Motivations
Your goal as a parallel programmer is to fully leverage every available resource. If any part of the CPU or GPU spends time waiting for the rest of your program to catch up, then the computer is not performing to its full potential.
Pipelines come into play when you have a process that you need to do multiple times. In class we discussed the simple example of a college student doing several loads of laundry with only one washer and dryer. The naive way to do two loads is to wash, dry, and fold the first before beginning to wash the second. That's a terrible idea, unless your goal is to hang out in the laundry room for a long time. The washer is sitting there empty while your first load is drying and your second load is sitting in some heap off to the side. The better approach is to wash the second load while the first is in the dryer. This approach minimizes your idling resources, which maximizes throughput. Additionally, instead of unloading your clothes from the washer into a pile to wait for the dryer, you can transfer your clothes directly from the washer to the dryer.
Pipelining
Pipelining is running multiple stages of the same process in parallel in a way that efficiently uses all the available hardware while respecting the dependencies of each stage upon the previous stages. In the laundry example, the stages are washing, drying, and folding. By starting a wash stage as soon as the previous wash stage is moved to the dryer, the idle time of the washer is minimized. Notice that the wash stage takes less time than the dry stage, so the wash stage must remain idle until the dry stage finishes: the steady state throughput of the pipeline is limited by the slowest stage in the pipeline. This can be mitigated by breaking up the bottleneck stage into smaller sub-stages. For those less concerned with laundry-based examples, consider a video game. The CPU computes the keyboard/mouse input each frame and moves the camera accordingly, then the GPU takes that information and actually renders the scene; meanwhile, the CPU has already begun calculating what's going to happen in the next frame.
The benefit of pipelining is to increase throughput without actually decreasing latency. As a reminder of those terms, their definitions are below.
Latency is the time to complete a single task.
Throughput is the rate at which tasks complete.
At first, the idea of increasing throughput despite no change in latency may appear unintuitive, but we actually experience this all the time. Consider that despite you taking 4 years to get through high school, your high school graduated a full class of students each year. That's because they're teaching freshman through seniors at the same time. Imagine if high schools did not implement pipelining. You would have one class of students with enough teachers for all four grades, but teachers who only teach 1 out of every 4 years!
Instruction Pipelining
In class, we mentioned that interpreting each computer instruction is a four step process: fetching the instruction, decoding it and reading the register, executing it, and recording the results. Each instruction may take 4 cycles to complete, but if our throughput is one instruction each cycle, then we would like to perform, on average, $n$ instructions every $n$ cycles. To accomplish this, we can split up an instruction's work into the 4 different steps so that other pieces of hardware work to decode, execute, and record results while the CPU performs the fetch. The latency to process each instruction is fixed at 4 cycles, so by processing a new instruction every cycle, after four cycles, one instruction has been completed and three are "in progress" (they're in the pipeline). After many cycles the steady state throughput approaches one completed instruction every cycle.
Obligatory Car Analogy
An assembly line in a auto manufacturing plant is another good example of a pipelined process. There are many steps in the assembly of the car, each of which is assigned a stage in the pipeline. Typically the depth of these pipelines is very large: cars are pretty complex, so there need to be a lot of stages in the assembly line. The more stages, the longer it takes to crank the system up to a steady state. The larger the depth, the more costly it is to turn the system around: A branch misprediction in an instruction pipeline would be like getting one of the steps wrong in the assembly line: all the cars affected would have to go back to the beginning of the assembly line and be processed again.
Real World Example: OnLive
OnLive is a company that allows gamers to play video games in the cloud. The games are run on one of the company's server farms, and video of the game is sent back to your computer. The idea is that even the lamest of computers can run the most highly intensive games because all the crappy computer does is send your joystick input over the internet and display the frames it gets back.
Of course, no one wants to play a game with a noticeably low framerate. We're going to demonstrate how OnLive could deliver a reasonable experience. For our purposes, we'll assume that OnLive uses a four step process: the user's computer sends over the input to the server (10ms), the server tells the game about the user's input and then compresses the resulting game frame (15ms), the compressed video is sent back to the user (60ms) where it is then decompressed and displayed (15ms). Note that OnLive doesn't share its data, so these numbers are contrived.
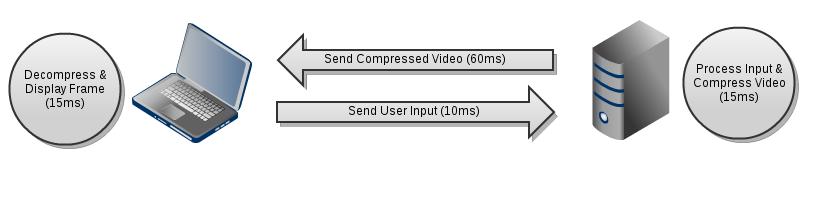
The latency of this process is 100ms (10+15+60+15). This means that there will always be a tenth of a second lag from when you perform an action to when you see it affect things on the screen.
Now we wish to calculate throughput. Throughput in this case represents the frames per second that you see on the screen (as that is the number of completed tasks per second). Let's assume that the server is playing the game at 60 frames per second. Because the amount of input the user gives is small, we can assume that the user's computer is also able to send input 60 times per second. Therefore, the server is going to get new input every frame. The server then sends over 60 images a second and the user's computer attempts to decompress them and display them at a full 60 per second.
Therefore, the user will experience 60 frames per second gameplay despite a 100ms lag.
Of course, we are bandwidth limited and will not likely experience 60 fps, maybe it's only possible to send 30 frames every second. The server may process a new frame before the last one was able to be sent, in which case it may opt to skip over the older frame and send the newer one.
This problem of communication being slower than the rest of the program leads us to our next topic, pipelined communication.
Pipelined Communication
Communication between different parts of a machine is not particularly easy to manage since often it only occurs in burst situations - that is a huge demand on the communication framework followed by a period of very little activity. Communication can be sped up by pipelining however. We do not necessarily have to wait for a message to be delivered before we send another piece of information. Therefore we can set up a level of pipelining. Often, however, the rate at which we can send messages is much faster than the time it takes data to go through the slowest part of our system. Therefore, pipelining only helps to an extent because in the long run our communication is limited by the slowest part of our system - call this occupancy.
This is directly related to the bandwidth, which is proportional to 1/occupancy. However, we have already stated that communication often only occurs in burst. Therefore, this pipelining can help tremendously for short periods of time.
If this pipelining isn't sufficient, it is actually possible to further increase our communication bandwidth over short periods of time (which is all that really matters in burst situations). We can do this through the use of buffers which allows us to send messages for longer periods of time at speeds greater than 1/occupancy. The reason this works is because we can buffer messages and continue to send them even when the bandwidth is maximized.
The step of executing instruction could be further divided into alu operation and memory read operation since they have different latency and different nature.
This comment was marked helpful 0 times.