









From hardware perspective, I think this contention is very easy to implement, given that the tags and state can be just wired to both the processor and the bus. They are after all just combinational logic components.
This comment was marked helpful 0 times.

From the hardware perspective, it is very common to have data-forwarding from write-back buffers for reads from other processors, so the other processors can see the new values before they actually get flushed into memory.
This comment was marked helpful 0 times.







Notice that the real cost of idling on an atomic bus is that memory transactions generally take hundreds of cycles. The whole point of caching was to try to alleviate this latency, but implemented naively we will get little benefit, since only one transaction can be done at any time. For example, in the time spent waiting on a write to complete we could easily have made a BusUpg request to make everyone drop their cache lines, which doesn't need memory access.
This comment was marked helpful 1 times.
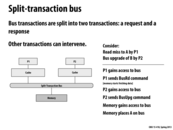

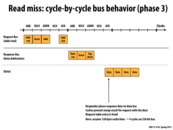
Let's compare the functionality of an atomic bus to this new, split-transaction bus. Say P1 wants to issue a BusRd command, and P2 wants to follow-up with a BusUpg command to all processors. Note that the BusRd command consists of two phases: a request phase (notifying memory of the request over the bus) and a response phase (memory sending back the appropriate data on the bus, after servicing the request). In an atomic bus, both phases of the first BusRd have to completely finish before the BusUpg command can be handled. However, in a split-transaction bus, request and response transactions are split into two, decoupled phases. That means that after P1 has issued its BusRd request (with the response coming at some point in the future), P2 can immediately issue its BusUpg request (I believe BusUpg's don't really have a response phase). The BusRd response eventually gets placed by memory onto the bus.
As discussed on the next slide however, split-transaction buses introduce new problems to consider.
This comment was marked helpful 0 times.




By adding more wires to the bus, we can keep a table of requests to memory to allow pipelining. This way we can have processors send requests, and have the memory respond once it has finished processing the request. Memory will send back a tag to let the processors know which request the response is for. The next couple of slides shows a more detailed view of this pipelining.
This comment was marked helpful 0 times.

The request table is fundamental of implementation of pipeline the transaction. We can detect whether there is a conflict or not, then based the checking result to make response.
This comment was marked helpful 0 times.
Question Why do we need separate request tables for each processor? Couldn't the bus keep track of this information (when handing out tags, etc). The request bus could send a NACK if a request conflicted with something else in the table, and the bus be attached (is thath the right word?) to the response bus to know when to delete entries from the table. Am I missing something? It seems like the bus arbitration logic will guarantee mutual exclusion when making updates to the table.
This comment was marked helpful 0 times.

@kfc9001. I don't think you are missing anything. There's not much of a conceptual difference between a single table and P replicated copies of the table local to each processor that are kept in sync. But you can imagine that each processor might want to have its own local copy HW design purposes (think locality, modularity, and the ability to put per-processor state in that table).
This comment was marked helpful 0 times.

Question: If each processor has its own request table of size 8, they will be using 3 bits to mark the transaction tag. But, this tage will only differentiate requests between same processor but not across processor because P1 could have request tag 1, P2 could have request tag 2 because both have table sized 8. Then, my guess is that there is another tag on the response that tells to which processor the respond is for? Or is there other way to tell it? OR all cache have same copy of this table?
This comment was marked helpful 0 times.

Question : How are the copies of the request tables maintained? It seems like there might be overhead involved in making sure there is consistency among all the copies depending on the method.
This comment was marked helpful 0 times.

@hh: I think the consistency problem can be solved by snooping on bus. Since all requests and responses will be committed to bus and be visible to all cores, the consistency might not be that hard.
This comment was marked helpful 0 times.
@raphaelk: We can make the tag global. Thus there will be at most 8 outstanding requests in total and all the requests are replicated in all cores' request table (consistency can be soled with snooping bus). Then the responser just need to specify which request it's responding to.
This comment was marked helpful 0 times.
@hh: Yes, all cache controllers snoop the interconnect, giving them a consistent view of all memory transactions, and follow the same rules of modifying their local request tables. Thus they stay in sync. This is no different than snooping the coherence traffic in order to keep the state of a cache line in sync.
This comment was marked helpful 0 times.
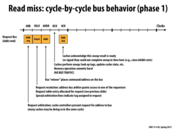

In step 5, if the cache could not complete the snoop, it raises a signal. It was mentioned that some systems might allow these caches another 5 cycles to complete their look-ups. Does it have to give the cache an entire 5 cycles (what if the cache could finish sooner than that)? Can the bus only work on cycles with these fixed stages, or can it just add extra ACK stages if it needs them?
This comment was marked helpful 0 times.
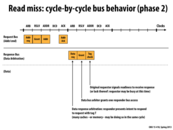

Here, while the response bus is in use, the request bus is free. A processor can hence place another request to be processed while the response bus handles a different response. This way, all the buses can be utilized to their maximum capacity.
This comment was marked helpful 0 times.
Due to the split-transaction bus, the request bus and response bus will not affect each other, then we can pipeline the transactions.
This comment was marked helpful 0 times.

The tag check is the point where the client can issue negative acknowledgments(NACKs). If so, there will be another try to send the data over Response Bus.
This comment was marked helpful 0 times.
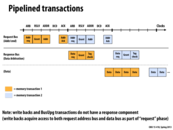

Pipelining allows a split-transaction bus to have greater throughput than an atomic bus. On an atomic bus, the entire request/response has to complete before another processor can access the bus, so only one transaction is being serviced at any given time.
This comment was marked helpful 0 times.
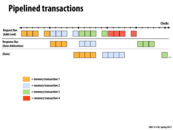
Here we observe a lag between the blue response and the green response. This is because the memory can take an arbitrary amount of time to respond to requests. We are hence not guaranteed continuous usage of the response bus. However the request bus is still being utilized and hence the bus as a whole is not idle.
This comment was marked helpful 1 times.
Also note that this continuous stream of incoming requests cannot continue forever. You need to limit the number of requests you can handle in light of the limited size of data structures like the request table (which helps map requests to responses). That means that if the max number of handleable requests has been reached, no other requests can be processed until some responses are received and those outstanding requests are taken care of.
This comment was marked helpful 0 times.

Question: Why are there 4 outstanding requests? Aren't orange and blue complete, so only green and red are outstanding?
This comment was marked helpful 0 times.
@ vvallabh, well initially there were four outstanding requests. But yeah, later on it does appear that a couple of them were taken care of, so only the green and red requests remain outstanding towards the right of the slide.
This comment was marked helpful 0 times.

To add on to @placebo, requests that appear after the maximum number of requests (request table is full) has been reached could be sent a NACK (Negative Acknowledgement) and we can retry these requests after a few cycles.
This comment was marked helpful 0 times.

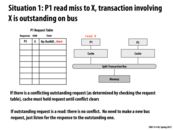

I am a bit confused about how this 'easy' optimization works.
Suppose processor 1 makes a request to read A. If processor 2 wants to read A as well, it can see there is an outstanding request to read A. The slide shows it marking a bit on 'P1 Request Table' that it too wants to read A. So are p1 and p2 both idling until there is a response on the Response Bus? I don't understand why there needs to be a 'share' bit. Can't p2 just wait and see what A is when it appears on the Response Bus?
This comment was marked helpful 0 times.
@pd43: it essentially does.
However, P2 would want to make a note somewhere that it needs to take action when A arrives. Remember, P2 can move on and handle other memory requests while it is "waiting".
This comment was marked helpful 0 times.
@pd43: I think the 'share' bit is a key to make things correct.
Based on the 'Tag check' state in slide 22, P2 might not be ready to handle the response immediately after it had issued the read request. If the main memory send the data when P1 is ready but P2 is not ready, P2 would miss that respond and thus wait forever.
So, we have the sync problem again. It seems complicated to make sure the 'share' bit is seen by all components when they do 'Tag check'.
This comment was marked helpful 0 times.

Here we should also set P1 and P2 to be in the share state rather than exclusive state.
This comment was marked helpful 0 times.


Here, A does some work, and then passes it on to B. The problem is, that the work is variable and unpredictable. For example, task 3 takes little time on A, but takes longer on B. And taks 4 is a lot longer than task 2.
In general without a queue, this means there will be some time where B cannot do any work, because A is working on something that is taking a long time, or vice versa. A queue can make it so that both A and B are working consistently. This is because when A is taking long, B can catch up on its backlog (the work A put in the queue while B was doing other things). And when B is taking long, A can still do work and put it in the queue. Thus, if on average the two produce and consume at the same rate, they will work at a full rate because they will usually be able to do something.
This comment was marked helpful 0 times.
Here the important thing is that if there is no queue, A must wait for B to finish its last consumption, otherwise B will not receive the responce from A, then A should be waiting and idle. However with the queue, A can send the response to the queue of B and A can continue its production of the next work.
This comment was marked helpful 0 times.

Having a queue between two workers allows for variability. Instead of the workflow being rigid, the queue makes the start-to-finish flow of work fluid.
This comment was marked helpful 0 times.

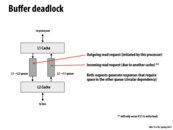

For details, buffer deadlock means that L1 cache and L2 cache are waiting for each other on buffers. L1 requests L2, but it finds the L1->L2 queue is full. So it waits for the progress of the queue. Meanwhile, L2 requests L1 in the same context. They keep busy on waiting and cannot handle this correctly.
This comment was marked helpful 0 times.

A simple/conservative way to prevent buffer deadlocks is to limit the number of outstanding requests in a buffer by some small bound. If there is no more space for a request, then it will just send back a negative acknowledgement. Another way to avoid deadlocks is to allocate two separate queues for requests and responses, respectively, which is further delineated in the next slide.
This comment was marked helpful 0 times.

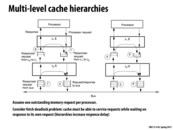
Note that this problem will only occur when the cache closer to the processor (in this case, the L1 Cache) is a write-back cache.
This comment was marked helpful 0 times.


This is similar to what is done on a split transaction bus, where transactions are split into responses and requests. However, here the transactions are split into 4 queues to service both incoming and outgoing requests.
This comment was marked helpful 0 times.



TLB = Translation Lookaside Buffer.
This comment was marked helpful 0 times.
More helpfully (if you've forgotten) TLBs cache page tables, which are used when implementing paging for virtual memory (this is that address translation stuff)
This comment was marked helpful 0 times.
Consider this basic implementation of a cache-coherent system, based on a shared bus -- when a processor uses the bus, the data placed on the bus can by seen by all other parts of the system that are connected to it. For simplicity's sake, the bus is atomic, meaning that one of the major issues we will run into is contention: processors looking to use the bus must wait until no other part of the system is using it. Maintaining coherence requires a large amount of communication, making the challenge of alleviating contention in such a system all the more tricky.
This comment was marked helpful 0 times.