



According to original Amdahl's law, it indicates that the speedup of using multi-core is limited by the time of execution of sequential fraction of program (1-f).
This comment was marked helpful 0 times.


There is an r in the numerator in the bottom-right term because we need to divide f by the number of cores, which is n/r
This comment was marked helpful 1 times.

Here, n/r is the number of cores instead of n in the previous page.
This comment was marked helpful 0 times.


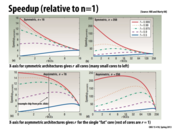
The red line (highly parallelizable workload) has decreasing speedup as you have fewer, bigger cores since they can't utilize the parallelism as much anymore since $perf(r)$ is modeled as $\sqrt{r}$. Originally we utilized all 16 cores ($n = 1$ per core) with $perf(1) = \sqrt{1} = 1$ unit of processing power each, but in the end we only use a single core ($n = 16$ per core) with $perf(16) = \sqrt{16} = 4$ units of processing power.
This comment was marked helpful 1 times.

Question What does rBCE stand for? It took me a while of looking at these graphs to realize that # of cores did not increase along the x-axis; instead it decreases.
(And for some reason the text below the graph didn't help me. Maybe a graph with the x-axis flipped is more intuitive or similar to what we've seen so far?)
This comment was marked helpful 0 times.

BCE stands for "base core equivalents". That is, a core requiring r BCEs consumes r times the resources (think: transistors) as the experiment's "baseline" performance 1 core.
In each graph the total number of resources (in units of BCEs) is fixed at N. The x axis varies the size of the processor's cores, so a processor with cores each of size r has a total of N/r cores.
Varying the size of the cores trades off peak parallel performance for better sequential performance, and the curves on the graphs show how a specific workload's performance changes as this tradeoff is made.
These graphs are from the paper Amdahl's Law in the Multi-Core Era by Mark Hill (Univ. of Wisconsin) and Michael R. Marty (Google). It's definitely worth a read.
They also have a neat heterogeneous Amdahl's Law calculator and further slides about the paper here.
It may be also be helpful to see my explanation of the graphs on slide 6.
This comment was marked helpful 0 times.

This seems to assume that perf(1) = 1. Is this always the case (or only because we are modelling it as a sqrt)? I would think it has to be, so that the previous formula reduces to the amdahl case. How does the above formula change if the 12 cores have a different r?
This comment was marked helpful 0 times.

Here the speedup seems better because we make use of sqrt(r) + n - r cores in average for the parallel part instead of n/sqrt(r) cores.
This comment was marked helpful 0 times.
@xiaoend: I think you may have misinterpretted the graphs. Let me try:
Assume there are a fixed amount of resources (think: transistors) an architect can use to build a chip (this is given by the variable N). In the left column: N=16. In the right column, N=256 (a bigger chip).
The top row of graphs shows how performance for different workloads (one workload per curve) varies when the N resources are used to make N/r homogeneous cores of 'r' resources each. These cores have sequential performance $sqrt(r)$ In the graphs, the X-axis is r. Notice how the parallel workload runs fastest when the chip consists of many cores (and thus provided maximum throughput). The workloads with more sequential components run better when the chip uses larger cores to provided higher sequential performance.
The bottom row of graphs show how performance for different workloads changes if the N resources are partitioned into one "fat" core containing r resources (performance $sqrt(r)$) and N-r "tiny" cores of performance 1.
In the N=16 case, the heterogeneous solution that uses a single fat core of size r=4to r=8, is able to provide highest overall performance across the workloads. In the N=256 case, we seem to be best off build a fat core where r=64 to r=128.
This comment was marked helpful 0 times.
@kayvonf: You are right.
I intended to say why the bottom row of graphs have better speedup with various number of cores than top ones.
And one advantage of asymmetric architectures is that they can guarantee the average performance is (sqrt(r)+n-r) which is better than n/sqrt(r) for symmetric architectures.
And the performances of sequential part remain same.
"One big core" can do sequential part quickly while the small cores can do parallel part faster.
This comment was marked helpful 1 times.


Most applications will have parts that are either strictly sequential or difficult or inefficient to parallelize, and also parts that greatly benefit from parallelization. The logical way to handle this is to have different hardware to handle both cases. We can utilize one powerful piece of hardware that can do things sequentially for the sequential part, and many less powerful pieces of hardware to parallelize the parallelizable components. For the same expense (as in, cost of the chip), we could get a few powerful cores, but this would make the parallel portion of our application slower. We could get many, many less powerful cores, but this would make the sequential portion of our application slower. Thus heterogeneous hardware is the better solution. The catch is that each application will have an "optimum hardware," and this will be different for every application. So, you need to find something that will work well for most applications you will be using, which can be difficult.
This comment was marked helpful 0 times.
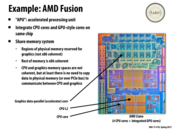

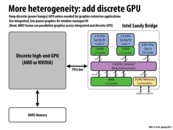
The PS4 is taking this route. It's main processor consists of an 8 core x86-64 CPU paired with a 1.8 tflop GPU all on the same chip sharing 8 GB of GDDR5.
http://www.scei.co.jp/corporate/release/pdf/130221a_e.pdf
This comment was marked helpful 1 times.


It was shut down a week or so ago because it's too energy inefficient:
This comment was marked helpful 0 times.

Question: Who demands supercomputers other than the scientific community? A few days ago, this question came to my mind. We always want better performance and better performance comes with costs. In most cases in daily life, we do not demand these much computing power at this speed. So, is there any other uses for supercomputers other than for the scientific community?
This comment was marked helpful 0 times.

@Fangyihua: There may be some companies that use them for various things but a lot of it comes from national pride, many countries(and states for that matter) put money into them so they can brag, saying things like "We had to build a supercomputer that does X petaflops because of all the interesting things our universities/scientists are doing!".
Here is an interesting story that goes along with this from when I was at Ohio State. So Ohio State has access to the Ohio Supercomputing Center (OSC) in much the same way CMU can access PSC/blacklight, there was some major revamp that was needed(probably costing a few million dollars) and after some convincing someone got a big wig (not the governor but close) to speak on the OSC's behalf on a budget meeting. Eventually OSC got a good chunk of change and once the revamps were finished the official that spoke on our behalf came to visit. I suppose he really had no idea what a supercomputer looked like because he left feeling completely underwhelmed because he expected something a lot more than a room of server blades and made some comment like "If I knew it would look so boring I wouldn't have helped" and I believe he was planning on using it as a thing to show important people when they needed to see something cool Columbus had to offer.
This comment was marked helpful 0 times.
And also tagging onto what @sfackler said, I went to IEEE HOT Interconnects conference in 2011 and one of the speakers from Intel made a pretty good argument semi-against how we were shooting towards exoscale computing at the time. He mentioned that even taking into account how much more power efficient we are becoming every year, it is entirely likely that a real exoscale supercomputer would need its own power plant unless some serious ground was covered in making CPU/GPU's and other components consume less power.
This comment was marked helpful 0 times.





As we can see from the graph, the execution cost is only 6%, which suggests that if we have a lot of tasks with relatively less execution cost, it is better to assign these jobs to either GPU or ASIC to save power and maximize throughput. On the other hand, if we have really complex serial task we can assign this kind of task to CPU to minimize latency.
This comment was marked helpful 0 times.

Since GPU have more arithmetic logic than control and instruction supply unit, running an instruction on GPU would be more cost effective if the same instruction can run on multiple data.
This comment was marked helpful 0 times.
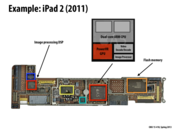

The iPad has a lot more components than say, a Macbook, because these smaller processors are specialized to handle normally CPU-heavy tasks, such as playing videos. Hardware specialization is especially important for mobile devices like these because for such tasks we don't want to be running the CPU at 100% capacity because it will drain the power too quickly.
Side note, the image processing DSP handles touch screen events (and the image processor on the main chip handles the camera).
This comment was marked helpful 1 times.

To add onto @stephyeung, hardware specialization allows for minimal power usage. This is crucial for iPad like devices to promote battery life. Additionally, preprocessing also allows for saving on bandwidth.
This comment was marked helpful 1 times.

As pointed out in the second exam, there are APIs available that decode video and audio using the chips outlined above, instead of having to do it in software. I dug around for a couple minutes and found https://developer.apple.com/library/mac/#documentation/AudioVideo/Conceptual/AVFoundationPG/Articles/00_Introduction.html. Apparently that does use special chips on iOS devices.
This comment was marked helpful 0 times.

As pointed out in class, the image processing DSP on the left is used to answer screen touch. Since it is dedicated to do this task, iPad can provide very smooth experience to users.
This comment was marked helpful 0 times.

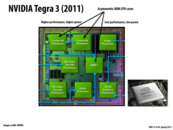

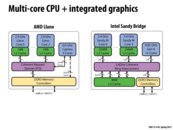
The chip contains high-performance Cortex-A9 CPUs and a low-performance ARM 7 CPU. The idea is that when you are not doing CPU-intensive tasks only the ARM 7 processor will be active and the Cortex-A9s will be powered down. The benefit of this design is you get better battery life since you aren't using as much power when the chip is idle and you still have powerful CPUs available if you need them.
This comment was marked helpful 0 times.
Question: Is that diagram actually of a Tegra 2 chip?
From what I was reading Tegra 2 has 2 high-performance A9s cores and a low-performance ARM 7 core whereas Tegra 3 has 4 high-performance A9s and 1 low-performance A9 that it uses when CPU load is low.
This comment was marked helpful 0 times.

@nkindberg Doing some quick searching, I do believe that is a Tegra 2 chip, and it matches your description.
Also, there are specifications for the Tegra 4 chip available. It has a similar 4+1 CPU organization as the Tegra 3 described above, and also 72 GPU cores, and architecture specialized for computational photography (efficient image processing).
This comment was marked helpful 0 times.
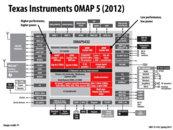

Would it be a possibility for future, energy efficient, general purpose home computers could also have specialized processors for specific tasks?
This comment was marked helpful 0 times.
They already do! Most modern CPUs have special purpose logic for audio/video playback, data compression, 3D graphics, etc. However, the degree of specialization beyond these widely used tasks is less than in mobile systems since the main CPU is certainly powerful enough to handle most jobs.
This comment was marked helpful 0 times.

I was curious how much of a power difference there actually is in playing HTML5 vs Flash video so I did a test on my BlackBerry Z10 which has built-in Adobe Flash support. Playing a YouTube video (HTML5) resulted in a power draw of 1.10w. Playing a Flash video that used FLV format resulted in a power draw of 1.12w. Playing a Flash video that used M4V format resulted in a power draw of 1.09w. So it seems like Adobe has now found a way to make Flash decoding not drain the battery like crazy even when using the old FLV format.
This comment was marked helpful 0 times.


In class Kayvon showed us how quickly his camera can take photos in succession, and how the rate slowed as the memory on the camera filled. The fixed-function chip on his camera is very quick at handling RAW -> JPEG conversion. He then did a similar conversion on his Macbook and showed that it takes about 8 to 12x longer to convert an image using a general purpose CPU.
This comment was marked helpful 0 times.
I'd like to clarify that my experiment was largely for demonstration purposes. I don't know if the comparison was fair because I don't know if the software on my Mac (Lightroom) and the algorithm used by the camera's ASIC are the same. Of course, both perform a good quality RAW-to-JPG conversion, so if Lightroom is in fact using a slower algorithm, they probably shouldn't. ;-)
The point is that JPEG compression is something that is highly optimized in hardware these days, and it is very unlikely that a power-conscious mobile device would perform this operation in software on a general-purpose processor.
This comment was marked helpful 0 times.

I looked for some information on the actual performance of Anton and found the following articles:
NRBSC, DESRES Extend Anton's Stay at Pittsburgh Supercomputing Center
The article mentions that the simulations of the proteins simulate changes that happen between 10 microseconds and 1 millisecond, and many supercomputers are limited to simulating only 1 microsecond. Using Anton, researchers were able to simulate a 80 microsecond protein movement in 2 weeks total, whereas a different 20 microsecond simulation took a year on a different computer.
This comment was marked helpful 0 times.
@dyc: This paper is the one you are looking for: Millisecond-scale molecular dynamics simulations on Anton (Shaw et al., Supercomputing 2009)
This comment was marked helpful 0 times.



Transferring data between different chips is challenging. We need to take care of communication overhead.
This comment was marked helpful 0 times.


The idea here is that chip designers want to be conservative, because if they are conservative and wrong, they misuse ~1% of the chip (in this example). IF they're conservative and devote more chip space to rasterization than is needed, they have only wasted that extra chip space devoted to rasterization. However, if they are not conservative and wrong, then they have wasted a much bigger portion of the chip because the rasterization portion serves as a bottleneck (leaving everything else not fully utilized). It's a smarter bet to be conservative.
This comment was marked helpful 0 times.
Is there a concrete calculation as to how 99% -> 80%?
This comment was marked helpful 0 times.

I'm not sure how to get 80% either.
If we thought we needed 1% of the chip for rasterization, and we called that 100% efficiency, then if we end up wanting 1.2x that amount, it seems we have 20% more rasterization workload than expected. Then the rasterization step is taking 1.2x as long. If we assume the rasterization step is always the bottleneck, then 0.2/1.2 of the time the rest of the chip is doing nothing.
Then the efficiency of the rest of the chip is (working time)/(total time) = 1/1.2 = 83.33%.
This comment was marked helpful 0 times.
Disregarding the efficiency computation, I've read of large core chips which know the utilization of cores, and will power down cores which are not needed. This seems like a load balancer, in essence, and I wonder if this could be put to use in GPUs, where there are definitely a large number of cores, all of which may not be doing any work at all.
Further, to help GPU utilization, new NVIDIA GPUs have the ability to run more than a single kernel at once. This might be able to utilize more of the GPU since one kernel does not lock the device from being used.
This comment was marked helpful 0 times.

In addition to having to design the system with the functionality of the hardware in mind, the software designer must also consider how to write programs to best utilize the available components. The different algorithms can run faster on different hardware e.g. GPU's with high throughput versus a single CPU. Portability is an issue, so software is generally written for a specific hardware, such as an OS for a specific phone hardware, or the previously mentioned Anton supercomputer.
This comment was marked helpful 0 times.




Answer: It depends on the workload. For a highly parallel workload, the higher total throughput of Processor B (8P) will be preferable. For a mostly sequential workload, the higher processing power per core of Processor A (P as opposed to P/2 for Processor B) will be more attractive.
This comment was marked helpful 1 times.