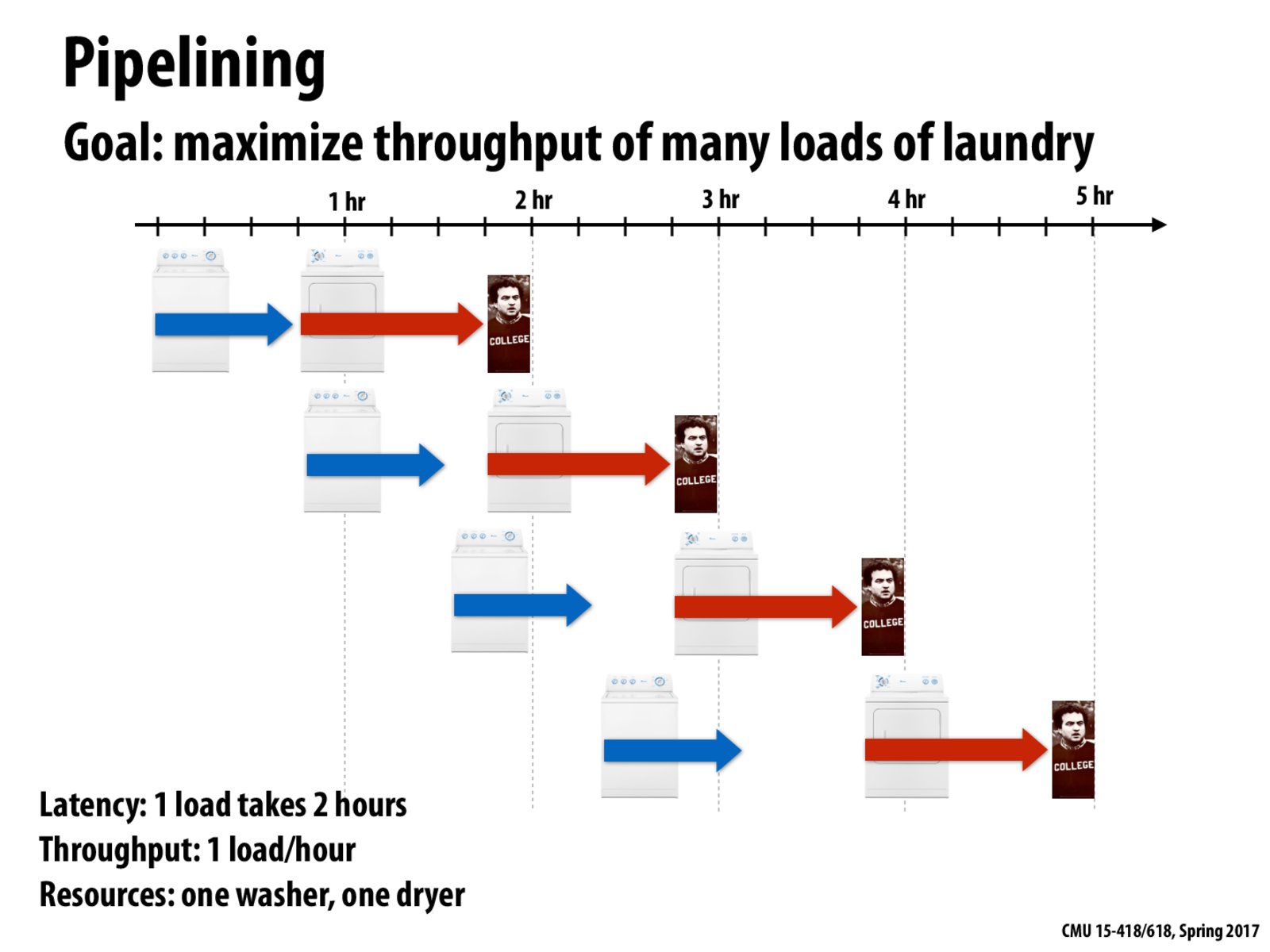
How is the throughput calculated? I can only see 4 loads in 5 hours
dyzz
Try drawing this out further until you reach a sort of "steady state" to convince yourself. I believe when we talk about 1 load per hour we are talking specifically about the steady state. The true throughput including "start up cost" would be slightly lower.
thunder
In this slide, Professor Kayvon mentioned that the throughput of a system will be the smallest throughput in the whole pipeline. And thus, we can look at the end of a pipeline to calculate the actual throughput.
BestBunny
Adding on to @dyzz and @thunder, to calculate the throughput from the above diagram look at the timeline starting at the "2 hr" mark. Then for the entire time after this point, there is one load completed for every one hour making the throughput 1 load/hr.
apadwekar
This case is analogous to us allowing more cars on the road at the same time. In that case, we also don't consider the time it takes for the first car to reach Pittsburgh. Throughput is calculated as if the pipeline had already been active.
kayvonf
Yes, when we talk about throughput we usually consider the steady-state throughput of a large operation, and therefore is it valid to ignore the cost of any startup latencies. If this diagram was extended out to hundreds of loads of laundry, you'd see one load finishing each hour. Therefore, the throughput is one load per hour.
But startup effects ("filling the pipeline") or end of operation effects ("draining the pipeline") to can be very important when operations are not long enough to ignore them.
shhhh
Would it be ok to reason with the throughput as 1 load per longest time to complete a portion of the task? Since the 45 min was and 15 min dry are completed faster and the laundry process ends up waiting for the dryer.
koala
Is the throughput defined as independent of the number of total tasks needed to complete (and thus ignoring startup latencies)? Or can it also be defined as total time / # of tasks completed? In the first case, we would have 1 load / hour throughput. In the second case, we would have 4 load / 5 hour throughput.
paramecinm
@koala As discussed before, it depends. If you have enough operations, the start and end time can be ignored so your two calculation methods will get very close numbers so the first method will be easier to calculate. If you only have few operations, the start and end time cannot be ignored. So you should use the second method.
paracon
The slide also depicts the issues that rise when each pipeline stage takes a different amount of time to complete. In an instruction pipeline, there are hardware level optimisations that are used to overcome the delays and reduce stalls.
How is the throughput calculated? I can only see 4 loads in 5 hours
Try drawing this out further until you reach a sort of "steady state" to convince yourself. I believe when we talk about 1 load per hour we are talking specifically about the steady state. The true throughput including "start up cost" would be slightly lower.
In this slide, Professor Kayvon mentioned that the throughput of a system will be the smallest throughput in the whole pipeline. And thus, we can look at the end of a pipeline to calculate the actual throughput.
Adding on to @dyzz and @thunder, to calculate the throughput from the above diagram look at the timeline starting at the "2 hr" mark. Then for the entire time after this point, there is one load completed for every one hour making the throughput 1 load/hr.
This case is analogous to us allowing more cars on the road at the same time. In that case, we also don't consider the time it takes for the first car to reach Pittsburgh. Throughput is calculated as if the pipeline had already been active.
Yes, when we talk about throughput we usually consider the steady-state throughput of a large operation, and therefore is it valid to ignore the cost of any startup latencies. If this diagram was extended out to hundreds of loads of laundry, you'd see one load finishing each hour. Therefore, the throughput is one load per hour.
But startup effects ("filling the pipeline") or end of operation effects ("draining the pipeline") to can be very important when operations are not long enough to ignore them.
Would it be ok to reason with the throughput as 1 load per longest time to complete a portion of the task? Since the 45 min was and 15 min dry are completed faster and the laundry process ends up waiting for the dryer.
Is the throughput defined as independent of the number of total tasks needed to complete (and thus ignoring startup latencies)? Or can it also be defined as total time / # of tasks completed? In the first case, we would have 1 load / hour throughput. In the second case, we would have 4 load / 5 hour throughput.
@koala As discussed before, it depends. If you have enough operations, the start and end time can be ignored so your two calculation methods will get very close numbers so the first method will be easier to calculate. If you only have few operations, the start and end time cannot be ignored. So you should use the second method.
The slide also depicts the issues that rise when each pipeline stage takes a different amount of time to complete. In an instruction pipeline, there are hardware level optimisations that are used to overcome the delays and reduce stalls.