I don't understand how 4D block assignment achieved faster runtime overall. Would someone explain it to me?
This comment was marked helpful 0 times.
selena731
From what I understood, if you look on the previous slide, the diagram on the left shows that you organize your data in row-major order in memory (i.e. (row,col): [(0,0), (0,1), (0,2)...] ). Thus, if you tell your 16 different processors to divide up work by blocks, you will have a lot more cache misses since cache lines could be stored across the partitions/processors. However, on the right side (of previous slide) if you store your data in block-major order (i.e. (row,col): [(0,0), (0,1)..(0,5),(1,0),(1,1)...]), now the data is laid out in memory by how the processors work on it. You will now have less cache misses and more importantly less sharing between the processors, so they can work independently on their own data.
This comment was marked helpful 0 times.
kkz
With the 4D block arrangement, there's now at most 2 cache lines that can be shared per block. With the row-major layout, there are up to 2*(block height) cache lines that could potentially leak across blocks.
This comment was marked helpful 0 times.
aew
A 4D block arrangement prevents cache misses, because the data is arranged in memory in blocks corresponding to the processors, like @selena731 said. However, faster runtime is mostly achieved by reducing sharing between blocks. This prevents cache coherence misses (that might occur due to the ping-pong-ing between processors of data) because the processors are sharing fewer lines, as @kkz mentioned.
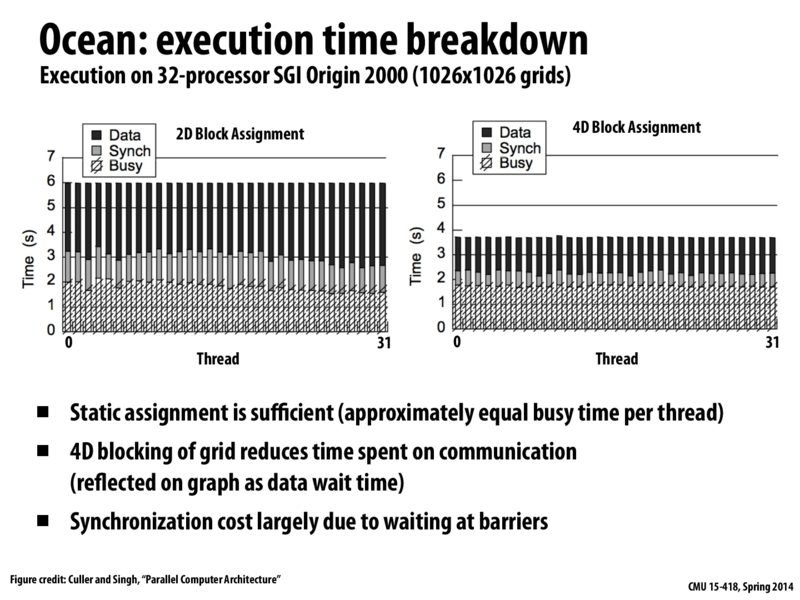
I don't understand how 4D block assignment achieved faster runtime overall. Would someone explain it to me?
This comment was marked helpful 0 times.
From what I understood, if you look on the previous slide, the diagram on the left shows that you organize your data in row-major order in memory (i.e. (row,col): [(0,0), (0,1), (0,2)...] ). Thus, if you tell your 16 different processors to divide up work by blocks, you will have a lot more cache misses since cache lines could be stored across the partitions/processors. However, on the right side (of previous slide) if you store your data in block-major order (i.e. (row,col): [(0,0), (0,1)..(0,5),(1,0),(1,1)...]), now the data is laid out in memory by how the processors work on it. You will now have less cache misses and more importantly less sharing between the processors, so they can work independently on their own data.
This comment was marked helpful 0 times.
With the 4D block arrangement, there's now at most 2 cache lines that can be shared per block. With the row-major layout, there are up to 2*(block height) cache lines that could potentially leak across blocks.
This comment was marked helpful 0 times.
A 4D block arrangement prevents cache misses, because the data is arranged in memory in blocks corresponding to the processors, like @selena731 said. However, faster runtime is mostly achieved by reducing sharing between blocks. This prevents cache coherence misses (that might occur due to the ping-pong-ing between processors of data) because the processors are sharing fewer lines, as @kkz mentioned.
This comment was marked helpful 0 times.