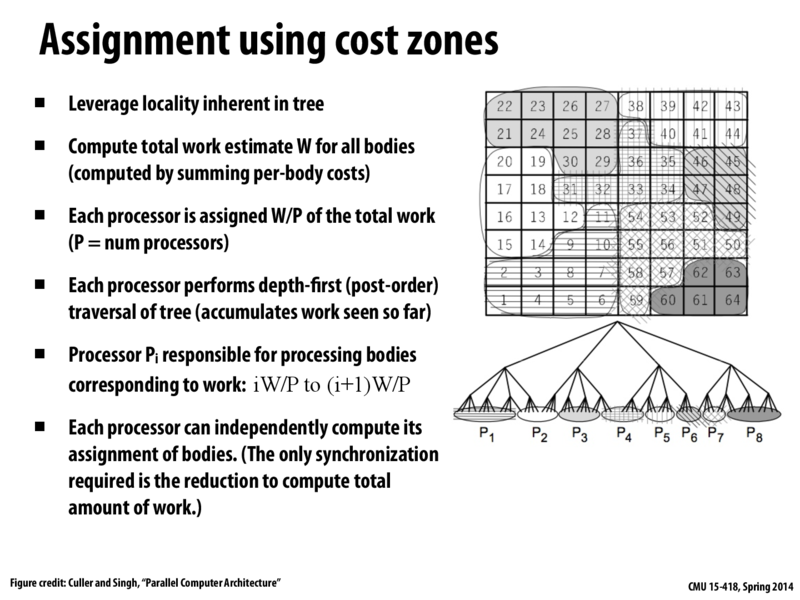
Question: I'm not sure I understand how the work division for the tree on this slide is found. If each processor simply does an independent depth first search until it reaches W/P work completed, then how are we sure there won't be any overlap in the assignment of bodies computed by the processors?
This comment was marked helpful 0 times.
RICEric22
Each processor performs DFS and accumulates a list of work seen so far. Thus, we can have processor i do the particles that correspond to the items in the list from [iW/P,(i+1)W/P), so it does up until the last particle that it sees below the upper work bound. Then, the next processor will carry on at the next particle (the first particle that makes the list have at least (i+1)W/P work), and there will be no overlap.
This comment was marked helpful 0 times.
jmnash
I'm somewhat confused about how W is found for this algorithm. How can we estimate how much work each body will take to compute, without actually doing the computation? Is this what is referred to on the previous slide, when it says "for each time step, for each body, record number of interactions with other bodies"? If so, it also says this is cheap to compute, however looking at slide 27 it seems as if doing this computation increases the "busy" time by a significant amount. However, since it does decrease the overall time, it seems like it is worth it.
This comment was marked helpful 0 times.
paraU
Each processor perform one DFS and accumulates a list of work. I think this would be slower than having one processor performing the DFS and partition the work and assign different partitions to different processors. I'm confused about the parallelism here.
This comment was marked helpful 0 times.
jinsikl
@paraU I think it depends on how W is computed. I think you can compute W so that each node in this tree knows how much work is needed to process all of its children. That way, the DFS on this tree doesn't need to visit all of the nodes. As a concrete example, let's say that the root node will require W, and each of the four children of the root will require W/4. Then processor 8 in this example can skip the traversal of the left-most child, since processor 8 needs to handle the list [7W/8, W), and the left-most child contains the list [0, W/4). The idea is similar to alpha-beta pruning.
But even if W wasn't computed this way, one processor assigning work will require some amount of synchronization (the other processors need to wait and then receive their assignment).
Question: I'm not sure I understand how the work division for the tree on this slide is found. If each processor simply does an independent depth first search until it reaches W/P work completed, then how are we sure there won't be any overlap in the assignment of bodies computed by the processors?
This comment was marked helpful 0 times.
Each processor performs DFS and accumulates a list of work seen so far. Thus, we can have processor i do the particles that correspond to the items in the list from [iW/P,(i+1)W/P), so it does up until the last particle that it sees below the upper work bound. Then, the next processor will carry on at the next particle (the first particle that makes the list have at least (i+1)W/P work), and there will be no overlap.
This comment was marked helpful 0 times.
I'm somewhat confused about how W is found for this algorithm. How can we estimate how much work each body will take to compute, without actually doing the computation? Is this what is referred to on the previous slide, when it says "for each time step, for each body, record number of interactions with other bodies"? If so, it also says this is cheap to compute, however looking at slide 27 it seems as if doing this computation increases the "busy" time by a significant amount. However, since it does decrease the overall time, it seems like it is worth it.
This comment was marked helpful 0 times.
Each processor perform one DFS and accumulates a list of work. I think this would be slower than having one processor performing the DFS and partition the work and assign different partitions to different processors. I'm confused about the parallelism here.
This comment was marked helpful 0 times.
@paraU I think it depends on how W is computed. I think you can compute W so that each node in this tree knows how much work is needed to process all of its children. That way, the DFS on this tree doesn't need to visit all of the nodes. As a concrete example, let's say that the root node will require W, and each of the four children of the root will require W/4. Then processor 8 in this example can skip the traversal of the left-most child, since processor 8 needs to handle the list [7W/8, W), and the left-most child contains the list [0, W/4). The idea is similar to alpha-beta pruning.
But even if W wasn't computed this way, one processor assigning work will require some amount of synchronization (the other processors need to wait and then receive their assignment).
This comment was marked helpful 0 times.