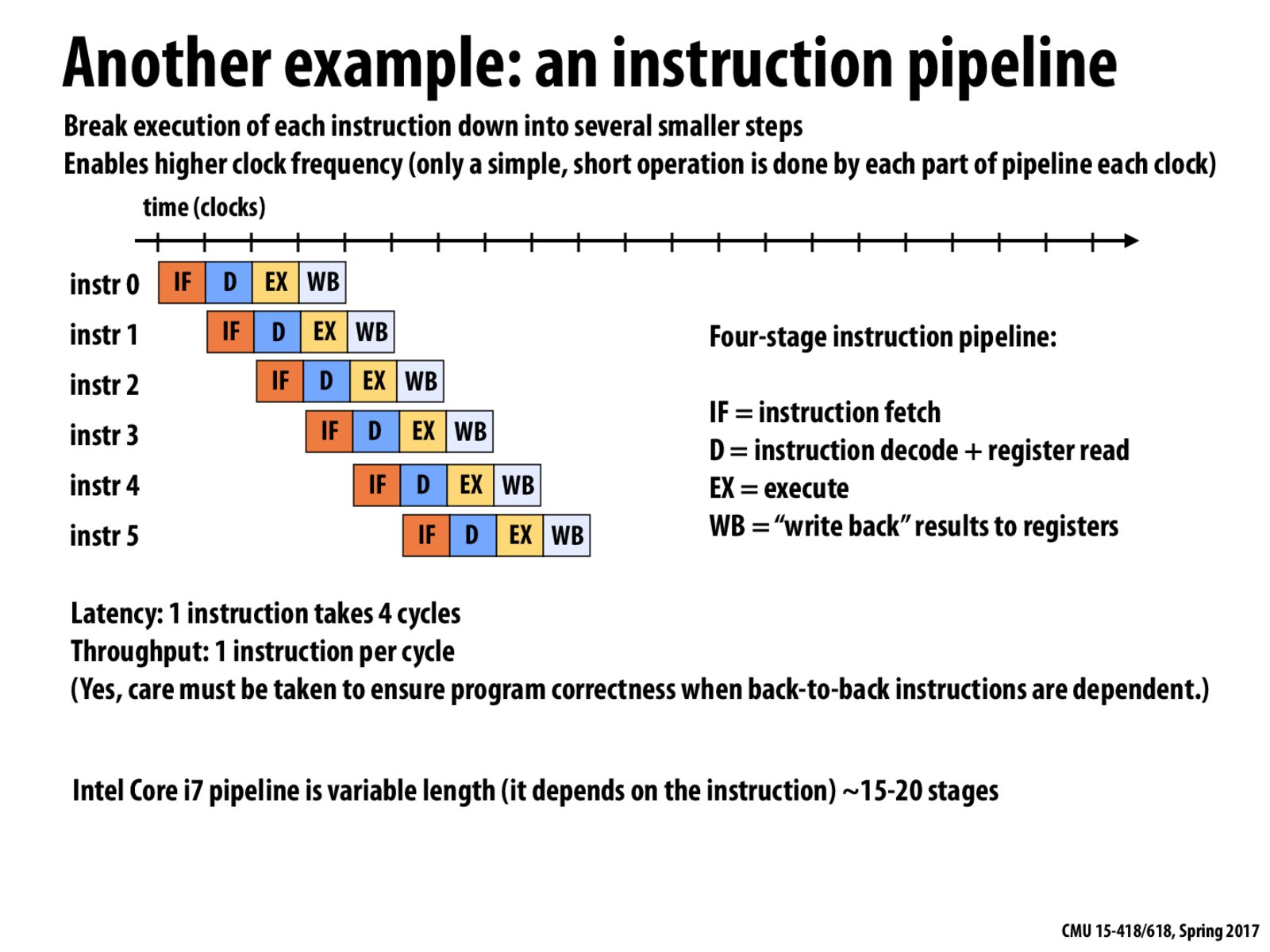
The throughput gain of pipelining will be bound by the slowest execution unit. Speed up other fast execution unit doesn't help with latency or throughput.
BestBunny
Although each individual instruction takes 4 cycles, the throughput is 1 instruction per cycle thanks to pipelining. Starting at the 4th clock cycle (completion of the first instruction), there is an instruction completed for every clock cycle after which is how we calculate throughput.
rrudolph
If instruction 2 is dependent on instruction 1, it cannot begin it's IF step until until instruction 1 has written back its result into the registers.
cwchang
One question here. Say we have two instruction A and B. With pipeline, the first action is A's IF. However, from the figure, the second action seems to be A's D and B's IF "at the same time". I'm wondering how this can be done? Does that mean the processor can execute multiple "sub-instruction (IF, D, EX, WB)" concurrently (or simultaneously)?
rrudolph
@cwchang I believe the each of these stages (Instruction Fetch, Decode, Execute, Write Back) are done by their own dedicated hardware in the processor. So looking from the high level, all of these stages are being run (on different instructions) at the same time. But from the low level, each stage is implemented as a separate piece of hardware that sits along the pipeline, and the instructions go through each piece in order.
pht
According to https://cs.stanford.edu/people/eroberts/courses/soco/projects/2000-01/risc/pipelining/index.html and many other sources, there are five stages to each instruction:
1. Fetch instructions from memory
2. Read registers and decode the instruction
3. Execute the instruction or calculate an address
4. Access an operand in data memory
5. Write the result into a register
Is there a reason why we're only working with 4 stages in this example? The above fourth step is omitted from the slide above.
jk2d
@rrudolph I agree. This means the throughput is 1/4 instruction per cycle when back-to-back instructions are dependent.
whitelez
@pht I think the reason we are only working with 4 stages in this example is to only focus on the pipeline of the instructions. Accessing the data memory would be the topic of how to hiding the latency.
lfragago
This instruction pipeline is what appears in Exercise 2.
Summarizing all ideas mentioned:
The throughput is 1 instruction per cycle in the best case (no dependencies)
The throughput is 1 instruction every four cycles (or 0.25 instructions per cycle) in case of complete instruction dependencies.
Even if one stage of the instruction pipeline supported simultaneous execution (say two EX stages per cycle for different instructions) the throughput does not change. As mentioned in class throughput is bounded by the slowest unit in the execution pipeline.
rrp123
@lfragago What if instead of starting one instruction at time 0, we started 2 instructions, assuming that the processor was capable of doing this, and at every time step after, we would continue starting 2 instructions. Wouldn't this mean that the throughput is 2, since after time 4, there will always be 2 WB instructions happening in parallel.
paracon
@rrp123 The throughput will be 2 if you have 1) Enough instruction level parallelism in the program/system, and also 2) Hardware units to fetch, decode, execute, and write back two independent instructions in every cycle. Throughput will be 2 if after every cycle from time 4, 2 instructions finish executing.
kapalani
Data dependencies could mean, we can't execute some stages of the pipeline until the previous write back is complete. In this case, the processor will stall or insert bubbles(NOPS) into the pipeline to ensure the data dependencies are met. Another technique that processors use is called data forwarding where the earlier stages of the pipeline have access to the intermediate results from the execute stage and so can avoid stalling and can use the updated values for the registers before the write back stage
sadkins
In this example, all the instructions can be pipelined in this way because they are all independent of each other. In reality, it is unlikely that 6 consecutive instructions will all be independent. If an instruction is dependent on the previous one, it will not begin until the write back stage of the previous instruction has completed
The throughput gain of pipelining will be bound by the slowest execution unit. Speed up other fast execution unit doesn't help with latency or throughput.
Although each individual instruction takes 4 cycles, the throughput is 1 instruction per cycle thanks to pipelining. Starting at the 4th clock cycle (completion of the first instruction), there is an instruction completed for every clock cycle after which is how we calculate throughput.
If instruction 2 is dependent on instruction 1, it cannot begin it's IF step until until instruction 1 has written back its result into the registers.
One question here. Say we have two instruction A and B. With pipeline, the first action is A's IF. However, from the figure, the second action seems to be A's D and B's IF "at the same time". I'm wondering how this can be done? Does that mean the processor can execute multiple "sub-instruction (IF, D, EX, WB)" concurrently (or simultaneously)?
@cwchang I believe the each of these stages (Instruction Fetch, Decode, Execute, Write Back) are done by their own dedicated hardware in the processor. So looking from the high level, all of these stages are being run (on different instructions) at the same time. But from the low level, each stage is implemented as a separate piece of hardware that sits along the pipeline, and the instructions go through each piece in order.
According to https://cs.stanford.edu/people/eroberts/courses/soco/projects/2000-01/risc/pipelining/index.html and many other sources, there are five stages to each instruction: 1. Fetch instructions from memory 2. Read registers and decode the instruction 3. Execute the instruction or calculate an address 4. Access an operand in data memory 5. Write the result into a register
Is there a reason why we're only working with 4 stages in this example? The above fourth step is omitted from the slide above.
@rrudolph I agree. This means the throughput is 1/4 instruction per cycle when back-to-back instructions are dependent.
@pht I think the reason we are only working with 4 stages in this example is to only focus on the pipeline of the instructions. Accessing the data memory would be the topic of how to hiding the latency.
This instruction pipeline is what appears in Exercise 2. Summarizing all ideas mentioned:
@lfragago What if instead of starting one instruction at time 0, we started 2 instructions, assuming that the processor was capable of doing this, and at every time step after, we would continue starting 2 instructions. Wouldn't this mean that the throughput is 2, since after time 4, there will always be 2 WB instructions happening in parallel.
@rrp123 The throughput will be 2 if you have 1) Enough instruction level parallelism in the program/system, and also 2) Hardware units to fetch, decode, execute, and write back two independent instructions in every cycle. Throughput will be 2 if after every cycle from time 4, 2 instructions finish executing.
Data dependencies could mean, we can't execute some stages of the pipeline until the previous write back is complete. In this case, the processor will stall or insert bubbles(NOPS) into the pipeline to ensure the data dependencies are met. Another technique that processors use is called data forwarding where the earlier stages of the pipeline have access to the intermediate results from the execute stage and so can avoid stalling and can use the updated values for the registers before the write back stage
In this example, all the instructions can be pipelined in this way because they are all independent of each other. In reality, it is unlikely that 6 consecutive instructions will all be independent. If an instruction is dependent on the previous one, it will not begin until the write back stage of the previous instruction has completed