I've always heard that branching inside a shader should be avoided like the plague. I always just assumed that GPUs were just bad at branch prediction, but now I realize that a situation like this could also hurt shader performance. There's a pretty cool stackoverflow entry on this topic, and the top answer talks a little bit about nVidia's warps. Nifty.
This comment was marked helpful 0 times.
rharwood
From the article you linked, it sounds more like they're not bad at branch prediction but that it's nonexistent:
On the GPU things a little different; the pipeline are likely to be far shallower, but there's no branch prediction and all of the shader code will be in fast memory -- but that's not the real difference.
This comment was marked helpful 0 times.
kayvonf
Regardless of whether branch prediction is present or not (and this certainly depends on the details of GPU implementations--which are often not available to the public), it is certainly true that any branch prediction that exists will certainly be simpler than the sophisticated predictors in modern CPUs. Rather than strive for high-quality prediction, GPU architects (wisely thinking about their anticipated workloads) concluded that it would be more efficient to use transistors for other features, such as wider SIMD, more cores, special instructions to accelerate graphics, etc.
For the architecture folks in the class: My understanding is that most modern GPUs do not branch predict. The pipeline stalls that might result from a misprediction can easily avoided using another mechanism that is present on GPUs. Question: What is the mechanism GPUs rely heavily on to avoid stalls? (Note this reasoning also explains why sophisticated techniques like out-of-order execution, pipeline forwarding, etc. are less critical in a GPU core. since the cores can be simpler, there can be more of them.)
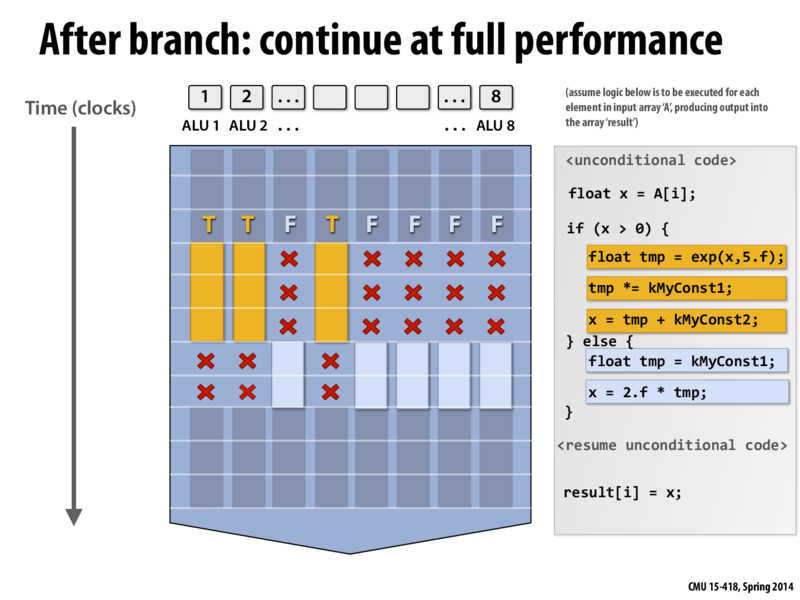
I've always heard that branching inside a shader should be avoided like the plague. I always just assumed that GPUs were just bad at branch prediction, but now I realize that a situation like this could also hurt shader performance. There's a pretty cool stackoverflow entry on this topic, and the top answer talks a little bit about nVidia's warps. Nifty.
This comment was marked helpful 0 times.
From the article you linked, it sounds more like they're not bad at branch prediction but that it's nonexistent:
This comment was marked helpful 0 times.
Regardless of whether branch prediction is present or not (and this certainly depends on the details of GPU implementations--which are often not available to the public), it is certainly true that any branch prediction that exists will certainly be simpler than the sophisticated predictors in modern CPUs. Rather than strive for high-quality prediction, GPU architects (wisely thinking about their anticipated workloads) concluded that it would be more efficient to use transistors for other features, such as wider SIMD, more cores, special instructions to accelerate graphics, etc.
For the architecture folks in the class: My understanding is that most modern GPUs do not branch predict. The pipeline stalls that might result from a misprediction can easily avoided using another mechanism that is present on GPUs. Question: What is the mechanism GPUs rely heavily on to avoid stalls? (Note this reasoning also explains why sophisticated techniques like out-of-order execution, pipeline forwarding, etc. are less critical in a GPU core. since the cores can be simpler, there can be more of them.)
This comment was marked helpful 0 times.
@kayvonf: multi-threading?
This comment was marked helpful 2 times.
@iamk_d__g:multi-threading+1
This comment was marked helpful 0 times.