This seems like a bad idea to me. Wouldn't it be better to have a separate fetch/decode unit for each ALU? What's the advantage of doing it this way?
This comment was marked helpful 0 times.
ron
My understanding is as follows: This (SIMD processing) has an advantage in programs where you are repeating the exact same computation multiple times with no dependencies between each repetition, like in the earlier example where you have a for loop over an array of data running the exact same computation for each element of the array. In that case, the instruction set you're sending to the ALU is identical each time (since the ALU doesn't handle loading of the elements from memory, which is the only difference between each iteration). Thus you can have parallel processing while saving the energy cost of having multiple fetch/decode units, by having the single fetch/decode unit load a vector of elements - one for each of the ALUs - and then having each ALU process computation for its element in parallel. In the above example, you'd be able to process a vector of 8 elements in parallel this way.
I believe instruction stream coherence slide 32, and SSE/AVX instructions slide 33 are very relevant here.
This comment was marked helpful 0 times.
snshah
Thanks, @ron, for the explanation. I'm still a little confused as to how this works, but my main question is how often do situations come up where this setup is useful, where you have a single instruction being repeated a bunch of times on independent pieces of data? Does it happen often enough that it justifies having this type of setup?
Does this work well in other contexts as well?
This comment was marked helpful 0 times.
black
@snshah, I think it will be useful when we do computation on math works. For example, we need to calculate the production of two vectors, or the mean of each column of a matrix. Matlab must utilize this tech much in my opinion.
This comment was marked helpful 0 times.
yrkumar
@snshah, more advantages of SIMD processing are given in this Wikipedia article. The most well known applications of SIMD seem to be graphics-related. One example that takes advantage of SIMD, as mentioned in the article, is adjusting the brightness of an image (which I'd imagine has to be done all the time in video games and such).
This comment was marked helpful 0 times.
kayvonf
The advantage of SIMD execution is that the costs of processing an instruction stream (fetching instructions, decoding instructions, etc.) are amortized across many execution units. The circuitry for performing the actual arithmetic operation is quite small compared to all the components that are necessary to manage an instruction stream, so SIMD execution is a design choice that enables a chip to be packed more densely with compute capability.
Workloads that map well to single instruction multiple data execution run efficiently on this design. Workloads that don't map well to SIMD execution will not be able to take advantage of the SIMD design.
This comment was marked helpful 0 times.
bstan
How does having multiple ALUs and contexts affect the size of the CPU? It is because of advances in transistors/design that we can fit more ALUs onto the chip? I wonder how much the improvements in transistors/materials/etc contribute to the perceived improvements of multi-core processors. I would assume it's small, but it would be interesting to see what a high-end single core processor would look like if it was manufactured today.
This comment was marked helpful 0 times.
shabnam
I am just curious to know, are the instructions fed to each ALU ( like a broadcast?) or do they just pick it up from a central location.
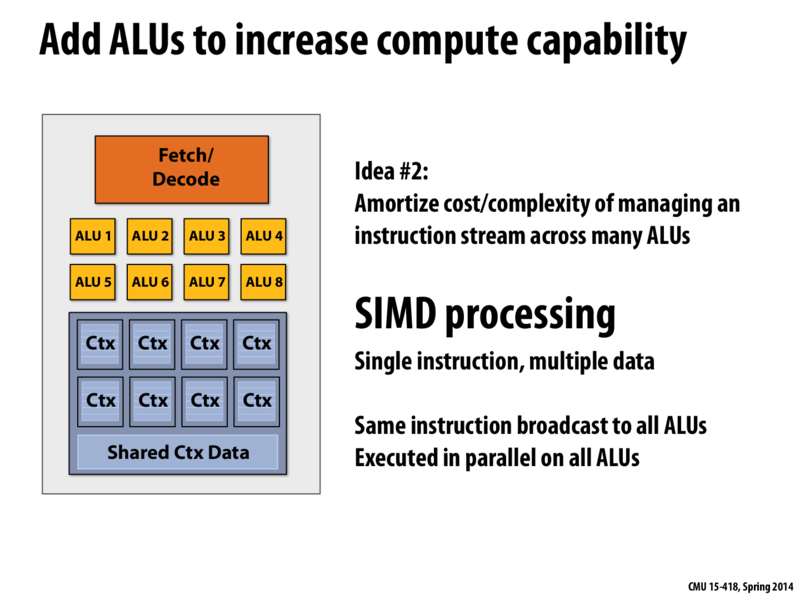
This seems like a bad idea to me. Wouldn't it be better to have a separate fetch/decode unit for each ALU? What's the advantage of doing it this way?
This comment was marked helpful 0 times.
My understanding is as follows: This (SIMD processing) has an advantage in programs where you are repeating the exact same computation multiple times with no dependencies between each repetition, like in the earlier example where you have a for loop over an array of data running the exact same computation for each element of the array. In that case, the instruction set you're sending to the ALU is identical each time (since the ALU doesn't handle loading of the elements from memory, which is the only difference between each iteration). Thus you can have parallel processing while saving the energy cost of having multiple fetch/decode units, by having the single fetch/decode unit load a vector of elements - one for each of the ALUs - and then having each ALU process computation for its element in parallel. In the above example, you'd be able to process a vector of 8 elements in parallel this way. I believe instruction stream coherence slide 32, and SSE/AVX instructions slide 33 are very relevant here.
This comment was marked helpful 0 times.
Thanks, @ron, for the explanation. I'm still a little confused as to how this works, but my main question is how often do situations come up where this setup is useful, where you have a single instruction being repeated a bunch of times on independent pieces of data? Does it happen often enough that it justifies having this type of setup?
Does this work well in other contexts as well?
This comment was marked helpful 0 times.
@snshah, I think it will be useful when we do computation on math works. For example, we need to calculate the production of two vectors, or the mean of each column of a matrix. Matlab must utilize this tech much in my opinion.
This comment was marked helpful 0 times.
@snshah, more advantages of SIMD processing are given in this Wikipedia article. The most well known applications of SIMD seem to be graphics-related. One example that takes advantage of SIMD, as mentioned in the article, is adjusting the brightness of an image (which I'd imagine has to be done all the time in video games and such).
This comment was marked helpful 0 times.
The advantage of SIMD execution is that the costs of processing an instruction stream (fetching instructions, decoding instructions, etc.) are amortized across many execution units. The circuitry for performing the actual arithmetic operation is quite small compared to all the components that are necessary to manage an instruction stream, so SIMD execution is a design choice that enables a chip to be packed more densely with compute capability.
Workloads that map well to single instruction multiple data execution run efficiently on this design. Workloads that don't map well to SIMD execution will not be able to take advantage of the SIMD design.
This comment was marked helpful 0 times.
How does having multiple ALUs and contexts affect the size of the CPU? It is because of advances in transistors/design that we can fit more ALUs onto the chip? I wonder how much the improvements in transistors/materials/etc contribute to the perceived improvements of multi-core processors. I would assume it's small, but it would be interesting to see what a high-end single core processor would look like if it was manufactured today.
This comment was marked helpful 0 times.
I am just curious to know, are the instructions fed to each ALU ( like a broadcast?) or do they just pick it up from a central location.
This comment was marked helpful 0 times.