until block I/O or lock acquiring... It is different from pthreads which are scheduled fairly and switched on a time basis.