Pool of just two "worker" warps won't be a good choice as it won't provide any latency hiding capability.
This comment was marked helpful 0 times.
kayvonf
Correct Mayank. The GPU maintains execution context state for a far greater number of warps, and interleaves warp execution to hide warp stalls (The concept of hardware multi-threading was introduced in Lecture 2).
Question: Just to finish off the idea: How many warps can run concurrently on a GTX 480 GPU core? What about a GTX 680 GPU core?
This comment was marked helpful 0 times.
sjoyner
I'm not completely sure about this, but I think for a GTX 480 GPU 16 warps can run concurrently because there are only 16 ALUs. However since the ALUs run twice as fast as the rest of the chip, it looks like 32 warps can run concurrently.
This comment was marked helpful 0 times.
lazyplus
GTX 480 GPU is Fermi architecture while GTX 680 is Kepler. Based on the NVIDIA white paper about GTX 680, every single core in GTX 480 can run 2 warps simultaneously and every single core in GTX 680 can run 4 warps (check the item "Warp schedulers" in the sheet).
The white paper also said this about GTX 680:
To feed the execution resources of SMX, each unit contains
four warp schedulers, and each warp scheduler is capable
of dispatching two instructions per warp every clock.
So, on GTX 680, there would be at most 8 instructions in total be executed in every clock.
This comment was marked helpful 0 times.
kayvonf
@sjoyner and @lazyplus: Please see the discussions on slide 43 and slide 52 for more details of how CUDA programs are executed on modern GPUs.
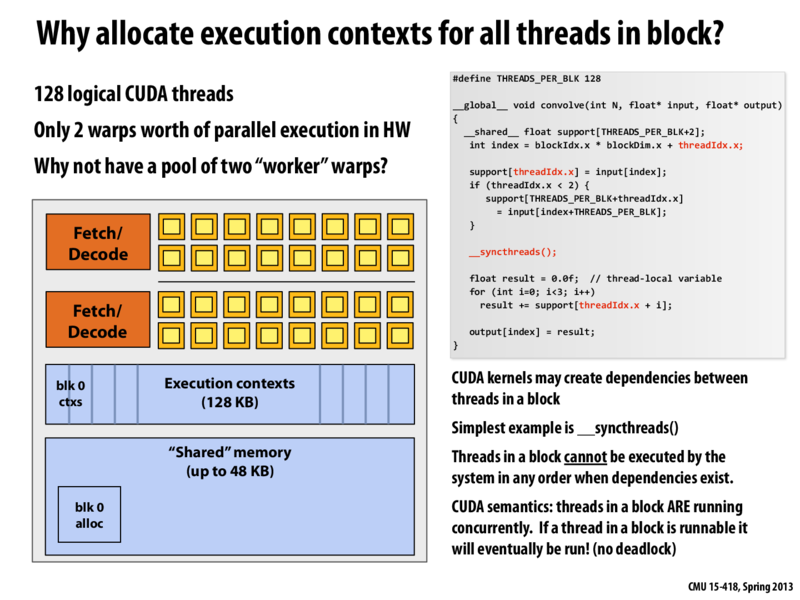
Pool of just two "worker" warps won't be a good choice as it won't provide any latency hiding capability.
This comment was marked helpful 0 times.
Correct Mayank. The GPU maintains execution context state for a far greater number of warps, and interleaves warp execution to hide warp stalls (The concept of hardware multi-threading was introduced in Lecture 2).
Question: Just to finish off the idea: How many warps can run concurrently on a GTX 480 GPU core? What about a GTX 680 GPU core?
This comment was marked helpful 0 times.
I'm not completely sure about this, but I think for a GTX 480 GPU 16 warps can run concurrently because there are only 16 ALUs. However since the ALUs run twice as fast as the rest of the chip, it looks like 32 warps can run concurrently.
This comment was marked helpful 0 times.
GTX 480 GPU is Fermi architecture while GTX 680 is Kepler. Based on the NVIDIA white paper about GTX 680, every single core in GTX 480 can run 2 warps simultaneously and every single core in GTX 680 can run 4 warps (check the item "Warp schedulers" in the sheet).
The white paper also said this about GTX 680:
So, on GTX 680, there would be at most 8 instructions in total be executed in every clock.
This comment was marked helpful 0 times.
@sjoyner and @lazyplus: Please see the discussions on slide 43 and slide 52 for more details of how CUDA programs are executed on modern GPUs.
This comment was marked helpful 0 times.