So based on everything after this that deals with cache coherence, does the cycle latency here just refer to reads or also for writes? I ask this because I would imagine that to keep up with the rules of coherence, since L1 Cache and L2 Cache would both have to update other processors on writes, the message passing to update other processors of the change might be the limiting factor in terms of latency of operations (the Ring Interconnect is the furthest away after all).
This comment was marked helpful 0 times.
kayvonf
Good questions. You should interpret these latencies of the latency of a read cache hit. Also keep in mind that a read cache hit will not generate coherence traffic in the invalidation-based protocols discussed later in this lecture. (A good thought experiment is to convince yourself why that is the case.)
Reasoning about the latency of writes is more complicated since they can be write buffered and the processor can proceed past the writes. With a read, the processor cannot execute the dependent instruction until the data arrives.
This comment was marked helpful 0 times.
kkz
A read cache hit will not generate coherence traffic because it does not alter the state of your cache. Therefore, it is not relevant to other processors.
This comment was marked helpful 1 times.
elemental03
What does the outstanding misses property of the L1 and L2 cache are referring to? and what type of factors shape how you decide what number of outstanding misses to implement in a cache?
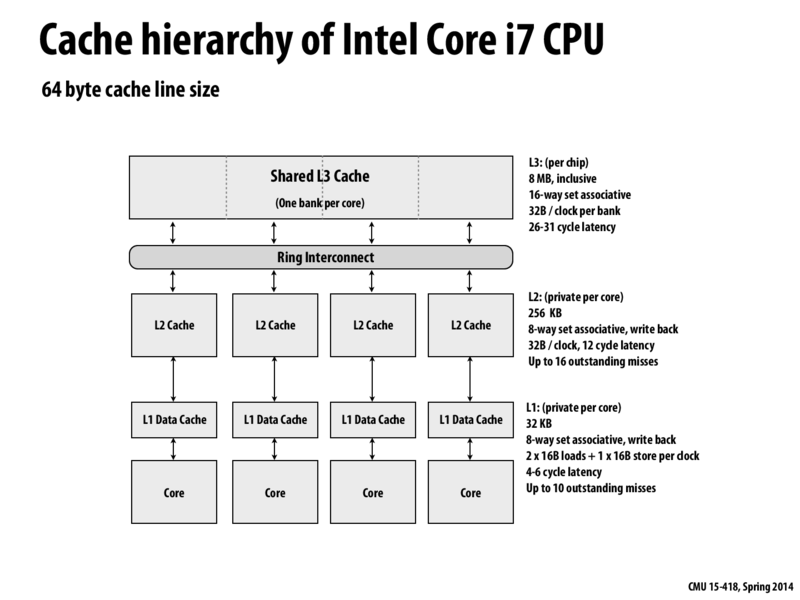
So based on everything after this that deals with cache coherence, does the cycle latency here just refer to reads or also for writes? I ask this because I would imagine that to keep up with the rules of coherence, since L1 Cache and L2 Cache would both have to update other processors on writes, the message passing to update other processors of the change might be the limiting factor in terms of latency of operations (the Ring Interconnect is the furthest away after all).
This comment was marked helpful 0 times.
Good questions. You should interpret these latencies of the latency of a read cache hit. Also keep in mind that a read cache hit will not generate coherence traffic in the invalidation-based protocols discussed later in this lecture. (A good thought experiment is to convince yourself why that is the case.)
Reasoning about the latency of writes is more complicated since they can be write buffered and the processor can proceed past the writes. With a read, the processor cannot execute the dependent instruction until the data arrives.
This comment was marked helpful 0 times.
A read cache hit will not generate coherence traffic because it does not alter the state of your cache. Therefore, it is not relevant to other processors.
This comment was marked helpful 1 times.
What does the outstanding misses property of the L1 and L2 cache are referring to? and what type of factors shape how you decide what number of outstanding misses to implement in a cache?
This comment was marked helpful 0 times.