





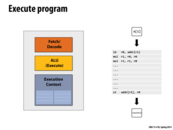

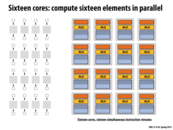
The block diagram shown above is a simplified version of the processor model:
- the Fetch/Decode unit reads in the next instruction and interprets the instruction for what to do next;
- the ALU (or Arithmetic Logic Unit) executes the instruction read;
- as for the Execution Context, it contains the state elements such as registers.
This comment was marked helpful 1 times.
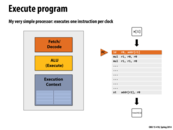
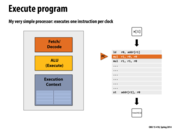
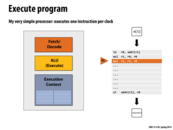
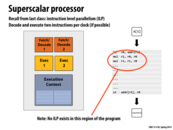

Question: Why did I draw two orange boxes in this diagram?
This comment was marked helpful 0 times.

To reflect that this processor can simultaneously fetch/decode and execute two different instructions at the same time, which is not very helpful in this case since the instructions need to be executed sequentially (there is no Instruction Level Parallelism in the program)
This comment was marked helpful 0 times.

I just noticed that this is the only slide (or at least seems to be the only slide) with two orange boxes with one execution context. Is multiple Fetch/Decode boxes being present only helpful with ILP? And even if that is the case, ILP should still be used normally, as it still improves runtime even if not by the degree one would hope for, correct?
This comment was marked helpful 0 times.

@TheRandomOne
See Kayvon's post on the last slide of this lecture. Multiple Fetch/Decode units are useful for Simultaneous Multithreading, with Intel Hyper-threading (http://en.wikipedia.org/wiki/Hyper-threading) being an example implementation.
I'm also not sure, and would be curious to know whether or not superscalar and SIMD processing are mutually exclusive.
This comment was marked helpful 0 times.

In this slide we are trying to fetch two independent instructions from a single instruction stream, much like ILP. For Hyper-threading we are trying to fetch multiple instructions from different instruction stream and execute them at the same time, which is simultaneous multithreading.
This comment was marked helpful 0 times.

@jon I think that superscalar and SIMD are not mutually exclusive, as in the case of the NVIDIA GPUs. They have multiple fetch/decodes going for the superscalar ILP, and each of those instructions is executed on up to 32 threads, which is the SIMD.
This comment was marked helpful 0 times.


This execution unit has an FPU and two integer units. Can these things be run simultaneously? Does that mean the ALU can effectively do more?
This comment was marked helpful 0 times.

I think they can run simultaneously. And ALU can do more based on design.
This comment was marked helpful 0 times.

Unfortunately, running them simultaneously is/would be difficult since they tend to execute instructions at different rates (integer unit faster than FPU in general).
This comment was marked helpful 0 times.

@rharwood @bwasti There is no problem for different ALUs to run simultaneously. The key reason is they do not share any circuit. In a modern Out-Of-Order processor (Pentium 4 is an example), the reservation station can issue multiple independent instructions at the same time. These instructions will be issued through separate wires to corresponding execution units. This is how modern processors exploit ILP. According to the diagram in this slide, the reservation station can issue (1 SIMD instruction + 1 floating point instruction + 2 integer instruction + 1 memory operation) at most in the same cycle. It does not matter how long the instruction will take to execute.
If you are really interested about how Out-Of-Order processors exploit ILP (resolving register dependencies, monitoring when the instruction is ready, etc) and have a lot of time, here are some slides introducing Out-Of-Order execution. You can also search for keywords: "Out of Order Execution", "Tomasulo Algorithm", "Scoreboarding".
It is true that FPU usually takes multiple cycles to execute, while integer unit usually take one cycle. But this does not stop them to run simultaneously. Also, FPUs are usually pipelined such that they can have the same throughput as an integer unit. Can you explain why you think this would cause a problem?
This comment was marked helpful 0 times.


How does having smaller transistors lead to a higher clock frequency?. I am aware that if we have smaller transistors we can pack the same number of transistors into a smaller core(physically) and hence have more cores per chip. But since each core still has the same number of transistors wouldn't the power consumed stay the same and hence still limiting the clock frequency ?
This comment was marked helpful 0 times.

I believe if you have smaller transistors, you can fit more of them into 1 processor and therefore, you get greater computing power. There is a more detailed discussion about this here.
This comment was marked helpful 0 times.

A useful discussion from last year.
post by @tborenest:
If Moore's law implies that the amount of transistors we can fit into a certain amount of space keeps getting bigger and bigger, is it really necessary to decrease the sophistication of processor logic? Why can't we have the best of both worlds - several processors that are all just as sophisticated as the processors that came before the multi-core era?
Post by @kayvonf:
@tborenest: your thinking is correct. It's really a matter of how sophisticated a single core is today, vs. how sophisticated a single core at today's transistor counts could be.
You could implement very sophisticated branch predictors, prefetchers, huge out-of-order windows, and add in a huge data cache, or you could choose more modest implementations of all these features and place a few cores on the chip. Studies show the former would (for most single-threaded workloads) increase your performance a few percentage points, or maybe at best a factor of two. However, in the the latter case, you now have four or six cores to give a multi-threaded workload a real boost. I should change this slide to say: Use increasing transistor count for more cores, rather than for increasingly complex logic to accelerate performance of a single thread.
Keep in mind that by multi-threaded, I mean multiple single-threaded processes active in the system, running on different cores. This is helpful on your personal machine when multiple programs are running, and it is very helpful on servers, where it's common to run several virtual machines on the same physical box.
This comment was marked helpful 0 times.
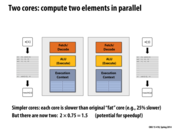

What are some of the possible reasons that a core in this situation might be slower?
This comment was marked helpful 0 times.
Seem here, just curious why the cores right now cant be at least as fast as the original "fat" core?
This comment was marked helpful 0 times.

I think the concept here is that rather than one "fat" core, we can have two slightly slower cores for the for the same amount of "resources" (some kind of combination of manufacturing costs, time, energy expenditure etc). Thus we can see that even though 2 cores isn't necessarily 2x speedup, it's more efficient and gives better results than focusing our resources on a single fat core. I think this is readily obvious if you consider all modern CPUs which are multi core, companies of course will pursue whichever avenue is most profitable for them (less cost for same power).
This comment was marked helpful 0 times.



How are the different pthreads assigned to processors? Is this dictated by the programmer, compiler, OS, or hardware?
This comment was marked helpful 0 times.
The OS is responsible for assigning logical operating system threads to physical hardware execution contexts. An OS context switch involves copying the state of an execution context off the processor and saving it in memory, and replacing it with another (previously saved) execution context.
A good discussion about this is unfolding on slide 52.
This comment was marked helpful 0 times.


There exists an extension to C called Unified Parallel C (UPC) designed for large-scale parallel computation. It actually has a upc_forall command. According to the specs, using that command signals to the compiler to use threads, similar to the last slide.
This comment was marked helpful 0 times.
Thanks for the clarification. But is this forall command equivalent to the last page with the pthread? Do we also use the same synchronization methods if there's any shared state that needs protecting?
This comment was marked helpful 0 times.

@lixf This slide and the previous slide is saying that either the programmer explicitly adds parallelism, or the programmer marks a computation as parallel. Then the compiler can do what it can with that information. Most obvious choice for the compiler here is to add in pthreads, just like in the previous slide. But the compiler might not do anything at all! It could just ignore the forall and compile it as if it was a sequential for loop.
This comment was marked helpful 0 times.
It seems appropriate, given @jinsikl's comment, to therefore draw attention to how this shows us the difference between abstraction and implementation. We can choose, as the programmer, to adopt existing frameworks which have abstract commands like forall and not be concerned about the underlying implementation or we could write the full thing ourselves.
This comment was marked helpful 0 times.


For those that are interested in what current high-end GPUs are composed of, the NVIDIA GTX Titan GPU has 2688 cores and about three times as many transistors as a top of the line i7. Also not surprising, the actual graphics card is really a giant heatsink.
Image: http://cdn3.wccftech.com/wp-content/uploads/2013/02/er_photo_184846_52.png
{kind=link}
This comment was marked helpful 1 times.
@kayvonf After a bit of reading it seems that CUDA cores are more comparible to ALUs rather than a true CPU core, although I'm hesitant to say that they are hardware-wise anything related. Nvidia seems to describe them as parallel shading calculation units, so could it possibly be described as multiple (or one) giant core with thousands of mini "ALU-ish" calculation units?
This comment was marked helpful 0 times.
Yes, that is correct. NVIDIA uses the term "CUDA core" to refer to what amounts to an execution unit responsible for "one lane" of a vector operation. It's a more complicated than that if we want to get into micro-architectural details, but it is perfectly reasonable to equate one lane of SIMD unit in an Intel CPU with a "CUDA core". If you're thinking, why does NVIDIA say "core" to mean one thing when the rest of the industry uses the term to mean something else... the answer: good marketing. Larger numbers sound better.
By NVIDIA's definition, the GTX 480 shown here has 15*32 = 480 CUDA cores. Just count the yellow boxes.
This comment was marked helpful 0 times.
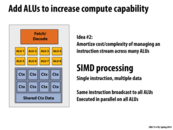
This seems like a bad idea to me. Wouldn't it be better to have a separate fetch/decode unit for each ALU? What's the advantage of doing it this way?
This comment was marked helpful 0 times.

My understanding is as follows: This (SIMD processing) has an advantage in programs where you are repeating the exact same computation multiple times with no dependencies between each repetition, like in the earlier example where you have a for loop over an array of data running the exact same computation for each element of the array. In that case, the instruction set you're sending to the ALU is identical each time (since the ALU doesn't handle loading of the elements from memory, which is the only difference between each iteration). Thus you can have parallel processing while saving the energy cost of having multiple fetch/decode units, by having the single fetch/decode unit load a vector of elements - one for each of the ALUs - and then having each ALU process computation for its element in parallel. In the above example, you'd be able to process a vector of 8 elements in parallel this way. I believe instruction stream coherence slide 32, and SSE/AVX instructions slide 33 are very relevant here.
This comment was marked helpful 0 times.

Thanks, @ron, for the explanation. I'm still a little confused as to how this works, but my main question is how often do situations come up where this setup is useful, where you have a single instruction being repeated a bunch of times on independent pieces of data? Does it happen often enough that it justifies having this type of setup?
Does this work well in other contexts as well?
This comment was marked helpful 0 times.

@snshah, I think it will be useful when we do computation on math works. For example, we need to calculate the production of two vectors, or the mean of each column of a matrix. Matlab must utilize this tech much in my opinion.
This comment was marked helpful 0 times.

@snshah, more advantages of SIMD processing are given in this Wikipedia article. The most well known applications of SIMD seem to be graphics-related. One example that takes advantage of SIMD, as mentioned in the article, is adjusting the brightness of an image (which I'd imagine has to be done all the time in video games and such).
This comment was marked helpful 0 times.
The advantage of SIMD execution is that the costs of processing an instruction stream (fetching instructions, decoding instructions, etc.) are amortized across many execution units. The circuitry for performing the actual arithmetic operation is quite small compared to all the components that are necessary to manage an instruction stream, so SIMD execution is a design choice that enables a chip to be packed more densely with compute capability.
Workloads that map well to single instruction multiple data execution run efficiently on this design. Workloads that don't map well to SIMD execution will not be able to take advantage of the SIMD design.
This comment was marked helpful 0 times.

How does having multiple ALUs and contexts affect the size of the CPU? It is because of advances in transistors/design that we can fit more ALUs onto the chip? I wonder how much the improvements in transistors/materials/etc contribute to the perceived improvements of multi-core processors. I would assume it's small, but it would be interesting to see what a high-end single core processor would look like if it was manufactured today.
This comment was marked helpful 0 times.
I am just curious to know, are the instructions fed to each ALU ( like a broadcast?) or do they just pick it up from a central location.
This comment was marked helpful 0 times.




Question: I have never tried AVX yet, therefore when reading I found that the line __mm256_broadcast_ss(6) looks weird somehow... According to Intel's documentation it is "Loads and broadcasts 256/128-bit scalar single-precision floating point values to a 256/128-bit destination operand.". But what exactly does broadcast mean?
This comment was marked helpful 0 times.
In vector programming a broadcast (or a "splat") is taking a single value, say x and writing it to all lanes of the vector unit. In Assignment 1, the 15418 fake vector intrinsic _cmu418_vset_float is a form of a broadcast.
You may find the following useful: http://software.intel.com/sites/landingpage/IntrinsicsGuide
Here is the definition of _mm256_broadcast_ss:
Broadcast a single-precision (32-bit) floating-point element from memory to all elements of dst.
Operation pseudocode (consider dst to be a vector register):
tmp[31:0] = MEM[mem_addr+31:mem_addr]
FOR j := 0 to 7
i := j*32
dst[i+31:i] := tmp[31:0]
ENDFOR
dst[MAX:256] := 0
This comment was marked helpful 0 times.

So is this kind of code specific to the machines that you will be running it on and the processors it has? In other words, would vector programming translate across machines?
This comment was marked helpful 1 times.

I'm interested to know this (above) as well. I would guess that the SIMD implementation cannot be done through the OS interface?
Edit: Just curious, so we use __mm256_broadcast_ss(6) to write eight copies of 6 across the vector. How would we go about writing something like (1,2,3,4,5,6,7,8)? Must we load the values into the array and call _mm256_load_ps()?
This comment was marked helpful 0 times.
@ycp: Great observation. A binary with vector instructions in it only runs on a machine that supports those instructions. Since the binary is emitted assuming a particular width it is not portable to another machine with vector instructions of a different sort. For example, a program compiled using SSE4 in 2010 won't be able to take advantage of AVX instructions in a later chip. Current programs using AVX can't take advantage of the 16-wide AVX-512 instructions available on the 60-core Intel Xeon Phi processors.
This is one reason that GPUs have adopted in "implicit SIMD" implementation strategy, where the instructions themselves are scalar, but are replicated across N ALUs under-the-hood by the hardware. See Lecture 2, slide. This theoretically allows GPU's to change their SIMD width from generation to generation without requiring change to binaries. There are positives and negatives to both strategies.
This comment was marked helpful 0 times.
Question: someone should go figure out the answer to @kkz's question.
This comment was marked helpful 0 times.

@kkz: for the vector question, you should use _mm256_set_epi32(8,7,6,5,4,3,2,1).
I feel like SIMD is the compiler's responsibility, not the operating system's. The OS just runs assembly; it doesn't generate any. The one case I can think of is virtualization: if you're writing a VM that simulates a machine with vector assembly instructions, you might have to handle those at the OS level.
This comment was marked helpful 2 times.
I actually extended my compiler from 15-411 to execute SIMD instructions and I'd definitely agree that SIMD is the compiler's responsibility more than the OS's. However, detecting the parallelism across loops and such is a difficult problem and one might therefore also need constructs in the language, similar to OpenMP, so as to aid the compiler to make this optimization.
This comment was marked helpful 0 times.


From my understanding, the foreach term dictates that the compiler must create different instances to run each iteration of the code such that each iteration is running the same exact instruction. This is different than when we use launch, which spawns multiple threads and does not abide by the same restrictions as simd.
This comment was marked helpful 0 times.

If you spawn multiple threads on one core, they will run concurrently rather than in true parallel. That is, only one thread will be running at any time, but the core may switch between them to hide latency. On the other hand, using SIMD still only has one instruction thread, but performs those instructions on several sets of data in parallel.
This isn't really a dichotomy; they do two different things. If you wanted, you could spawn multiple threads, each performing a different program flow of vector computations with SIMD. The processor would attempt to hide latency from (now vector-sized) memory instructions by switching between these threads.
This comment was marked helpful 0 times.



Clarification: Imagine we want to execute the logic described by the pseudocode on the right for each element of a large array of numbers, and we want to do so as efficiently as possible on our fictitious processor which is capable of eight-wide SIMD execution. In the code, assume that there is an input array A, and that x is initialized to A[i]. Also assume there's an output array B and that B[i] = refl. The code segment on this slide should be changed to something more intuitive (I apologize).
Now consider the fundamental problem at hand. We have to perform a computation that logically may take a different sequence of control for each element in the input array, but we have a processor that operates by executing one instruction on eight execution units at once. We don't know what sequence of control each iteration requires at compile time, because the answer is dependent on the value of A[i]. How do we map this program onto this execution resource (given the constraints of the resource)?
This comment was marked helpful 0 times.



An example from lecture exhibiting nearly the worst-case performance is as follows: Imagine there 8 elements in the input array, one of which follows the 'if' branch and the rest following the 'else' branch, where the 'if' branch has a million instructions and the 'else' branch has only 1. With masking, this will take each of 8 ALUs a million and one clocks, while peak performance would take a total of a million and seven clocks -- approximately 1/8 the amount.
This comment was marked helpful 0 times.
I agree with the explanation. But the peak performance should be interms of the useful work done by the ALUs, not the number of cycles, I think.
This comment was marked helpful 0 times.

In the worst case, the performance is almost the same as a core with only one ALU. It seems adding ALUs is really a good method to speed up CPU. Any tradeoffs? (Of course, it's slightly more expensive)
This comment was marked helpful 0 times.

@paraU This seems to tie a lot into ISA design. Will the ALU dispatch be a decision for the programmer (ie. SIMD instructions) or operated solely by hardware (ie. superscalar architectures)? As more of the implementation is hidden from the programmer, the hardware logic to manage the data going in and coming out of them becomes more complicated. And if there are enough dependencies in the code, the CPU waits even longer to dispatch data. Mix this in with out-of-order execution/reordering logic, multi-threading, branche prediction, etc. and now there is a host of indirect decisions to be made to having more ALUs. I guess what it really comes down to is how able can the CPU make use of the ALUs.
This comment was marked helpful 0 times.

In regards to cardiff's example, what if all elements followed the else case?
This comment was marked helpful 0 times.

If all elements followed the else case in @cardiff's example, i.e., there are no inputs that would trigger the 'if' clause, then it should be that it would take each of the alu's 1 clock right? Would the peak performance be 1 clock or 8 clocks in that case?
This comment was marked helpful 0 times.
The code on the right is a single sequential sequence of control. The variable x is meant to be single floating-point value (e.g., 'float x'). Now assume that this code might be the body of a loop with independent iterations, such as the forall loop I showed on slide 17. So let's say we're running this code for each element in an array 'A', and for each iteration of the loop x is initialized to A[i].
Now, we know we have SIMD execution capabilities on a processor and we'd like to make use of them to run faster. However, we have a program that's written against an abstraction where each iteration of the loop has it's own control flow. No notion of SIMD execution is present at the programming language level.
The problem at hand is how to map a program written against this abstraction onto the actual execution resources, which have constraints not exposed at the language level. (For example, the mapping would become trivial if if statements were not allowed in the language, forcing all iterations to have the same instruction sequence.)
On slide 33 I point out that the act of mapping such a program into an efficient SIMD implementation can be responsibility of a compiler or it could be the responsibility of the hardware itself (as in slide 34). One example of the former case is the ISPC compiler. It emits SSE or AVX instructions into its compiled programs that generate lane masks, use the lane masks to prevent certain writes, and also generates code that handles the branching logic in the manner we discussed in class. The processor (e.g., the CPU in the case of ISPC) just executes the instructions it's told. There's no smarts needed. All the smarts are in the compiler.
On the other side of the design spectrum, the compiler can be largely oblivious to SIMD capabilities of hardware, and most of the smarts can go into the hardware itself. To date, this has been the GPU-style way of doing things. Although we'll talk about GPUs in detail later in the course, here's a good way to think about it for now: The GPU will accept a mini-program written to process a single data item (e.g., you can think of the mini-program as a loop body) as well as a number of times the mini-program should be run. It's like the interface to the hardware itself is a foreach loop.
This comment was marked helpful 0 times.
Also, with reference to @elemental03's question, I don't think we will gauge performance based on clock cycles (I don't quite know what you mean by an ALU clock). If all lanes of the 8-wide vector go to the else case, then there is no ALU that is idle since all of them will be executing the code block for the else clause. So we still achieve peak performance (all 8/8 ALUs are running)
This comment was marked helpful 1 times.


I've always heard that branching inside a shader should be avoided like the plague. I always just assumed that GPUs were just bad at branch prediction, but now I realize that a situation like this could also hurt shader performance. There's a pretty cool stackoverflow entry on this topic, and the top answer talks a little bit about nVidia's warps. Nifty.
This comment was marked helpful 0 times.
From the article you linked, it sounds more like they're not bad at branch prediction but that it's nonexistent:
On the GPU things a little different; the pipeline are likely to be far shallower, but there's no branch prediction and all of the shader code will be in fast memory -- but that's not the real difference.
This comment was marked helpful 0 times.
Regardless of whether branch prediction is present or not (and this certainly depends on the details of GPU implementations--which are often not available to the public), it is certainly true that any branch prediction that exists will certainly be simpler than the sophisticated predictors in modern CPUs. Rather than strive for high-quality prediction, GPU architects (wisely thinking about their anticipated workloads) concluded that it would be more efficient to use transistors for other features, such as wider SIMD, more cores, special instructions to accelerate graphics, etc.
For the architecture folks in the class: My understanding is that most modern GPUs do not branch predict. The pipeline stalls that might result from a misprediction can easily avoided using another mechanism that is present on GPUs. Question: What is the mechanism GPUs rely heavily on to avoid stalls? (Note this reasoning also explains why sophisticated techniques like out-of-order execution, pipeline forwarding, etc. are less critical in a GPU core. since the cores can be simpler, there can be more of them.)
This comment was marked helpful 0 times.

@kayvonf: multi-threading?
This comment was marked helpful 2 times.

@iamk_d__g:multi-threading+1
This comment was marked helpful 0 times.



Intel has also unveiled 512 bit AVX instructions as of July 2013, but it looks like the first of their processors that will support this technology has not been released yet (the Intel Xeon Phi processor and coprocessor codename "Knights Corner").
This comment was marked helpful 0 times.
Yes, Xeon Phi is out.
http://ark.intel.com/products/75799/Intel-Xeon-Phi-Coprocessor-7120P-16GB-1_238-GHz-61-core
This comment was marked helpful 0 times.
@kayvonf: Question: I'm a bit confused about what does the 128-bit and 256-bit operation stands for? Like 8-wide float vectors, does it mean AVX enables 8 ALUs (or cores) to do float calculation simultaneously?
This comment was marked helpful 0 times.
It's just the size of the vectors being operated on. An SSE instruction operates on 128-bit registers. Those registers can either hold four 32-bit values, or two 64-bit values. For example: an SSE instruction can add two length-4 vectors of single-precision floating point values in one clock.
An AVX instruction operates on 256-bit registers. So for example: an AVX instruction can add two length-8 vectors of single precision floating point values in one clock. Twice as much throughput!
Each of the _mm256 intrinsics on slide 24 corresponds to an AVX vector instruction executed by one core. In the terminology of this lecture, a vector execution unit made up of 8 parallel floating point ALUs (eight yellow boxes) in a single processor core executes this instruction. Alternatively, you might want to think about a vector execution unit as a single entity, with hardware in it to do eight operations at once.
This comment was marked helpful 0 times.

It seems to me that the SIMD optimization would have different effects on CPUs with different number of ALUs per core. So the programs should be recompiled again on every machine? In other words, the executable files have really bad portability?
This comment was marked helpful 1 times.
@tianyih If the width of vector units (not number of ALUs, to eliminate confusion) on the CPU has changed, then you will need to recompile the code. To be more general, if any instruction (CPU instructions, not c statements) used by your program has a different functionality in the new CPU, you will have to recompile it. Fortunately this almost never happens to desktop CPUs after intel dominates. This is because intel keeps backward compatibility to all of their old instructions. As an example for this slide, a new intel CPU that supports 256 bit AVX instructions still supports 128 bit SSE instructions.
This comment was marked helpful 0 times.

@kayvonf Im a little confused about the interaction between ISPC program instances/gangs and ALUs. Consider the program
float func() {
foreach(i = 0 ... 7) {
// do computation
}
}
Under SSE, say the values i = 0,1,2,3 are processed first and then i = 4,5,6,7. How are these values of i mapped to instances in a single gang? In my mind, it makes sense to say that on a single iteration of execution of the ALUs, a gang will process i = 0,1,2,3 simultaneously and then on the next iteration, the gang will process i = 4,5,6,7 simultaneously. But where does an individual program instances come into play here? Can a gang of program instances be viewed as a single thread? Or should each program instance in the gang be viewed as its own thread? Thanks
This comment was marked helpful 0 times.
@tianyih: Good point. There's a discussion of code portability going on on Slide 24
@nbatliva: Any ISPC function call is always running as an SPMD program. That is, a gang of programCount ISPC program instances are running the logic defined by the ISPC function.
The foreach construct basically says. For each iteration in the defined iteration space, have one of the gang's program instances carry out the logic of the body of the for each. The foreach does not specify which program instance will, nor does it specify the order in which the iterations will be carried out. ISPC makes no other gaurantees.
Now, your question is about how is the foreach construction is actually implemented by the compiler? Well, we'd have to go look at the generated code to figure it out. However, I happen to know that the ISPC compiler will generate code that maps iterations to program instances in an interleaved fashion as was done here. To check your understanding, check out the question I ask on Lecture 3, slide 14.
This comment was marked helpful 1 times.

I looked into compilers that find parallelism in for loops, and found this interesting article about automatic parallelization in C/C++ compilers by Intel:
http://software.intel.com/en-us/articles/automatic-parallelization-with-intel-compilers
The "Advice" section is particularly interesting, as it touches on the limitations. Even though it's certainly a hard problem, it seems like there is quite a bit of room for improvement! (Maybe us programmers won't always need to think about parallelism and will eventually let the compiler do a good deal of it for us?)
This comment was marked helpful 1 times.

The difference between Implicit and Explicit SIMD is still not clear to me. First of all, what's a scalar binary? Also, isn't executing a function N times similar to having a independent for loop for N times? but the first case is categorized as Implicit while the latter is Explicit?
This comment was marked helpful 0 times.

I believe the difference is that in explicit SIMD, the compiler itself creates vector instructions (such as vstoreps and vmulps) which are single instructions that tell the machine to use multiple ALUs to deal with multiple data. In implicit SIMD, the compiler doesn't write the vectorized instructions and instead writes the serial instructions, and the CPU hardware looks at the instructions and figures out that it can use multiple ALUs to deal with multiple data.
So in the example, the forall loop is an explicit SIMD since when the compiler reaches there, it knows that it can vectorize the following instructions. When running a function N times, the compiler may not know if it can be vectorized, but when the CPU sees the instructions and decides to use multiple ALUs, then this is implicit SIMD.
This comment was marked helpful 0 times.

I'm not sure implicit SIMD is as magical as the CPU "figures out" to run scalar instructions as SIMD by looking at the instruction stream. This seems to suggest that regular code that may be parallizable but contains zero instructions to make it parallel would still be executed in parallel. My interpretation was that the CPU is explitly told to run a certain function N times and the hardware supports running each iteration in parallel, i.e. SIMD is inherent in the "run this function N times" bit.
This comment was marked helpful 0 times.
A wide SIMD width means it is more likely that you'll encounter divergence. (By the simple logic that if you have 32 things do, it is more likely that one will have different control flow requirements from the others than if you only have eight things do). When you have divergence, not all the SIMD execution units do useful work, because some of the units are assigned data that need not be operated upon with the current instruction.
Another way to think about it is worst-case behavior. On an 8-wide system, a worst-case input might run at 1/8 peak efficiency. While that's trouble, it's even more trouble to have a worst case input on a 32-wide system... 1/32 of peak efficiency! Uh oh.
So there's a trade-off: Wide SIMD allows hardware designers to pack more compute capability onto a chip because they can amortize the cost of control across many execution units. This yields to higher best-case peak performance since the chip can do more math. However it also increases the likelihood that the units will be not be able to used efficiently by applications (due to insufficient parallelism or due to divergence). Where that sweet spot lies depends on your workload.
3D graphics is a workload with high arithmetic intensity and also low divergence. That's why GPU designs pack cores full of ALUs with wide SIMD designs. Other workloads do not benefit from these design choices, and that's why you see CPU manufactures making different choices. The trend is a push to the middle. For example, CPU designs recently moved from 4-wide SIMD (SSE) to 8-wide SIMD (AVX) to provide higher math throughput.
This comment was marked helpful 0 times.
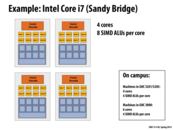


What is FLOPS here? anyone could please explain?
This comment was marked helpful 0 times.

FLOPS stands for for FLoating-point Operations Per Second. For programs that make heavy use of floating point number, such as scientific calculations, this is a better measurement than Instructions Per Second (IPS), as floating-point operations are more complicated and require more instructions.
This comment was marked helpful 0 times.
Floating point operations are implemented by single instructions on essentially all modern processors. In this diagram for the GTX 480, each yellow box can perform a 32-bit floating point multiply-add operation (result = a * b + c) in a single cycle.
It is true that a floating-point ALU certainly more expensive to build than an integer ALU in terms of chip area -- more transistors -- and in terms of power consumption during operation.
This comment was marked helpful 0 times.

I'm a bit confused on the difference between SIMD and ILP. Specifically, how can we have ILP without multiple ALUs to execute the parallel instructions?
This comment was marked helpful 0 times.
I believe the difference is that in SIMD, you are running the same instruction with multiple data (thus the name S(ingle)I(nstruction)M(ultiple)D(ata)). But in ILP (instruction level parallelism), you are executing several different instructions at the same time. And the CPU will use complicated logic to determine the dependencies and use a pre-fetcher to realize this.
This comment was marked helpful 0 times.
I'm still a bit confused; once ILP determines what can be parallelized, how does it run them at the same time? Context-switching?
This comment was marked helpful 0 times.
@snshah In the superscalar case, the processor exploits ILP by deciding which instructions are independent with each other (can be parallelized) within a single instruction stream. Then the processor feed independent instructions to different ALUs simultaneously and the ALUs can work in parallel. No context-switching is required because these instructions are from the same thread.
This comment was marked helpful 0 times.
OK, so to exploit ILP, you do need multiple ALUs.
This comment was marked helpful 0 times.
I am not sure about the usage of multi-core in this sin(x) example. When I used pthread before, I will gave each thread different start index, but I don't quite understand what's going on in this eample. silde 16
This comment was marked helpful 0 times.
@black The multithread program is computing sin(x) for vector x using taylor's series expansion. The main thread launches another worker thread that computes the first args.N numbers in x. Then the main thread act as a worker thread and computes the rest. (The "// do work" line between the two pthread function)
This comment was marked helpful 0 times.
A processor that supports superscalar execution is a processor that can fetch and decode multiple instructions per clock and then execute those instructions on different execution units (ALUs).
In the visual vocabulary of this lecture, a superscalar core would have multiple orange boxes.
Given a single thread of control, (where the program specifies no explicit parallelism), in order to use multiple execution units the processor must inspect the instruction stream to find instructions that don't depend on each other, and then it could execute those instructions in parallel. That is exploiting instruction-level parallelism in the instruction stream.
In contrast, consider an instruction stream with a SIMD vector instruction in it. The processor can fetch and decode this one instruction (one orange box), and then executes it on a SIMD execution unit (shown in my diagrams as a block of multiple ALUs). This unit, performs the desired operation on N different pieces of data at once.
This comment was marked helpful 0 times.
For those interested:
realworldtech.com tends to have technical, but quite accessible, articles that describe the architecture of modern processors. This article on Intel's Sandy Bridge architecture is a good description of a modern CPU. It's probably best to start at the beginning, but Page 6 talks about the execution units.
This comment was marked helpful 0 times.



Here's analogy, alluded to in class, for latency and bandwidth: Suppose the professor is requested to take some bits from one side of the classroom to the other.
He grabs two bits with each of his hands and walks to the other side, taking 10 seconds. The time it took for the data to reach the other side, or latency, is 10 seconds. His bandwidth will be 2 bits/10 seconds or 0.2 b/s The professor can instead run from one side to the other, taking 5 seconds. So his latency will be 5 seconds and his bandwidth will be 2 bits/5 seconds or 0.4 b/s.
The professor can grab a bag and stuff it with 5000 bits and run to the other side. His latency will be 5 seconds and his bandwidth will now be 1 kb/s. An interesting note here is that if the professor grabs 10000 bits and walks to the other side, his bandwidth will still be 1 kb/s but his latency will be 10 seconds.
An expansion of the interesting note is the latency and bandwidth of satellite internet. Satellite internet signals typically have to travel very far causing latency to be in the 1000ms region as opposed to 30ms average in regular terrestrial internet. This causes the 15MB/s uncongested satellite internet to still be slow for some web pages or games yet score high on bandwidth tests. This is also called the long fat network or LFN (also pronounced "elephant") and have been considered in the design of an extension to TCP/IP.
This comment was marked helpful 1 times.

Does physical distance between memory and the processor matter at all here? Not sure if this is a silly question, but of course with the analogy that Kayvon illustrated in class (of him walking back and forth at the front of the lecture hall), that would have been an obvious solution.
This comment was marked helpful 0 times.
@idl: in fact it does. Long wires increase cost, incur more energy to move data across, and suffer from longer communication latency. I bet Yixin has an even better answer. Yixin?
This comment was marked helpful 0 times.
@idl: Kayvon's analogy in class is just a demonstration of bandwidth and latency. For DRAMs in your laptop, the actual memory latency is dominated by wire/logic delays inside a memory module. Using numbers from JEDEC DDR3 standard, it takes 15-50 ns to get a cache line from DRAM modules, and only ~4 ns to transfer from DRAM to CPU.
This comment was marked helpful 0 times.
@kayvon @yixinluo I see, thanks!
This comment was marked helpful 0 times.
The latency of an operation is the time to complete the operation. Some examples:
- The time to complete a load of laundry is one hour. The time between placing an order on Amazon and it arriving on your doorstep (with Amazon prime) is two days.
- If you turn on a faucet (and you assuming the pipe connected to the faucet starts with no water in it) it's the time for water entering the far end of the pipe to arrive in your sink.
- If I type
ping www.google.comI get a round trip time of 30 ms, so I can estimate the latency of communicating between my computer and Google's servers is approximately 15 ms. - If there's no traffic on the roads, it takes 5 minutes to drive to Giant Eagle from my house, regardless of how wide the roads are.
- If a processor requests data from memory it doesn't get the first bit back for 100's of clocks.
Bandwidth is a rate, typically stuff per unit time.
- A bigger washer would increase your bandwidth (more clothes per hour)
- A wider pipe would increase the flow into your sink (more gallons per second)
- A multi-lane road increases bandwidth (cars per second)
- A fast internet connection gives you higher bandwidth (100 gigabits per second)
- Once memory receives a request, it responds by sending eight bytes per clock cycle over the memory bus.
Note in the above examples: there two ways you can increase the rate at which things get done: make the channel wider (get a bigger pipe, add lanes, a wider memory bus) and push stuff through it faster (increase water pressure, increase the speed limit, increase bus clock rate).
This comment was marked helpful 0 times.

Just to correct a typo and possibly have another comment added...LATENCY: the time "it" takes to complete an operation
This comment was marked helpful 0 times.


I don't think we discussed branch prediction in this lecture, but it's worth a quick overview.
The idea behind branch prediction is quite similar to the one behind pre-fetching; most programs have a predictable pattern of data access/conditional execution.
For example, a program that accesses data from an array usually does so in a linear fashion (from index 0 to , with increments of size 1). A program that instead does so in a near-random fashion would not be able to exploit the benefits that prefetching mechanisms provide.
Branch prediction works in the following fashion:
- The processor observes a branch impending by looking forward in the instruction stream (processors are able to fetch/decode multiple instructions simultaneously).
- After predicting which branch will be taken, the processor starts to fetch/decode instructions where it predicts the branch will go and will start to execute those instructions).
- When the branch is reached, the prediction is checked. If it was correct, the processor continues execution on the appropriate branch. If not, the processor has to reset the state (discard the results evaluated on the incorrect branch) and start fetching/decoding instructions on the correct branch.
In essence, this notion of 'discarding incorrect branch results' is quite similar to how incorrect branch results in a SIMD model of execution are discarded.
A rather famous example of how branch-prediction can lead to a significant speed-up (or slow-down, depending on how the code is written) can be found here (which incidentally also happens to feature the most voted up response on StackOverflow).
This comment was marked helpful 4 times.
Modern CPUs have hardware prefetchers that analyze the pattern of loads and stores a program makes in order to predict what addresses might be loaded in the future. Like branch prediction, or out-of-order instruction execution, this is done automatically and opaquely by the hardware without the knowledge of software. Earlier in this lecture I referred to these components of a processor by the technical term "stuff that makes a single instruction stream run faster".
However, most instruction sets (including IA64) do include prefetch instructions that can be emitted by a compiler to help deliver greater performance. These instructions are taken as "hints" by the processor. (It may choose to ignore them since remove a prefetch will not change program correctness.)
This comment was marked helpful 0 times.


Multithreading involves processing multiple threads one one core while you wait for memory. A single core may have multiple ALUs.
Question 1: It seems that the number of ALUs and the number of threads are unrelated, is that correct?
Question 2: When I look at my processor specifications online, it says that I have a dual-core processor, with hyperthreading. When I use a tool like CoreTemp, it shows 4 cores, implying that "hyperthreading" makes each core pretend to be two. Does that necessarily mean that each of my cores is capable of processing 2 threads, or is there some otter reason the number 2 shows up?
This comment was marked helpful 0 times.

Answer to question 1: The number of thread does not relate to the number of ALU. ALU handles multiple data SINGLE instruction. Handling multi-threads requires handling multiple instructions at the same time. So, it is different. Keep this point in mind when you do assignment 1; it would clear some of your confusions.
Answer to question 2: In short, the CPU architecture allows the OS to treat 1 physical core as 2 logical cores and schedule 2 threads per core. It is still different from having 2 physical cores. Such an increase in performance is achieved through smart scheduling and instruction execution. A quick reading from wiki would explain your question well: http://en.wikipedia.org/wiki/Hyper-threading
This comment was marked helpful 1 times.
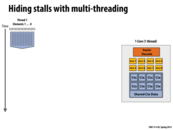
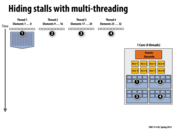
Last year, the Alex Reece nicely pointed out that a context switch in the OS sense is very different than the hardware context switch discussed on this slide. The former changes the thread that is running on a CPU and the latter changes the active execution context in the processor.
He posted this infographic where you can see the differences between some latencies over the past several years.
In the context of interleaved hardware multi-threading, you can safely think of a processor being able to switch the active execution context (a.k.a. active thread) every cycle.
Keep in mind that from the perspective of the OS, a multi-threaded processor is simply capable of running N kernel threads. In most cases, the OS treats each hardware execution context as a virtual core and it remains largely oblivious to the fact that the threads running within these execution contexts are being time multiplexed on the same physical core.
The OS does, however, need to have some awareness about how kernel threads are mapped to processor execution contexts. Consider the processor above, which has four cores, and can interleave execution of four logical threads on each core. Now consider a program that spawns four pthreads. It would certainly be unwise for the OS to associate the four pthreads onto four execution contexts on the same physical core! Then one core would be busy running the threads (interleaving their execution on its resources) and the other three would sit idle!
Last year I asked the following question, and got some nice responses:
Question: For those of you that have taken 15-410, can you list all that must happen for an OS to perform a content switch between two processes (or kernel threads)? It should quickly become clear that an OS process context switch involves quite a bit of work.
Post by lkung:
OS process context switching involves the overhead of storing the context of the process you're switching from (A) and then restoring the context of the process you want to switch to (B).
- saving A's registers
- restoring B's saved registers
- re-scheduling A, setting B as running
- loading B's PCB
- switching to B's PDBR, which usually flushes the TLB (resulting in misses when translating virtual -> physical addresses as the cache warms up again)
The 410 book (Operating System Concepts) says that typical context switch speeds are a few milliseconds (I have the 7th ed, so it may be a bit outdated). "It varies from machine to machine, depending on the memory speed, the number of registers that must be copied, and the existence of special instructions (such as a single instruction to load or store all register). Context-switch times are highly dependent on hardware support. For instance, some processors (such as the Sun UltraSPARC) provide multiple sets of registers. A context switch here simply requires changing the pointer to the current register set."
Post by dmatlack:
The state of the running process must be saved and the state of the next process must be restored:
- Storing all register values of the currently running process somewhere in kernel memory and then populating registers with the state of the next process. Included in the "state" of a process is all general purpose registers, the program counter, eflags register, data segment registers, etc.
- The page directory and tables must be swapped (which requires wiping the TLB).
Preceding this save-and-restore of state there is also work to be done in order to select the next runnable thread (scheduling) and some synchronization.
This comment was marked helpful 2 times.
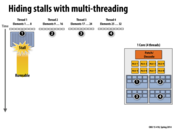
To extend the metaphor from class, the time between when the memory is finished loading and when the processor gets back to it is like the time when your laundry is done, but you (the processor) are busy watching Mad Men or doing some otter thing.
Also, I'd like to draw attention to how the threads are labeled as loading 8 elements at once. That answered one of the otter questions I had about whether the number of threads relates to the number of ALUs.
This comment was marked helpful 0 times.
There is no such thing as a 'free lunch' when it comes to designing processors (ie deciding how to allocate transistors to various components).
We already talked about how removing the components that made a single core run faster (such as large cache memories, pre-fetchers, branch predictors, etc) enables us to add more cores (albeit slower than our single fast core), leading to potential speedup.
That design decision 'raises its head' when we try to reduce latency arising from processor stall, as large cache memories and pre-fetchers play a role in reducing latency, but our decision to opt for multiple cores instead reduces the latency-reducing/hiding power of such components.
Even the usage of multi-threading has potential problems that may yield latency:
a) In order to run multiple threads on a single core, we need more 'execution context units'. For a given registers/virtual memory that can be used for execution context, a greater number of individual units will reduce the amount of resources to any one thread. A thread that has many independent variables may have its data 'spill-over' into slower memory units, leading to latency.
b) Each thread also takes longer to run (as there is a period of time where other threads are running on the same core, while the high-latency operation on the thread that initially stalled has completed). I'm not sure, but if the memory latency is sufficiently small, this may result in lower performance (or at least, worse performance than what could be achieved).
There could be some problems if the work is poorly distributed as well.
Question: How would a processor determine whether or not the latency involved is sufficient to warrant switching to another thread? Or is switching to another thread in the light of a stall, no matter how small, better than doing nothing (when considering a multi-core system).
This comment was marked helpful 0 times.
@arjunh I'm not sure if this is correct, but I think if I were to be the processor, I would probably check if the stall comes from a thread fetching data from cache (which level) or memory, the time could therefore be estimated. Since it seems like the minimum time for memory latency still could far longer than to execute instructions of another thread.
This comment was marked helpful 0 times.
@arjunh You raised a very good question. There is a trade off between context switching and waiting. If you switch, you have to pay the cost of storing and loading the context as well as draining and filling the pipelines, this is expensive when you have a lot of registers and a very deep pipeline. As you have mentioned, switching threads also pollutes the cache and TLB, and can have a QoS problem (A thread with a lot of memory access will run much slower than a thread with few memory access). However, if you not switch, you are paying the opportunity cost of utilizing the processor when the thread is waiting.
Also, it is important to note that GPUs does not have any of the problems above, so always switching threads works well for GPUs. GPUs have multiple context stores on chip that are quick to access; small number of registers; very short pipeline; small cache; no TLB; all threads are identical.
It is also important to note that the type of multithreading on this slide does not apply to any CPU product today. Whether to switch or not on CPUs remains an open research question. If you are interested, the type of processors that does what @analysiser says is called SoEMT processors, or coarse-grained multithreading processors.
This comment was marked helpful 2 times.

In the class, professor mentioned that scheduling on multi-threaded processors is now an active research area. It seems that commonly-used OS are still using strategies invented more than 10 years ago. Is there any promising progress in this field?
This comment was marked helpful 0 times.
@squidrice Thread scheduling becomes more interesting after the introduction of chip multiprocessors (CMP) in early 2000s. Several reasons why they becomes interesting: 1. Multiple cores share on chip resources (Last-Level Cache, memory bandwidth) and interfere with each other. This one also applies to GPUs. 2. When multithreaded applications run on CMPs, they may contend each other for shared data and locks. 3. These problem becomes even more interesting if we have one or more cores more powerful than the others (Heterogeneous multicore).
Here are some references to recent publications studying these problems: Talk to us if you are interested.
Memory Interference:
Muralidhara, Sai Prashanth, et al. "Reducing memory interference in multicore systems via application-aware memory channel partitioning." Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. ACM, 2011.
Lock Contention:
Du Bois, Kristof, et al. "Criticality Stacks: Identifying Critical Threads in Parallel Programs using Synchronization Behavior." (2013).
GPU:
Rogers, Timothy G., Mike O'Connor, and Tor M. Aamodt. "Cache-conscious wavefront scheduling." Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE Computer Society, 2012.
This comment was marked helpful 0 times.

I assume that what we're talking about here is hardware multithreading and not kernel/OS multithreading. From the kernel's point of view (C or assembly), I don't see a way to tell if a certain instruction/memory lookup is going to cause a stall, because that's a lower level concept. This would need to be implemented in hardware. Further, then, I assume that this type of thing is the point of so-called hyperthreading.
I imagine the kernel would be more preoccupied with higher level scheduling, and would express to the processor that a certain set of threads are to be run on the same core, allowing the processor to handle the within-core scheduling.
This comment was marked helpful 1 times.

How relevant is this, from a programmer's perspective? I gather from above comments that this strategy is not found in today's hardware. If such hardware becomes available, how can it be exploited?
Further, does the same idea extend to other sources of latency (e.g. network/disk)? I would imagine that in those cases, the latency becomes much larger than the overhead of software context switches.
This comment was marked helpful 0 times.
@eatnow. I certainly wouldn't tell you about it if it didn't exist! ;-) The idea of hardware multi-threading is present in forms in all Intel CPUs (Hyper-threading, which features two hardwar-managed execution contexts per core), all modern GPUs (at a large scale... e.g., 10's of execution contexts per core, see slide 55), and in other popular processors like the SUN UltraSparc T2.
You are also correct that for very large latency operations such as accessing disk, the latency is so large that it's acceptable to implement the context switch in software (the OS performs it). The idea of hardware multi-threading is that some latencies are too short to be able to invoke the OS (e.g., a cache miss), but critical enough to performance that the hardware should manage latency hiding itself.
This comment was marked helpful 2 times.

It seems that reducing the cost of context-switching for each core can be achieved by assigning threads with a lot of shared data to the same core (so that all the memory they need to access can be kept in the L1 cache). Are threads assigned to cores based on which has the least to do at the moment, or with consideration to making context-switching efficient?
This comment was marked helpful 1 times.

@benchoi The Linux kernel schedules threads onto cores based on idleness of the core, but it also takes into account the cache heirarchy of the hardware - for example, a dual socket motherboard with two Intel i7-920's will have 4 cores sharing an L3 cache and another 4 cores sharing the other L3 cache, so moving a thread from one socket (which has one L3) to another socket (having a different L3) is expensive - the kernel knows this. The same goes for a NUMA computer, where the kernel knows that memory attached to a different node is far away and should avoid sending a thread across nodes if possible.
The kernel might also take into account power considerations - for example, one core might be lightly loaded at 10% utilization, and another is completely idle, so it has entered a power saving state. and another thread needs to run. The kernel might schedule the thread on the one lightly loaded core, which causes the two threads to contend for resources, but saves power, or it might schedule the thread on the sleeping core, causing more power usage. This is adjustible in the Linux kernel (google sched_mc_power_savings)
This comment was marked helpful 1 times.
Here's my understanding/summary of the discussion on hardware multithreading vs multithreading:
Hardware multithreading is when we have multiple threads on 1 core, each having its own execution contexts, but all the threads are sharing the fetch and decode units and the ALUs. This is why we have interleaved execution of these 4 threads since they are all dependent on the same fetch and decode units and ALUs. When we need to switch between these threads, we don't need to flush out the data since we simply choose to read the instructions necessary for a different thread and work in the appropriate execution context. Since there is minimal transfer of execution context data, this is very cheap (in terms of latency for this hardware multi threading switch). As a result, the CPU can manage this and take advantage of it by switching to a different execution context when there is a small latency such as an L2 cache miss when 1 of the threads is executing.
An OS context switch occurs when we need to switch out a thread running on an execution context entirely and run a different threads. This means that all the data in the execution context needs to be flushed out (as stated in greater detail on the previous slide's comments) and this is where the OS comes in. It is also more expensive and it is therefore best to be executed during large latency operations like reading from disk.
This comment was marked helpful 0 times.


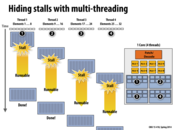
As Kayvon has stated in the lecture, the throughput of a system in which all the cores and ALU's don't go idle would be optimal and I think this is the key idea.
This comment was marked helpful 0 times.

In high-throughput computing, we are less concerned with how fast one task can be computed but instead more concerned with how many tasks can be computed in longer period of time. This is different from for example high-performance computing which deals with shorter periods of time of computing.
This comment was marked helpful 0 times.

I'm not sure if this point is relevant here, but if we imagine we have some thread that is very time sensitive and must finish before a fixed deadline, would throughput computing hurt that particular thread since it becomes less predicable when that thread will resume running. Could it be bad for that thread which might have a higher priority to wait for the other threads? Is there a notion of priority in the hardware to influence the decision of which thread to run?
This comment was marked helpful 0 times.
@ruoyul: Yes, as evidenced by this slide, maximizing system throughput in situations where there are many things to do comes at the cost of minimizing the latency (time to completion) of any one of those things. So yes, your concern is a valid one. Setting priorities is certainly one way to tell the scheduler, "I care about getting this thing done!" In this example, the slide's scheduling scheme is a round-robin one. Quite fair since it assumes all threads have equal priority, but perhaps not the most efficient approach when certain pieces of work have different requirements.
This comment was marked helpful 0 times.
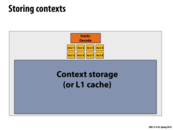
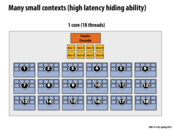
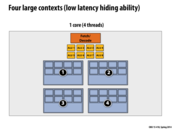
Can't you have arbitrarily many threads no matter how many contexts you have? Then you just need a context switch, right?
This comment was marked helpful 0 times.
@sbly Correct, you can store arbitrarily many thread contexts in memory. These on-chip contexts are for reducing the context switch latency. You can view them as explicit caches for thread contexts.
This comment was marked helpful 0 times.
Also, I asked the same question to the TA. And he said that basically you could have many threads on the OS level and then OS will do one level of context switching to avoid memory-disk or network latency etc. But on the CPU level if you have 4 contexts then you can run up to 4 threads without going to the memory. I just thought this two layers of hiding latency is fascinating and worth sharing.
This comment was marked helpful 0 times.

I think what you all are saying above is that you are allowed to have multiple threads per context instead of one thread per context as these slides seem to imply. However, constantly context switching between multiple threads pollutes the cache each time you switch from one thread to the other, causing you to go to memory to keep updating the cache much more frequently than if there was only one thread per context. As we saw in lecture in the visual representation, having to go to memory takes much longer than having to access cache, so to hide the latency your best bet is to have a numerous threads per context or one per context but nothing in between. Is it correct to be equating "on-chip context" to "explicit cache for thread contexts" as the people did above and I did in my comment?
This comment was marked helpful 0 times.


From what I understand about operating system context switches, the OS suspends execution of one thread on the CPU and resuming execution of some other thread that had previously been suspended.(Lets say system only has 1 core with enabled multi-threading) However, in these slides, it seems that each core has control over what thread it wants to devote execution resources to at any given time. My question is about how the OS synchronizes its job handling with the processors.
If the OS suspends a thread that happens to be running on CPU A, does it signal to CPU A to not context switch to that specific thread until the OS resumes it? Does the CPU run suspended threads and just not deliver the result to the OS or does the OS replace the thread running on the core with a new thread and save the old context?
In general, I'm pretty unclear about how hardware-supported multi-threading interacts with software-supported multi-threading.
This comment was marked helpful 3 times.
@vrkrishn First of all, your last question is a very good question, and your understanding about software context switch in the first paragraph is correct.
To answer your question, I should clarify what a hardware context switch is and how it is different from a software one. Hardware Context Switches (HCS as Yixin's Abbreviation), by definition, are triggered by hardware events; Software Context Switches (SCS) are triggered by software. Hardware events (such as last level cache misses) are much more frequent than software events (OS scheduler triggered every 10-100 ms). This is why HCSes are usually made to have lower overhead than software context switches: HCSes make very simple scheduling decision (such as round robin) without any software help (no interrupts) and usually switch between a bounded number of thread contexts stored on chip.
Going back to your question, how does hardware and software thread management interact? As introduced above, HCS usually switches between limited number of thread contexts, let's call them hardware threads. Software thread schedulers assign software threads to hardware threads every 10-100 ms. Then the processor can pick whichever hardware thread they can run and switch quickly between them.
For your questions in second paragraph, you already have the answer in your last question. When OS suspends a thread, it will save the old context to memory then schedule a new thread.
Also see the discussion about hyper-threading on slide 64.
This comment was marked helpful 5 times.
Following from the previous question, it then seems that it is sub-optimal to spawn more threads in a single core than the underlying hardware supports. Is that correct? Not to say that you can't have as many threads as you want, but if you do have more threads than the hardware supports, then the OS does a software intervention of handling all the threads, and swaps thread contexts back and forth between memory and the hardware (slow).
This comment was marked helpful 0 times.
A funny note about hyper-threading:
In one instance Intel didn't implement it completely bug free: https://bugs.freedesktop.org/show_bug.cgi?id=30364
If hyper-threading is enabled, for some reason the v-sync interrupt from the GPU would not be capable of waking the CPU from a sleep state...
buggy hardware FTL...
This comment was marked helpful 0 times.
More modern OS's have system calls that can be used to set the affinity of a thread. A thread's affinity specifies (or strongly hints at) what physical execution resource it should be mapped to. For example, if you are interested in mapping a pthread to a particular processor you may be interested in the pthread library function pthread_getaffinity_np().
You can also set the affinity of a process using sched_setaffinity().
A cool comment from last year:
You can also reconfigure the scheduler using sched_setscheduler. The SCHED_FIFO scheduler is (roughly) a cooperative scheduler, where your thread will run until you block on IO or call sched_yield (or a higher priority process becomes runnable).
This comment was marked helpful 0 times.
If you log into the machines in Gates 5201/5205 and type less /proc/cpuinfo you'll get a report about the processor. The Intel CPUs in those machines have four cores, but hyper-threading is disabled in their current configuration, so the cpuinfo report states there are four cores.
The Intel CPUs in the Gates 3000 machines have six cores, but hyper-threading is enabled. You'll find cpuinfo will report 12 logical cores although there are only 6 physical ones. In the terms I used in class, the CPU has 6 cores, but manages up to 12 independent hardware thread execution contents.
This comment was marked helpful 0 times.
I'm a little confused about simultaneous multi-threading. For Intel Hyper-threading (2 threads per core), does that mean there are two execution contexts in the core, and two threads can run in parallel so that there is no context switch?
This comment was marked helpful 0 times.
@yihuaz: Please see the discussion about hyper-threading on slide 64.
This comment was marked helpful 0 times.


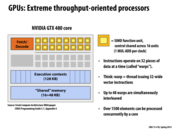



The professor gave an interesting fact that the reason for the GTX 480 to only contain 15 cores is due to hardware defects screened out by NVIDIA. When a processor is fabricated and tested, if a core did not pass NVIDIA's tests, the core can be disabled and the chip rebranded as a lower end chip. An interesting fact is that sometimes you can "Unlock" a graphics card core with a EEPROM flash, if it hasn't been laser cutted disabled. An example case here is the GTX 465 which is just a GTX 470 with some cores disabled (and possibly lasered off).
This comment was marked helpful 1 times.
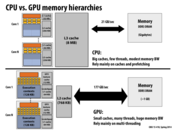

768 = 2^8 * 3. Is there any reason why L2 is that big for GPU or is it just an Empirical result?
This comment was marked helpful 0 times.

I know some NVIDIA GPUs have 768 KB L2 caches, but I don't know why NVIDIA picked that. I would imagine it's because they intended to minimize the cache size in order to make as much room as possible for cores/ALUs etc. 768 may be the magic number they found that provides physical space on the chip, meets their minimum requirements for memory usage, and works out with powers of two.
This comment was marked helpful 0 times.
Chip architects make decisions by running experiments are real workloads. I suspect that benchmarks showed the for many GPU workloads larger caches had decreasing benefits, and that chip area was better used, as @rbariso suggests, for adding other capabilities.
Question: What mechanisms do GPUs use to avoid performance problems that might arise if a CPU-style processor was attached to such a small last-level cache?
This comment was marked helpful 0 times.

GPU program working sets are typically much larger than CPUs. This is why it makes sense for CPUs to have a large cache and the GPU a small one; the CPU can usually fit the working set into its last level cache whereas this is usually unrealistic for a GPU. GPUs get around this by having massive memory bandwidth. They may not be able to store everything in their cache, but they can access memory fairly easily. Because CPUs have large caches, less die area is spent on a high throughput memory controller. However if a CPU were to be hooked up to a GPU memory system, reasonable performance could probably still be expected due to the massive memory bandwidth, though perhaps not as good as with the typical CPU cache architecture.
This comment was marked helpful 0 times.
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.

The implications depend on the extent to which a reduction in input size correlates to a reduction in latency. For example, if our PCIe bus runs at 16 GB/s, then every transfer to memory could (absent other data) potentially take a full second, but we can run 16B transfers simultaneously. At best, we could run a single transfer in 1/16B seconds. Given that GPUs probably have an average workload equal to the number of pixels in a screen (roughly 1024^2 = 1MB of data), this means it would optimally take 1M / 16B = 1 / 16K, or 16K transfers per second. Since most GPU applications only require at most 60 frames per second, I'd say we're doing pretty well for ourselves even with a bandwidth of 16 GB/S (or worse).
Granted, this is assuming optimal conditions and an average workload. I'm not sure of other use cases for which this might have more dire implications.
This comment was marked helpful 0 times.


Is it a correct interpretation that this is kind of a neutral program, in that if you had 2 programs to run, you would run this on the GPU if the other program was efficient on the CPU and vice versa?
Also, it doesn't seem like for this particular problem there'd be any way to exchange increased math operations for decreased memory usage (while that could be used to make some other programs more parallel). Is this accurate?
This comment was marked helpful 0 times.

We were asked the following question in class - "Would this program run 'better' on a CPU or a GPU?"
One might think that due to a GPU having a complex system of multiple cores, multiple ALUs per core, and a nice setup for SIMD usage, that a GPU would be superior to a CPU.
A GPU would be faster than a CPU for this example, but not primarily because of the high core/ALU count. A GPU would be faster because it has a wider bus, and therefore higher bandwidth.
GPUs are capable of doing a lot of stuff in parallel very quickly, but if our only operation is a itty-bitty MUL, the GPU spends most of its time just sitting around and waiting for the bus to bring A and B in, and to take C away.
With the example of the NVIDIA GTX 480 GPU, if we were able to magically double the amount of wires connected to main memory, yet keep the exact same number of cores/ALUs, we would potentially halve the execution time of this program.
This comment was marked helpful 0 times.
I don't quite understand why GPU is more efficient that CPU in above context. Would somebody explain the phrase '~2% efficiency... but 8x faster than CPU!'?
This comment was marked helpful 0 times.

One thing I was thinking that wasn't mentioned in class was that the CPU has a much larger cache than the GPU does. This program seems like it would utilize a cache well, since the array elements would be stored next to each other in memory. So even if the CPU is slower overall, would getting A and B and storing C take less time with the CPU because of its larger cache? Or does that not really matter because the GPU has higher bandwidth?
This comment was marked helpful 0 times.
@taegyunk I do not this slide suggests a conclusion to whether GPU is more efficient or CPU is more efficient. All this slide states is that both GPU and CPU are not efficient due to constraints of memory bandwidth.
Efficiency measure how well the program is utilizing all the existing cores. Due to memory bandwidth constraint, the GPU is only capable of achieving ~2% of the efficiency . The GPU may perform the same operations faster than the CPU can perform simply because GPU has more cores and this problem is ridiculously parallelizable. Therefore, the overall performance of GPU is ~8x faster.
This comment was marked helpful 0 times.
@jmnash Be careful with the assumption you are making in the statement. It is true that a CPU has a larger cache than that of a GPU, but will this fact influence the performance of the program significantly?
First of all, write cache miss usually does not penalize the performance (depends on the cache writing policy) since the memory write can be queued and the processing unit (CPU or GPU) can continue the operations without stall. However, in this problem, the issue is that the memory bandwidth does not allow the processing units to perform more operations. Assume A and B are two different arrays with no overlapping locations and all elements in these 2 arrays are not inside the cache(starting with a cold cache), each element of the array need to be fetched from the memory. The mem read instructions are not faster. We still do not improve the performance or efficiency.
If both A and B can be fitted into CPU's cache but not into the GPU's cache, and starting with A and B already in the cache, we may observe a improvements in performance and efficiency from CPU.
This comment was marked helpful 0 times.

@yihuaf @taegyunk
The reason that the GPU is 8x faster in this case is simply that it has a wider bus.
See the speeds of GPU and CPU busses.
$$
\frac{177\text{GB/s}}{21\text{GB/s}} \approx 8
$$
Both the CPU and GPU are both limited by the bus width for this example.
This comment was marked helpful 0 times.

Is $$\approx 177Gb/s$$ the top of the state in bus speeds right now? Or is it that we CAN make a faster bus, but applications we use do not really call the need for it?
Interesting question: when performing a task like above, when is it better to use a distributed systems approach then a parallel computing approach? I think if we are cost-constrained, then it would be better to use a distributed systems approach, since (I think) it is cheaper to use multiple cheap machines then a supercomputer.
This comment was marked helpful 0 times.

Are there debugging tools to see memory bandwidth utilization and latency? For example, if I had an application that spawns X threads to read data and each thread writes to disk, is there a tool that I could use to tweak X to try and find the highest bandwidth utilization?
This comment was marked helpful 0 times.

@nbatliva It looks like Intel has a very expensive piece of software that can be used to measure this:
But, if I understand this correctly, I imagine you might be able to use something like XPerf on Windows to look at the CPU utilization (over a period of time) of the thread that you care about, i.e. the thread that you want to be working all the time. If it looks like the thread spends most of its time on the CPU with "good utilization" or that it fully uses the CPU, then it might be reasonable to conclude that it is being serviced with enough memory. Furthermore, if it looks like the CPU utilization doesn't increase while you spawn more threads, then you might be able to conclude that you have achieved the highest bandwidth utilization.
This comment was marked helpful 0 times.


Just to be clear, this was basically the reasoning for why Part 5 of Assignment 1 did not have as much speedup as we were expecting, right? And organizing computation to request data less often would have been one of the ways we could increase speedup.
Are there any other ways to increase speedup?
This comment was marked helpful 0 times.

I agree that bandwidth is why we didn't have as much speedup as expected on part 5. There was additional discussion on part 5 on Piazza, here.
This comment was marked helpful 0 times.

So this seems like it could be better in some cases if we request large amount once then request small amount several times. What would be deciding the boundary between the amount of data requested the frequency of request?
This comment was marked helpful 0 times.


I did not get what is simultaneous multi-threading? Is it multiple threads on multiple cores?
This comment was marked helpful 0 times.
@yetianx: Simultaneous multi-threading (also known as hyper-threading in the Intel context) is a form of multi-threading where a single core chooses multiple instructions from multiple threads to run on its ALU's. This is different from interleaved multi-threading, which is effectively what we discussed here
Here's an example taken from wikipedia to explain the difference:
interleaved multi-threading:
- Cycle i: an instruction from thread A is issued
- Cycle i+1: an instruction from thread B is issued
- Cycle i+2: an instruction from thread C is issued
simultaneous multi-threading:
- Cycle i : instructions j and j+1 from thread A; instruction k from thread B all simultaneously issued
- Cycle i+1: instruction j+2 from thread A; instruction k+1 from thread B; instruction m from thread C all simultaneously issued
- Cycle i+2: instruction j+3 from thread A; instructions m+1 and m+2 from thread C all simultaneously issued
This comment was marked helpful 5 times.
More generally, simultaneous multi-threading involves executing instructions from two threads in parallel on a single core. In class, I mainly described interleaved multi-threading, but notice that there is also simultaneous multi-threading being performend by the NVIDIA GPU on slide 57 Each clock, the chip selects two of the up-to-48 runnable execution contents ("warps") and executes the next instruction in each of these streams. So there is interleaved multi-threading in that the chip interleaves up to 48 contexts, and simultaneous multi-threading in that it chooses two of those contexts to run each clock.
Intel's Hyper-threading implementation makes sense if you consider the context: Intel had spent years building superscalar processors that could perform a number of different instructions per clock. But as we discussed, it's not always possible for one instruction stream to have the right mixture of independent instructions to utilize all he available units in the core (the case of insufficient ILP). Therefore, it's a logical step to say, hey, to increase the CPU's chance of finding the right mix, let's have two threads available to choose instructions from instead of one!
Of course, running two threads is not always better than one, since these threads might thrash each other's data in the cache resulting in more cache misses that ultimately cause far more stalls than Hyper-Threading could ever hope to fill. On the other hand, running two threads at once can also be beneficial in terms of cache behavior if the threads access similar data. One thread might access address X, bringing it into cache. Then, if X is accessed by the other thread for the first time, what normally would have been a cold miss turns out to be a cache hit!
This comment was marked helpful 1 times.
Question: This is a good comment opportunity: write a definition for one of these terms!
This comment was marked helpful 0 times.
Here's a couple definitions:
- Multi-core processor: a processor with multiple cores (lol). A core is an independent computing unit with its own set of ALUs/caches/etc.
- SIMD execution: single instruction multiple data, where we use vector instructions to apply a single instruction across a data set of > 1 elements.
- Coherent control flow: assuming this is the same as coherent execution, coherent control flow means the same instruction sequence applies to all elements operated on simultaneously
- Interleaved multithreading: a core emulates running multiple threads by switching between their instruction streams at scheduled intervals
- Simultaneous multithreading: actually running multiple instruction streams at the same time on one core
This comment was marked helpful 1 times.
The rest of the definitions:
- memory latency: amount of time for a for a memory request to complete.
- memory bandwidth: how much memory requests can complete per second. So this is the rate at which memory requests can be serviced.
- bandwidth bound application: an application that requests memory at a rate that the system can't handle, and thus the performance of the application is bound by the bandwidth.
- arithmetic intensity: basically how much math is done per memory request. The lower this number, it will be more likely for the application to be bandwidth bound. Think back to saxpy.
This comment was marked helpful 1 times.
Single-instruction-stream performance topped out because the optimizations have gotten better and better over time, to the point where no significant improvement is really possible. In instruction sets where many instructions are dependent on previous instructions, not much of the code can actually be optimized by trying to find instruction-level parallelism. Even with compilers trying to find parallelism in more clever ways, like searching for instructions in different parts of a program that can be executed in parallel, it's gotten to the point where improving ILP requires a lot of effort for little gain.
Two of the main problems were (1) communication overhead and (2) uneven work distribution. When adding a set of numbers together, processors can compute components of the problem in parallel, but ultimately must combine their components to generate the final sum. This requires them to communicate their results, and there are costs associated with communication between processors. If the communication to computation ratio for each processor is high, then parallelism can be no more efficient or even less efficient than a sequential addition. In addition, when a program is run in parallel, the speed is limited by the processor with the longest computation. Therefore, if one processor has been assigned most of the work, then all the other processors have to wait for that one to finish before their results can be joined together. If one processor is assigned 90% of the original work, for example, then the parallel version of the program will be achieve at most 1.11x speedup or so, not factoring in other potential costs of parallelism. So, uneven distributions of work among the processors also prevents maximum speedup.
This comment was marked helpful 3 times.
@arsenal: Good! But one clarification. You meant to say instruction streams, not instruction sets!
This comment was marked helpful 0 times.