To extend the metaphor from class, the time between when the memory is finished loading and when the processor gets back to it is like the time when your laundry is done, but you (the processor) are busy watching Mad Men or doing some otter thing.
Also, I'd like to draw attention to how the threads are labeled as loading 8 elements at once. That answered one of the otter questions I had about whether the number of threads relates to the number of ALUs.
This comment was marked helpful 0 times.
arjunh
There is no such thing as a 'free lunch' when it comes to designing processors (ie deciding how to allocate transistors to various components).
We already talked about how removing the components that made a single core run faster (such as large cache memories, pre-fetchers, branch predictors, etc) enables us to add more cores (albeit slower than our single fast core), leading to potential speedup.
That design decision 'raises its head' when we try to reduce latency arising from processor stall, as large cache memories and pre-fetchers play a role in reducing latency, but our decision to opt for multiple cores instead reduces the latency-reducing/hiding power of such components.
Even the usage of multi-threading has potential problems that may yield latency:
a) In order to run multiple threads on a single core, we need more 'execution context units'. For a given registers/virtual memory that can be used for execution context, a greater number of individual units will reduce the amount of resources to any one thread. A thread that has many independent variables may have its data 'spill-over' into slower memory units, leading to latency.
b) Each thread also takes longer to run (as there is a period of time where other threads are running on the same core, while the high-latency operation on the thread that initially stalled has completed). I'm not sure, but if the memory latency is sufficiently small, this may result in lower performance (or at least, worse performance than what could be achieved).
There could be some problems if the work is poorly distributed as well.
Question: How would a processor determine whether or not the latency involved is sufficient to warrant switching to another thread? Or is switching to another thread in the light of a stall, no matter how small, better than doing nothing (when considering a multi-core system).
This comment was marked helpful 0 times.
analysiser
@arjunh I'm not sure if this is correct, but I think if I were to be the processor, I would probably check if the stall comes from a thread fetching data from cache (which level) or memory, the time could therefore be estimated. Since it seems like the minimum time for memory latency still could far longer than to execute instructions of another thread.
This comment was marked helpful 0 times.
yixinluo
@arjunh You raised a very good question. There is a trade off between context switching and waiting. If you switch, you have to pay the cost of storing and loading the context as well as draining and filling the pipelines, this is expensive when you have a lot of registers and a very deep pipeline. As you have mentioned, switching threads also pollutes the cache and TLB, and can have a QoS problem (A thread with a lot of memory access will run much slower than a thread with few memory access). However, if you not switch, you are paying the opportunity cost of utilizing the processor when the thread is waiting.
Also, it is important to note that GPUs does not have any of the problems above, so always switching threads works well for GPUs. GPUs have multiple context stores on chip that are quick to access; small number of registers; very short pipeline; small cache; no TLB; all threads are identical.
It is also important to note that the type of multithreading on this slide does not apply to any CPU product today. Whether to switch or not on CPUs remains an open research question. If you are interested, the type of processors that does what @analysiser says is called SoEMT processors, or coarse-grained multithreading processors.
This comment was marked helpful 2 times.
squidrice
In the class, professor mentioned that scheduling on multi-threaded processors is now an active research area. It seems that commonly-used OS are still using strategies invented more than 10 years ago. Is there any promising progress in this field?
This comment was marked helpful 0 times.
yixinluo
@squidrice Thread scheduling becomes more interesting after the introduction of chip multiprocessors (CMP) in early 2000s. Several reasons why they becomes interesting:
1. Multiple cores share on chip resources (Last-Level Cache, memory bandwidth) and interfere with each other. This one also applies to GPUs.
2. When multithreaded applications run on CMPs, they may contend each other for shared data and locks.
3. These problem becomes even more interesting if we have one or more cores more powerful than the others (Heterogeneous multicore).
Here are some references to recent publications studying these problems:
Talk to us if you are interested.
Memory Interference:
Muralidhara, Sai Prashanth, et al. "Reducing memory interference in multicore systems via application-aware memory channel partitioning." Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. ACM, 2011.
Lock Contention:
Du Bois, Kristof, et al. "Criticality Stacks: Identifying Critical Threads in Parallel Programs using Synchronization Behavior." (2013).
GPU:
Rogers, Timothy G., Mike O'Connor, and Tor M. Aamodt. "Cache-conscious wavefront scheduling." Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE Computer Society, 2012.
This comment was marked helpful 0 times.
spjames
I assume that what we're talking about here is hardware multithreading and not kernel/OS multithreading. From the kernel's point of view (C or assembly), I don't see a way to tell if a certain instruction/memory lookup is going to cause a stall, because that's a lower level concept. This would need to be implemented in hardware. Further, then, I assume that this type of thing is the point of so-called hyperthreading.
I imagine the kernel would be more preoccupied with higher level scheduling, and would express to the processor that a certain set of threads are to be run on the same core, allowing the processor to handle the within-core scheduling.
This comment was marked helpful 1 times.
eatnow
How relevant is this, from a programmer's perspective?
I gather from above comments that this strategy is not found in today's hardware.
If such hardware becomes available, how can it be exploited?
Further, does the same idea extend to other sources of latency (e.g. network/disk)? I would imagine that in those cases, the latency becomes much larger than the overhead of software context switches.
This comment was marked helpful 0 times.
kayvonf
@eatnow. I certainly wouldn't tell you about it if it didn't exist! ;-) The idea of hardware multi-threading is present in forms in all Intel CPUs (Hyper-threading, which features two hardwar-managed execution contexts per core), all modern GPUs (at a large scale... e.g., 10's of execution contexts per core, see slide 55), and in other popular processors like the SUN UltraSparc T2.
You are also correct that for very large latency operations such as accessing disk, the latency is so large that it's acceptable to implement the context switch in software (the OS performs it). The idea of hardware multi-threading is that some latencies are too short to be able to invoke the OS (e.g., a cache miss), but critical enough to performance that the hardware should manage latency hiding itself.
This comment was marked helpful 2 times.
benchoi
It seems that reducing the cost of context-switching for each core can be achieved by assigning threads with a lot of shared data to the same core (so that all the memory they need to access can be kept in the L1 cache). Are threads assigned to cores based on which has the least to do at the moment, or with consideration to making context-switching efficient?
This comment was marked helpful 1 times.
Q_Q
@benchoi The Linux kernel schedules threads onto cores based on idleness of the core, but it also takes into account the cache heirarchy of the hardware - for example, a dual socket motherboard with two Intel i7-920's will have 4 cores sharing an L3 cache and another 4 cores sharing the other L3 cache, so moving a thread from one socket (which has one L3) to another socket (having a different L3) is expensive - the kernel knows this. The same goes for a NUMA computer, where the kernel knows that memory attached to a different node is far away and should avoid sending a thread across nodes if possible.
The kernel might also take into account power considerations - for example, one core might be lightly loaded at 10% utilization, and another is completely idle, so it has entered a power saving state. and another thread needs to run. The kernel might schedule the thread on the one lightly loaded core, which causes the two threads to contend for resources, but saves power, or it might schedule the thread on the sleeping core, causing more power usage. This is adjustible in the Linux kernel (google sched_mc_power_savings)
This comment was marked helpful 1 times.
rokhinip
Here's my understanding/summary of the discussion on hardware multithreading vs multithreading:
Hardware multithreading is when we have multiple threads on 1 core, each having its own execution contexts, but all the threads are sharing the fetch and decode units and the ALUs. This is why we have interleaved execution of these 4 threads since they are all dependent on the same fetch and decode units and ALUs. When we need to switch between these threads, we don't need to flush out the data since we simply choose to read the instructions necessary for a different thread and work in the appropriate execution context. Since there is minimal transfer of execution context data, this is very cheap (in terms of latency for this hardware multi threading switch). As a result, the CPU can manage this and take advantage of it by switching to a different execution context when there is a small latency such as an L2 cache miss when 1 of the threads is executing.
An OS context switch occurs when we need to switch out a thread running on an execution context entirely and run a different threads. This means that all the data in the execution context needs to be flushed out (as stated in greater detail on the previous slide's comments) and this is where the OS comes in. It is also more expensive and it is therefore best to be executed during large latency operations like reading from disk.
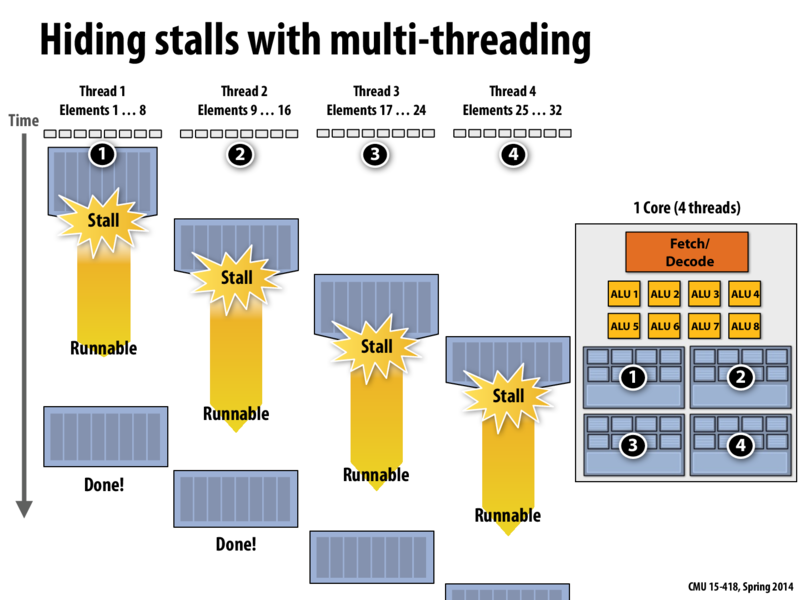
To extend the metaphor from class, the time between when the memory is finished loading and when the processor gets back to it is like the time when your laundry is done, but you (the processor) are busy watching Mad Men or doing some otter thing.
Also, I'd like to draw attention to how the threads are labeled as loading 8 elements at once. That answered one of the otter questions I had about whether the number of threads relates to the number of ALUs.
This comment was marked helpful 0 times.
There is no such thing as a 'free lunch' when it comes to designing processors (ie deciding how to allocate transistors to various components).
We already talked about how removing the components that made a single core run faster (such as large cache memories, pre-fetchers, branch predictors, etc) enables us to add more cores (albeit slower than our single fast core), leading to potential speedup.
That design decision 'raises its head' when we try to reduce latency arising from processor stall, as large cache memories and pre-fetchers play a role in reducing latency, but our decision to opt for multiple cores instead reduces the latency-reducing/hiding power of such components.
Even the usage of multi-threading has potential problems that may yield latency:
a) In order to run multiple threads on a single core, we need more 'execution context units'. For a given registers/virtual memory that can be used for execution context, a greater number of individual units will reduce the amount of resources to any one thread. A thread that has many independent variables may have its data 'spill-over' into slower memory units, leading to latency.
b) Each thread also takes longer to run (as there is a period of time where other threads are running on the same core, while the high-latency operation on the thread that initially stalled has completed). I'm not sure, but if the memory latency is sufficiently small, this may result in lower performance (or at least, worse performance than what could be achieved).
There could be some problems if the work is poorly distributed as well.
Question: How would a processor determine whether or not the latency involved is sufficient to warrant switching to another thread? Or is switching to another thread in the light of a stall, no matter how small, better than doing nothing (when considering a multi-core system).
This comment was marked helpful 0 times.
@arjunh I'm not sure if this is correct, but I think if I were to be the processor, I would probably check if the stall comes from a thread fetching data from cache (which level) or memory, the time could therefore be estimated. Since it seems like the minimum time for memory latency still could far longer than to execute instructions of another thread.
This comment was marked helpful 0 times.
@arjunh You raised a very good question. There is a trade off between context switching and waiting. If you switch, you have to pay the cost of storing and loading the context as well as draining and filling the pipelines, this is expensive when you have a lot of registers and a very deep pipeline. As you have mentioned, switching threads also pollutes the cache and TLB, and can have a QoS problem (A thread with a lot of memory access will run much slower than a thread with few memory access). However, if you not switch, you are paying the opportunity cost of utilizing the processor when the thread is waiting.
Also, it is important to note that GPUs does not have any of the problems above, so always switching threads works well for GPUs. GPUs have multiple context stores on chip that are quick to access; small number of registers; very short pipeline; small cache; no TLB; all threads are identical.
It is also important to note that the type of multithreading on this slide does not apply to any CPU product today. Whether to switch or not on CPUs remains an open research question. If you are interested, the type of processors that does what @analysiser says is called SoEMT processors, or coarse-grained multithreading processors.
This comment was marked helpful 2 times.
In the class, professor mentioned that scheduling on multi-threaded processors is now an active research area. It seems that commonly-used OS are still using strategies invented more than 10 years ago. Is there any promising progress in this field?
This comment was marked helpful 0 times.
@squidrice Thread scheduling becomes more interesting after the introduction of chip multiprocessors (CMP) in early 2000s. Several reasons why they becomes interesting: 1. Multiple cores share on chip resources (Last-Level Cache, memory bandwidth) and interfere with each other. This one also applies to GPUs. 2. When multithreaded applications run on CMPs, they may contend each other for shared data and locks. 3. These problem becomes even more interesting if we have one or more cores more powerful than the others (Heterogeneous multicore).
Here are some references to recent publications studying these problems: Talk to us if you are interested.
Memory Interference:
Muralidhara, Sai Prashanth, et al. "Reducing memory interference in multicore systems via application-aware memory channel partitioning." Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. ACM, 2011.
Lock Contention:
Du Bois, Kristof, et al. "Criticality Stacks: Identifying Critical Threads in Parallel Programs using Synchronization Behavior." (2013).
GPU:
Rogers, Timothy G., Mike O'Connor, and Tor M. Aamodt. "Cache-conscious wavefront scheduling." Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE Computer Society, 2012.
This comment was marked helpful 0 times.
I assume that what we're talking about here is hardware multithreading and not kernel/OS multithreading. From the kernel's point of view (C or assembly), I don't see a way to tell if a certain instruction/memory lookup is going to cause a stall, because that's a lower level concept. This would need to be implemented in hardware. Further, then, I assume that this type of thing is the point of so-called hyperthreading.
I imagine the kernel would be more preoccupied with higher level scheduling, and would express to the processor that a certain set of threads are to be run on the same core, allowing the processor to handle the within-core scheduling.
This comment was marked helpful 1 times.
How relevant is this, from a programmer's perspective? I gather from above comments that this strategy is not found in today's hardware. If such hardware becomes available, how can it be exploited?
Further, does the same idea extend to other sources of latency (e.g. network/disk)? I would imagine that in those cases, the latency becomes much larger than the overhead of software context switches.
This comment was marked helpful 0 times.
@eatnow. I certainly wouldn't tell you about it if it didn't exist! ;-) The idea of hardware multi-threading is present in forms in all Intel CPUs (Hyper-threading, which features two hardwar-managed execution contexts per core), all modern GPUs (at a large scale... e.g., 10's of execution contexts per core, see slide 55), and in other popular processors like the SUN UltraSparc T2.
You are also correct that for very large latency operations such as accessing disk, the latency is so large that it's acceptable to implement the context switch in software (the OS performs it). The idea of hardware multi-threading is that some latencies are too short to be able to invoke the OS (e.g., a cache miss), but critical enough to performance that the hardware should manage latency hiding itself.
This comment was marked helpful 2 times.
It seems that reducing the cost of context-switching for each core can be achieved by assigning threads with a lot of shared data to the same core (so that all the memory they need to access can be kept in the L1 cache). Are threads assigned to cores based on which has the least to do at the moment, or with consideration to making context-switching efficient?
This comment was marked helpful 1 times.
@benchoi The Linux kernel schedules threads onto cores based on idleness of the core, but it also takes into account the cache heirarchy of the hardware - for example, a dual socket motherboard with two Intel i7-920's will have 4 cores sharing an L3 cache and another 4 cores sharing the other L3 cache, so moving a thread from one socket (which has one L3) to another socket (having a different L3) is expensive - the kernel knows this. The same goes for a NUMA computer, where the kernel knows that memory attached to a different node is far away and should avoid sending a thread across nodes if possible.
The kernel might also take into account power considerations - for example, one core might be lightly loaded at 10% utilization, and another is completely idle, so it has entered a power saving state. and another thread needs to run. The kernel might schedule the thread on the one lightly loaded core, which causes the two threads to contend for resources, but saves power, or it might schedule the thread on the sleeping core, causing more power usage. This is adjustible in the Linux kernel (google sched_mc_power_savings)
This comment was marked helpful 1 times.
Here's my understanding/summary of the discussion on hardware multithreading vs multithreading:
Hardware multithreading is when we have multiple threads on 1 core, each having its own execution contexts, but all the threads are sharing the fetch and decode units and the ALUs. This is why we have interleaved execution of these 4 threads since they are all dependent on the same fetch and decode units and ALUs. When we need to switch between these threads, we don't need to flush out the data since we simply choose to read the instructions necessary for a different thread and work in the appropriate execution context. Since there is minimal transfer of execution context data, this is very cheap (in terms of latency for this hardware multi threading switch). As a result, the CPU can manage this and take advantage of it by switching to a different execution context when there is a small latency such as an L2 cache miss when 1 of the threads is executing.
An OS context switch occurs when we need to switch out a thread running on an execution context entirely and run a different threads. This means that all the data in the execution context needs to be flushed out (as stated in greater detail on the previous slide's comments) and this is where the OS comes in. It is also more expensive and it is therefore best to be executed during large latency operations like reading from disk.
This comment was marked helpful 0 times.