In the previous slide, we introduce distributed set of queues in order to reduce the sync overhead. I am wondering, in such case, if it is possible that we have some tasks that have somewhat dependency but are distributed to separated queues. If so, will we need extra work to sync among different queues to resolve the dependencies?
Metalbird
@cwchang, logically, I feel as if you this would be something you would want to avoid. If you have a calculation that needs to complete before you can perform another calculation (one example of a data dependency), if you separate the work to different work queues, then you would end up needing to perform one calculation before the other one could be carried out on another work queue, which could require some syncing to ensure that the data is correct on the second queue, and that the second queue does not start before the first queue. I feel like in most situations, it would be more advantageous to carry out all data dependencies on the same queue, without needing extra synchronization, while carrying out independent tasks on another queue.
yulunt
Schedule tasks with dependency to the same cores reduces synchronization costs. However, it seems that only static scheduling is possible to do so. As for dynamic scheduling, it is hard to consider both processing time and dependency at the same time.
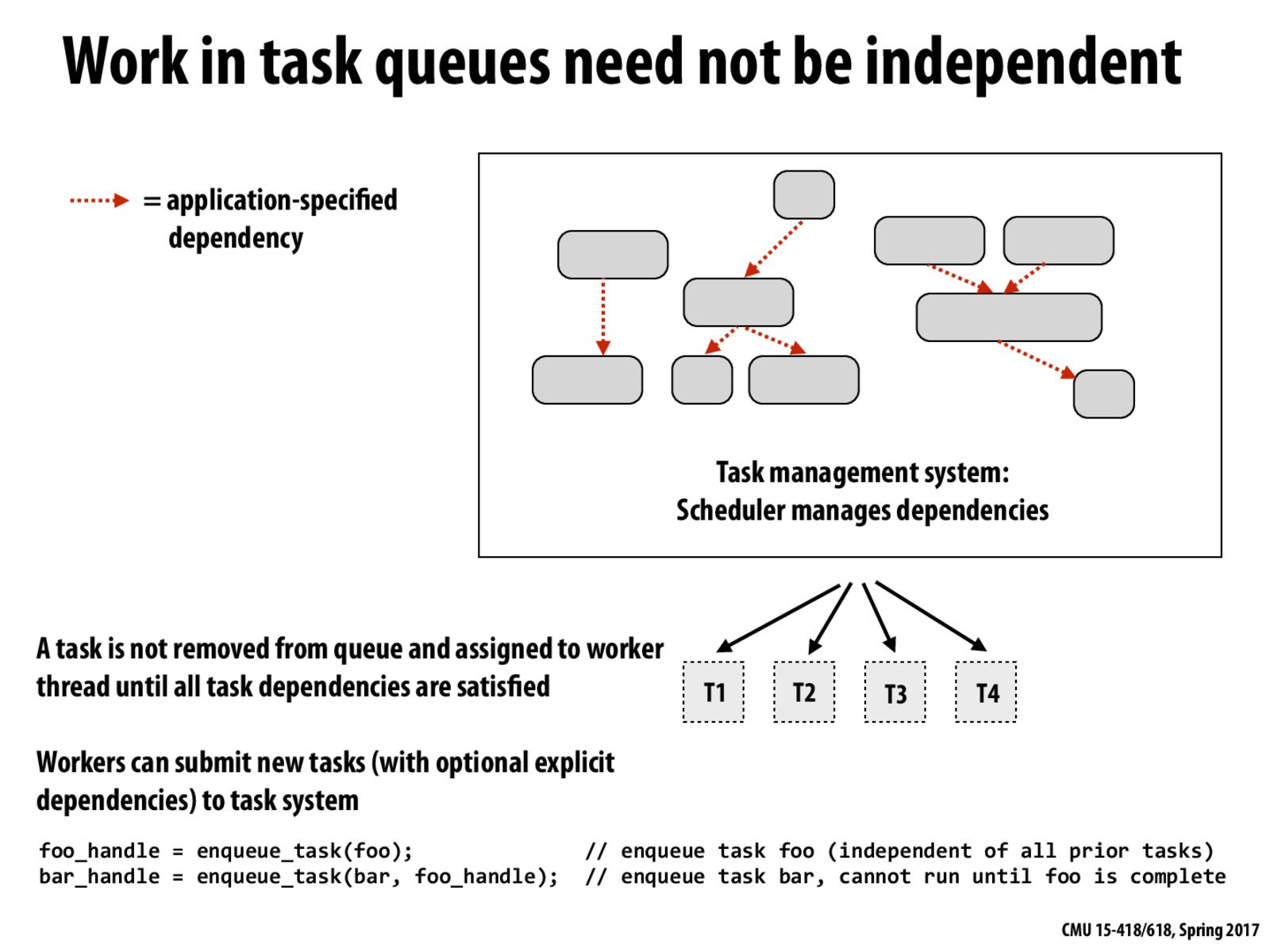
In the previous slide, we introduce distributed set of queues in order to reduce the sync overhead. I am wondering, in such case, if it is possible that we have some tasks that have somewhat dependency but are distributed to separated queues. If so, will we need extra work to sync among different queues to resolve the dependencies?
@cwchang, logically, I feel as if you this would be something you would want to avoid. If you have a calculation that needs to complete before you can perform another calculation (one example of a data dependency), if you separate the work to different work queues, then you would end up needing to perform one calculation before the other one could be carried out on another work queue, which could require some syncing to ensure that the data is correct on the second queue, and that the second queue does not start before the first queue. I feel like in most situations, it would be more advantageous to carry out all data dependencies on the same queue, without needing extra synchronization, while carrying out independent tasks on another queue.
Schedule tasks with dependency to the same cores reduces synchronization costs. However, it seems that only static scheduling is possible to do so. As for dynamic scheduling, it is hard to consider both processing time and dependency at the same time.