



Write Allocate: If you want to write to memory, the line is fetched from cache, and written to. Then, the cache line is marked as dirty -- this means that main memory will be updated later. Usually used with write-back caches.
Write-no-allocate: If you want to write to memory, skip the cache. Write directly to memory.
This comment was marked helpful 1 times.

What is the difference between write back and write allocate, and between write through and write-no-allocate? They seem to be practically the same thing.
This comment was marked helpful 0 times.

A write back cache writes data lazily -- it first writes in the cache, and writes to memory only when the cache line is evicted. A write-through cache writes directly through to memory.
Thus, with write back and write allocate caches, whenever we write, we first do all the writes in the cache first (and mark the line we modify as dirty), loading the data into the cache if necessary, and then write then to memory later, as smklein has said. With write through and write-no-allocate caches, we write directly to memory, and don't load data to the cache on writes.
This comment was marked helpful 0 times.

The Tag field is used to map a cache line to a memory location. You can think of it as a base pointer to the block of memory which contains the variable x in this example.
Also, x here holds the value 1 and is typed as an int. In this example architecture, it appears that multibyte values are stored in little endian format (i.e. the least significant bytes are located in lower memory addresses). So 0x00000001 is stored in memory (and cache) as [0x01, 0x00, 0x00, 0x00].
This comment was marked helpful 1 times.

@RICEric22, for cache write policies, wikipedia has a good explanation and two pictures showing what the policies are. Just search cache.
I will briefly explain here, the main difference between these two groups is that:
For write-back/write through, it refers to the condition that if the data in the location is in the cache, so there is a cache hit, then you modify the data.
For write-allocate/no allocate, it refers to the condition that if the data in the location is NOT in the cache, so there is a cache miss, you need to decide whether you want memory to first bring the cache line or not.
If this is still not clear, you can see the pictures in wikipedia, which is quite clear.
This comment was marked helpful 3 times.

@dfarrow. Yes, this is a little endian example, mimicking the behavior of Intel CPUs.
This comment was marked helpful 0 times.

With write-allocate strategy, write misses are similar to read misses, where data are loaded into the cache when cache miss happens.
On the contrary, for write-no-allocate strategy, if write miss happens, data are directly written to memory, skipping cache.
I have a question: Is there a relation between "write-allocate" and "write-back cache"? I mean: are they the common combinations of cache strategies people use? Thank you
This comment was marked helpful 0 times.
@chaihf: Your intuition is correct. A write-back cache must necessarily be write-allocate. (The line must be brought into cache on a write... otherwise the system must update memory each write, and thus it would not be considered write-back.)
This comment was marked helpful 0 times.

Dirty bit is set when the processor writes to this memory, but not yet been saved to storage.
This comment was marked helpful 0 times.

What is the line state exactly? I feel like everything else was discussed in class, but the line state was glossed over a bit, so I don't remember it's purpose.
This comment was marked helpful 0 times.
Line state is all the processor-specific additional information about a line that's stored in the class. In this example, it's just a dirty bit. Another piece of information that would need to get stuffed here is the current state of the line in the coherence protocol (e.g., M, E, S, or I)
This comment was marked helpful 0 times.
So, a line state can end up being a single bit, if it's just storing the dirty bit, but how long are they usually, if they have to keep track of which state the line is in? Does it depend on how many states there are?
This comment was marked helpful 0 times.

In the above comments, it is stated that in write-no-allocate strategy data is directly written to memory skipping cache. However, in the wikipedia article on cache I think it states that in this situation writing in this situation actually occurs to both the cache and memory synchronously. If there is a significant difference between the definitions, which is correct?
This comment was marked helpful 0 times.
@asinha. If the line being written to is already in cache, the cache certainly must be updated along with memory. The above comments were referring to the situation where the line is not in cache, and thus a no-allocate write-through policy will not bring the line into cache. It will only directly update memory.
This comment was marked helpful 0 times.

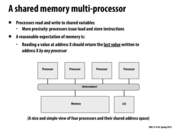


This example assumes, as noted on the slide, that the cache is using write-back behavior. This is significant because if the cache were using write-through behavior, the stores would immediately modify the value stored at address X in memory, and the coherence problem demonstrated in the table would be avoided. (Is this correct?)
This comment was marked helpful 0 times.
@cardiff. Close. Even with a write-through policy, coherence would still not exist. Two processors could load data into their caches and modify it in different ways. Without an invalidation protocol for these write-through caches, as discussed on slide 19, you still don't have coherence. Just adding write-through to the behavior above doesn't give you write propagation.
This comment was marked helpful 0 times.

The coherence is potentially broken when a cache hit happens. For the write-through policy, the data is written to both cache and memory for processor 1. Later, if there is another processor 2 writing to the same address, the data in memory is updated, but the data in processor 1's cache remains the same. I think a possible solution to the write-through policy is to invalidate the cache line whenever a store happens. However, without a protocol, the solution can be inefficient, because the invalidation is unnecessary when a processor has the cache line exclusively.
This comment was marked helpful 0 times.

@squidrice Right so always invalidating the cache line upon a store would solve the coherence problem right? However as you said, this would be massively inefficient, because a lot of unnecessary invalidation would take place.
This comment was marked helpful 0 times.


Locks in this case would not fix the issue, as it does not ensure write propagation.
This comment was marked helpful 1 times.
Is it even possible to ensure write propagation using locks? It seems like locks solve a completely different problem...
This comment was marked helpful 0 times.
@idl. Correct. That was a bit of a trick question. You (and @kkz) were not tricked.
This comment was marked helpful 0 times.

I think that some of the mutex libraries out there will issue the correct cache flush instructions, if the underlying architecture doesn't support cache coherence itself and requires explicit cache management.
This comment was marked helpful 0 times.

Question: What is a good non-CS analogy for the cache coherence problem?
This comment was marked helpful 0 times.

I've been trying to think of a good one, but this is the best I've come up with (really it's only one value rather than a cache): Consider a scenario where there is a central bank in the city and a bunch of villages with banks, and we're still on the gold standard. All of the villages should have the same price of gold to avoid rich people from exploiting the differences and becoming richer (because we are democratic and whatnot). The price of gold depends on the amount in the bank and in circulation, so it changes when gold discoveries are made and when bank robberies occur by outlaws (who remove the gold from circulation) (note that discoveries are only made in rural places, and security of the central bank is too high for robberies to occur). Each local bank is aware of these changes, and updates the price accordingly. The central bank should always be up to date with these changes, as well as each other village, so that the exchange price is equal everywhere. Communication requires someone physically delivering the message though, so coherence isn't trivial.
Hoping to see someone else give a stab at it!
This comment was marked helpful 0 times.

A team is playing a basketball game. When the opponent takes possession of the ball, the game state changes from OFFENSE to DEFENSE (and vice versa when the team gets the ball). Each player caches the game state in order to focus on what they are doing, but need to know when the game state changes, so the player who changes the game state (for example by losing the ball to an opponent) shouts to let his team know, and they drop their own cached state and reorient to figure out what is going on.
This comment was marked helpful 0 times.


So based on everything after this that deals with cache coherence, does the cycle latency here just refer to reads or also for writes? I ask this because I would imagine that to keep up with the rules of coherence, since L1 Cache and L2 Cache would both have to update other processors on writes, the message passing to update other processors of the change might be the limiting factor in terms of latency of operations (the Ring Interconnect is the furthest away after all).
This comment was marked helpful 0 times.
Good questions. You should interpret these latencies of the latency of a read cache hit. Also keep in mind that a read cache hit will not generate coherence traffic in the invalidation-based protocols discussed later in this lecture. (A good thought experiment is to convince yourself why that is the case.)
Reasoning about the latency of writes is more complicated since they can be write buffered and the processor can proceed past the writes. With a read, the processor cannot execute the dependent instruction until the data arrives.
This comment was marked helpful 0 times.
A read cache hit will not generate coherence traffic because it does not alter the state of your cache. Therefore, it is not relevant to other processors.
This comment was marked helpful 1 times.

What does the outstanding misses property of the L1 and L2 cache are referring to? and what type of factors shape how you decide what number of outstanding misses to implement in a cache?
This comment was marked helpful 0 times.


In case 1, what does it mean for a network card to "async send buffer"?
This comment was marked helpful 0 times.

I believe that means that the processor tells the network card that the buffer is ready, but the network card can choose to send off the data whenever it is ready, i.e. asynchrounously from the processor's request.
The issue arises because the processor may have written the data to its local cache but it has not yet been flushed to main memory. The network card cannot see the processor local cache thus may it not use the correct data.
This comment was marked helpful 1 times.






Cache coherence makes no guarantees about maintaing order among different processors of writes to different locations in memory. Coherence only guarantees that the order of writes to a given location will be observed in the same order across all processors.
This comment was marked helpful 4 times.

Question: why should we care the order of R/W to different locations?
This comment was marked helpful 0 times.

@iamk_d___g I think one case is when you have copies of data at different locations like in distributed systems. You want data to be consistent across all locations if they are updated.
This comment was marked helpful 0 times.

@iamk_d___g You can also think about it in regards to program order. If one processor is reading and writing to multiple locations, then the data from those reads and writes should propagate through before it is actually needed to maintain accuracy of program execution. When you bring multiple processors into the mix, now "program order" also includes "processor access order" to maintain accuracy of the system.
This comment was marked helpful 0 times.
@iam_d__g: consider this situation, where flag is initialized to zero:
// thread 1, running on processor 1
int x = do_important_stuff();
int flag = 1;
// thread 2, running on processor 2
while (flag);
... do more important stuff using x
Consider what might happen if for some reason processor 2 became aware of the update to flag prior to learning about the update to x. Memory coherence only guarantees that processor 2 sees updates to x in the correct order. It provides no guarantees about the relative ordering of updates to different addresses. The latter is an issue of memory consistency, which will be discussed in Lecture 13.
This comment was marked helpful 2 times.
Do modern memory implementations abide by memory consistency? ie. will the above code always work as intended?
This comment was marked helpful 0 times.
Modern processors implement relaxed memory consistency models.
This comment was marked helpful 0 times.


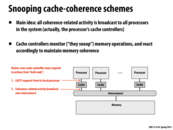

As all memory coherence operations are broadcasted to all processors, wouldn't this put a lot of pressure on the interconnect? Especially in the case that the interconnect is not a connected graph structure, but instead is the token based structure. Which is the case when there's in the range of 16 or more processor in a core.
This comment was marked helpful 0 times.

I'm also curious about the interconnect. Will there be conflicts when multiple cores are shouting?
This comment was marked helpful 0 times.
Absolutely. Contention for the interconnect can become quite a problem in snooping-based protocols. Hence the need for directory-based schemes that replace broadcast with point-to-point messages among only the interested caches.
This comment was marked helpful 0 times.

How do directory-based schemes and snooping-based schemes compare in real life? Which one is more commonly used solution or does it depend on the case (i.e. above n number of cores the advantages of directory-based schemes overpower the advantages of snooping-based schemes)?
This comment was marked helpful 0 times.

I remember hearing that a lot of current systems have space for directories built into the hardware for the machine, so I imagine the directory based system has its merits. Not having to send signals to all processors about cache coherence must be significant enough of a benefit that modern system designers choose to implement a directory-based cache coherence.
Also look at slide 21 on the directory based cache scheme slide. In that slide we see that most programs only share data between a couple of processors at any given time. Although broadcasting might be efficient if we only have a couple of processors, as systems incorporate more cores the lack of complexity of broadcasting starts to get outweighed by the fact that signals are being sent to processors that don't need signals
This comment was marked helpful 0 times.
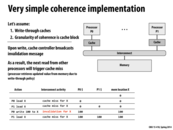
In class, the question was asked "If we have multiple processors running at the same time, how can we draw this timeline with each action happening in a separate, specified order?"
The answer is essentially that the interconnect uses total-store ordering, allowing us to model "cache differences" (misses + invalidations) in this ordering. Cache hits and other, non-cache operations are not bound to this ordering because the interconnect (and other processors) wouldn't care about these operations.
This comment was marked helpful 0 times.
Note: one may wonder why caches need to broadcast when they encounter a cache miss. In this example, it's not strictly necessary, but will become more important in the later models in this lecture.
This comment was marked helpful 0 times.

Just to reiterate why this strategy works: a write operation by Processor X will result in Processor Y's cache having stale data if it contains the line with the address of the write. Thus, a solution to this problem is for Processor X to broadcast upon writing, which will cause Processor Y to invalidate that line. Thus, if Processor Y tries to access that address after Processor X writes to it, a cache miss will occur and fetch the updated data from memory.
This comment was marked helpful 1 times.
@yrkumar: solid work in that description!
This comment was marked helpful 0 times.
I'd like everyone in the class to make sure they understand the invalidation must occur "before" P0's write completes. The cache coherence protocol specifies that P0's write does not officially complete until P0's cache controller confirms that all other processors have invalidated their copy of the cache line.
Question: Is cache coherence preserved if P0's write completes AND THEN the invalidations occur?
This comment was marked helpful 0 times.
@kayvonf:
No, cache coherence is not preserved if the write completes, and invalidations occur afterwards.
What if P1 tried to load X before P0's invalidation had propagated? The definition of coherence includes "the value returned by a read must the the value written by the last write on ANY PROCESSOR".
If P1 was capable of loading X from its cache, and not from P0's recent write, then coherence is lost.
This comment was marked helpful 0 times.

What happens if two processors write at almost the exact same time (the difference in time is smaller than the time it takes for their "shout" to be broadcasted to other processor)? Wouldn't both processors have a different value for the same location in memory? Would one processor just drop the line, load the updated line, and redo the write that it was gonna do?
This comment was marked helpful 0 times.
@LilWaynesFather. You should assume that the invalidation must be confirmed prior to the write occurring. Therefore the situation you describe cannot occur.
This comment was marked helpful 0 times.

I'm guessing it's not possible for the following interleaving of operations to happen?
- P0 initiates a write to location X.
- P0 broadcasts the write to the other cache controllers.
- P0 confirms that the other processors have invalidated their caches.
- P3 attempts to read from location X - dirty miss.
- P3 brings the line containing X in from memory - the line hasn't been updated by P0 yet.
- P0 writes to location X in memory.
This comment was marked helpful 0 times.
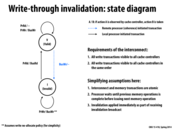

I have a question: If we are in state V, and execute PrWr, why we still in the Valid state? As we use write-through strategy and will write new data into memory directly, which makes data in cache invalid. I'm not sure if I was wrong.
This comment was marked helpful 0 times.

@black It's a write made by the local processor (ie the processor that made the initial change). So, the processor can make any changes it feels like to the line; it effectively owns it. If another processor writes to the same line, however, the processor will have to drop the line; the line is now out of date.
This comment was marked helpful 0 times.
@black, I think you are correct, but the procedure is the processor directly write new data into memory, so there is no data in the cache for this memory address. This reaction does not make data in cache invalid. Since data is not in cache, it is invalid before and after.
This comment was marked helpful 0 times.
@yanzhan2, I am not sure why 'there is no data in the cache for this memory address'. We move to Valid only after we PrRd that data into cache. I think maybe PrWr will invalid its own cache too?
This comment was marked helpful 0 times.
If a line is in the valid state, the line is, by definition in the cache. A write through cache, as is the case in this example, will immediately update memory on every write to this line. The write will not invalidate the line in the cache, so the line stays in the valid state. Notice that a PrWr action on a line in the valid state does not initiate a state transition for the line.
If the line being written to is not in the cache, a write allocate cache will first bring the line into the cache and also update memory. A write no allocate cache will simply update memory, and not bring the line into cache.
This comment was marked helpful 0 times.

For a write through cache, write is done both to the cache and the memory, so PrWr won't change the state if we are in state V.
This comment was marked helpful 0 times.

If this was a write-through, write allocate, then I think the only transition that would need to change is the self loop on state I. The PrWr/BusWr transition from state I would now go to V.
This comment was marked helpful 0 times.
@jinsikl: correct. That might allow for a subsequent read to be a cache hit in the case where a program wrote first, and the then read the line. (In practice reading before writing is far more common.)
This comment was marked helpful 0 times.

Question: Describe an access pattern where a write-back cache generates as much memory traffic as a write-through cache.
This comment was marked helpful 0 times.

Each time a processor tries to write to a location, it triggers a cache miss.
Suppose we have a 16 byte direct-mapped cache, and one cache line is 8 byte.
int a[8];
for(int i=0;i<100;i+=2){
a[i%8]=i;
}
It writes to a[0], a[2], a[4], a[6] repeatedly, but such pattern will trigger cache miss because of conflict.
This comment was marked helpful 0 times.
Another example would be a situation where each line is simply written once.
This comment was marked helpful 0 times.

So, to sum up the two situations mentioned above, I guess when the writing miss rate is 100%, then a write-back cache generates as much memory traffic as a write-through cache. Whenever we get a write cache hit, the write-back cache just skips one unnecessary access to main memory, thus reducing memory traffic compared to write-through cache.
This comment was marked helpful 0 times.


Write-through caches ensure memory always has the most up to date value stored in an address. This simplifies coherence, since to obtain the latest value stores at an address, the requesting processor can simply issue a memory load. Write-back caches pose new challenges to maintaining coherence, since the most recent value stored at an address may be present in a remote processor's cache, not in memory.
This comment was marked helpful 0 times.

It seems as if there is a trade-off here between memory access time and processor communication time. When using a write-through cache, as Kayvon mentions above, it is not only simple to maintain cache coherence, but there also does not need to be any communication between processors. However, every time there is a write, the processor has to communicate with memory. With a write-back cache, processors must communicate in some way, direct or indirect, to obtain the correct values of the data they're using. However, this will spend less time going back to memory. So which method is faster might depend on the computer, but it seems like write-back will probably be faster most of the time.
This comment was marked helpful 0 times.

Is it appropriate to think of the "interconnect" as a queue? What happens if the queue is full?
This comment was marked helpful 0 times.

It appears that the interconnect, at least in Intel's case, is two 20-lane point-to-point data links, 20-lanes in each directions. My guess is that if all the lanes in one direction are occupied and data transfer is attempted in the same direction, the request will stall (maybe spin-lock?) until a lane is open and then send the data over.
Reference: http://en.wikipedia.org/wiki/Intel_QuickPath_Interconnect.
This comment was marked helpful 0 times.
Question: The first two bullet points on this slide describe two major principles of implementing cache coherence. Someone should try to put my description in their own words.
This comment was marked helpful 0 times.
@kayvonf: I will try explaining these principles in my own words --
Imagine computer where processors could only read. Cache coherence is easy! No matter what, all processor caches are consistent with each other. If caches are shared between processors, it produces no problems.
How can we introduce writing? In the simplest way, we must be sure that no one else has outdated information.
We can make this our first step: If we want to write to X, we must trash the caches lines of everyone else who had a copy of X (aka, broadcast a read-exclusive transaction).
Okay, cool, we can start writing. But when are we required to stop? Essentially, we can keep writing until someone else wants to write to X's cache line (in which case, they trash our cache), or someone else wants to read from X's cache line (in which case, they ask to share the cache).
Until this invalidation/sharing happens, no one else has read/wrote to our cache line. We signify our state as "modified" (if we actually wrote the cache, and we need to tell main memory), or "exclusive" (if we match main memory). This means we can keep writing without bothering to tell anyone else, as no one else needs to know what values are actually in X's cache line.
This comment was marked helpful 1 times.
Excellent @smklein. Now can someone try to do the same, but use the terms write propagation and write serialization in their explanation.
This comment was marked helpful 0 times.
@kayvonf I'll take a stab at this. The purpose of these coherence protocols is to ensure write propagation. This is where a processor P's write to a location in memory is propagated, or seen by all the other processors. This gets at the heart of the coherence problem; without write propagation, other processors might get stale data upon reads. This can be ensured by the invalidation protocols as summarized by @smklein above, via read-exclusive broadcasts, and the various states in the state diagrams on slide 20.
Write serialization is to follow the definition of coherence, where we strive to define a total ordering of operations at the same memory location on a line. This ensures that every processor observes the same order of reads/writes. Having the read-exclusive state ensures that only 1 processor may write to a memory location at any one time, and the result of write propagation is that any read that follows that write would get the updated value of that location (otherwise the read 'dot' would appear before the write on the timeline).
This comment was marked helpful 0 times.
@lixf, @spilledmilk The 20 lanes refers to that 20 bits can be transferred on one clock edge.
What probably actually happens is that since the interconnect uses QPI to create a ring buffer, and the ring buffer's slots for messages are defined by a number of clock edges (so if a slot is 5 edges, it can hold 20 lanes x 5 edges = 100 bits), and that the cache controller has to wait until it sees an empty slot to put it's message in the buffer.
This comment was marked helpful 0 times.

Specifically:
BusRdnotifies all processors the issuing processor is pulling the line into its cache for read-only access, and also fetches the line from memory.BusRdXnotifies all processors the issuing processor is pulling the line into its cache for read-write access, and also fetches the line from memory.BusWBwrites a cache line back to memory.
This comment was marked helpful 0 times.
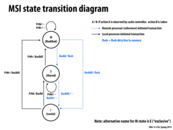

flush == BusWB, right?
This comment was marked helpful 0 times.

@bwasti I think the flush is BusWB. And although the two flushes are in blue color, actually the flush operations are done on local processor.
This comment was marked helpful 0 times.
Question: Is the write "protected"? Consider the following scenario: P1 wants to consecutively write 1,2,3,4,5. After it shouts and write 1, P2 wants to read the same cache line. Then does P1 immediately drop the entire cache line and stop writing?
This comment was marked helpful 0 times.
@lixf, for this case, when P2 wants to read the cache line, P1 would transfer to S state and flush memory, so P2 would get value 1. Then P1 would transfer to M again to write 2,3,4,5, while P2 transfers to I.
This comment was marked helpful 2 times.
@wanghp18/@bwasti. Yes, the flush is the write back. Flush means that the dirty cache line is transmitted over the bus to memory, and memory is updated.
Just to clarify. On this slide, the blue transitions are transitions that are triggered by an event observed on the bus (as opposed to an event triggered by the local processor, which are shown in black). However, in either case, the state transition diagram and the action taken by the cache is a local action by the cache. It's more precise to state that the cache flushes the line (since the line is a part of the cache), rather than say the local processor does. It's simpler to think of a cache as a unique unit, that responds to requests on the bus and from the local processor.
This comment was marked helpful 1 times.

@yanzhan2, if p2 takes the line with only 1 written to it, wouldn't this be an incorrect answer? Write of p1 wouldn't be atomic in this case either. Or does p2 not get to use the line at all? It has to wait for p1 to finish all the writing?
This comment was marked helpful 0 times.
@jinghuan. I think the protocol only maintains the coherence, while the correct execution sequence is not a consideration. If the programmer wants a specific order, he or she is responsible for it, since hardware can't figure it out without any command. For the case here, if the programmer means to make p2 read the final result, 5, he or she should add synchronization to both processes.
This comment was marked helpful 0 times.

It seems that BusRdX and PrWr are sharing all the black arrows. Is there any reason why they are indicated separately in the diagram? I would expect that if the local processor wants to write, it would also get exclusive read access...
This comment was marked helpful 0 times.
@eatnow: I believe you are misinterpreting the diagram. PrWr / BusRdX means "when the local processor wants to write a BusRdX is sent out on the bus".
This comment was marked helpful 0 times.

Question: What is write serialization? Someone take a crack at explaining why the MSI protocol ensures write serialization.
This comment was marked helpful 0 times.
It means that two writes to the same location by two processors will be seen in the same order by all processors. This is ensured because only one processor is allowed to be in the Modified state for a specific cache line. This means at most one processor is allowed to write to that cache line at a time. As soon as another processor wants to write to that cache line, the cache line is flushed and is invalidated on the original processor.
This comment was marked helpful 0 times.
Good, but I'll clarity that write serialization means that all writes by all processors are observed in the same order by all processors.
This comment was marked helpful 0 times.

the MESI protocol is named after the four states of a cache line: modified, exclusive, shared and invalid. In modified state, the data in the cache line is modified, and the copy in main memory is not up to date. In exclusive state, the data in the cache line is unmodified, but is guaranteed to reside in the cache. In shared state, the data is unmodified, and there may be copies of the data in other caches. In invalid state, the cache line does not contain valid data.
This comment was marked helpful 0 times.
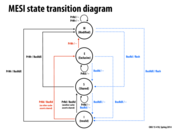
Quick summary of why we have "E":
WITHOUT E: Two Bus "shouts"
To go from "I" to "M", we "shout" on the bus to go to "S", and then "shout" on the bus to go to "M".
WITH E: One Bus "shout"
To go from "I" to "M", when no one else is has cache, we "shout" on the bus to go to "E", and we can go to "M".
This comment was marked helpful 0 times.
E has identical reactions to shared, a RdX and Rd go to Invalid and Shared respectively. Couldn't the E be eliminated if every time the S wrote it asked if anyone else has that cache line and if not simply move directly to M without waiting for an update?
This comment was marked helpful 0 times.
E eliminates the situation of "false shared". Without E, PrRd/BusRd always tranfers I to S, even if local processor is the only one holds the cache line, i.e. the cache line is not shared.
If there is no remote processor does BusRd(X) and the local processor does PrWr in E state, there is no need to do BusRdX thus save one broadcast. And I think this is the benefit of including E.
This comment was marked helpful 0 times.

I agree with wanghp18 and smklein, adding E allows us to go from E to M without any bus shouts. It improves efficiency by allowing us to shout only once when we go from I to M, and zero bus transactions when going from E to M. This improves efficiency when only one processor is writing to its exclusive cache line, because it doesn't have to shout to the other processors unnecessarily.
This comment was marked helpful 0 times.
@bwasti I think your idea is valid, but may incur excessive flushing (as M state is implicitly "dirty").
This comment was marked helpful 0 times.
@bwasti then the protocol is MSI.
This comment was marked helpful 0 times.



How are these finite state machines usually implemented? I imagine it would have to be something very efficient.
This comment was marked helpful 0 times.

At least in terms of digital design, finite state machines of 5 states require very little actual hardware, and can advance as fast as a clock cycle (I'm not sure if this clock is the same as the CPU or GPU clock cycles, but I imagine it could be). It would require 3-5 D-flip flops based on implementation (~36 to ~60 transistors), and some input and output logic to go along with it (<100 transistors). On chips with monstrous numbers of transistors (in the billions), this is almost nothing. In terms of speed, I'm pretty sure that the flip flops can handle even up to GHz for clock frequency, and so the finite state machine should not interrupt any part of the caching.
This comment was marked helpful 0 times.
Question: How does MESIF work? Specifically, how is the cache that supplies data in the event of a cache miss determined in MESIF? (BTW: Wikipedia has a nice description)
Question: How does MOESI work? (again, see Wikipedia)
This comment was marked helpful 0 times.

In the MESIF protocol, the M, E, and I states are the same as in MESI, but it adds a new F (forward) state that is a particular flavor of the S state. In MESI, if a processor has a cache miss, there are two ways to get the data. Either the data is read from main memory (slow), or all of the caches that also hold that particular line can respond (redundant communication). Instead, in MESIF, a cache line in one cache, and only one cache, is designated as being in the F state. This way only one cache needs to forward the data to whichever other cache is requesting it. This assures the data transfer is both minimal (only one cache sends the information as opposed to all that hold the line), and quick (cache-to-cache speeds).
The MESIF protocol determines the F-state cache by passing along the F state to the most recent cache that requested the line. So, if cache x receives data from another cache y about a particular line, then cache x is now in the F state for that line, and cache y transitions to the S state. It is possible that the cache with that line in the F state invalidates that line before another cache wants it, so that no cache has that line in the F state. In this case, the data is read from main memory and the new cache is designated in the F state. By picking the cache that holds a line in the F state based on a most-recently-used policy, hopefully this event occurs infrequently.
This comment was marked helpful 0 times.



I think there was an example like this in 213: If each thread needs to access a spot in memory that is on the same cache line as all the other threads, that line will get invalidated for everyone with every write. If there is 64 bytes between each thread's integer, then they should all be on different cache lines, and the cache lines should stay valid for many more operations at a time.
This comment was marked helpful 0 times.

Is this a common practice? In this situation, we would be using up a lot of memory just to prevent thrashing. Would there be a better solution that does not require padding?
This comment was marked helpful 0 times.
I don't think there is, but the space problem doesn't have to be as bad is it seems. A good thing about this solution is that the 16x space usage doesn't scale directly with the complexity of your problem. Suppose the original code required for each thread three ints and a float. You could put all that in the struct PerThreadState, decrease the size of the padding, and then you're only using 4x the required space. So if each thread requires some space to work with that's a multiple of 64 bytes, you're in the clear.
This comment was marked helpful 0 times.

It is worth noting that you could decrease your number of threads by a factor of 16 then have each thread do 16 times the work. This seems stupid, but it would allow data to be blocked so one cache line is only accessed by one thread. This would avoid the false sharing. It also would not be a slow down unless you have more execution contexts than the number of threads you are spawning.
This comment was marked helpful 0 times.


Here is an article that includes a an excellent overview of cache coherency on a modern intel chip.
This comment was marked helpful 0 times.
There are Software based and hardware based solutions, but hardware based solutions are more common. Hardware Solutions seem to be based on shared caches, snoopy caches schemes, or Directory schemes.
This comment was marked helpful 0 times.