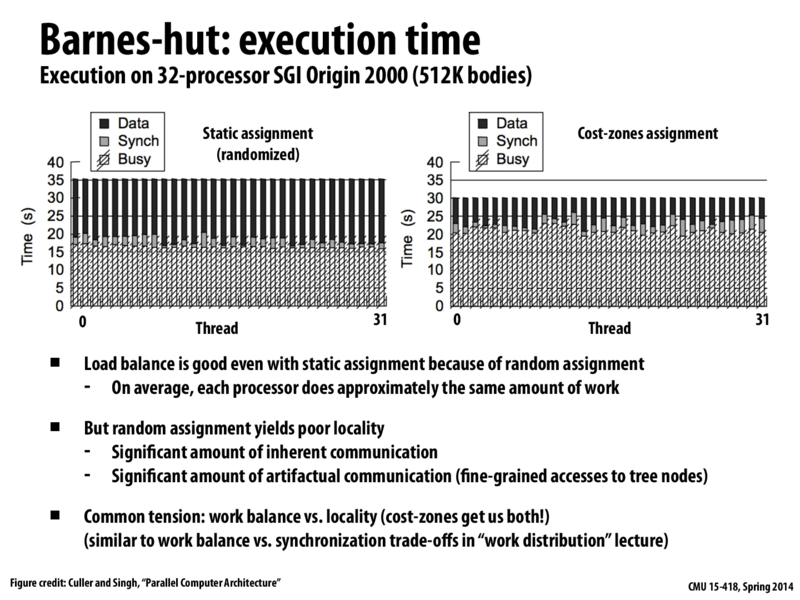
As mentioned on the previous few slides, the "cost-zone assignment" increases locality, and reduces the overall execution time compared to static assignment.
However, it is interesting to note: computing this processor workload distribution has a cost. As you can see in the graphs above, the "busy" section of the graphs is higher on the "cost-zone assignment" implementation than on the "static random assignment" implementation.
Moral of the story? Doing more work to preserve locality and maintain a balanced workload still has the potential to decrease overall computation time.
This comment was marked helpful 0 times.
selena731
Looking at the complexity of writing code for the extra assignment computation, and only 5s of increase in time (compared to the total 30s), is this really worth it?
Can we really argue that the right hand side approach uses the resources better?
This comment was marked helpful 0 times.
kayvonf
@selena731: I guess it just matters how much performance you want to squeeze out, and how willing you are to obtain it. The more advanced assignment scheme improves performance by about 15% over random assignment.
This comment was marked helpful 0 times.
bwasti
Programming to eliminate bandwidth problems seems to be programming to the hardware. If I were on a machine with a tiny cache, the speed up from attempting to find locality may not be worth it, right? In places where multiple types of machines and hardware are used, I'd imagine there is a bit of a tradeoff that needs to be considered.
This comment was marked helpful 0 times.
shabnam
This is a really interesting example as it correctly shows that sometimes doing extra work for assignment or balancing might lead to over all higher speedups.
As mentioned on the previous few slides, the "cost-zone assignment" increases locality, and reduces the overall execution time compared to static assignment.
However, it is interesting to note: computing this processor workload distribution has a cost. As you can see in the graphs above, the "busy" section of the graphs is higher on the "cost-zone assignment" implementation than on the "static random assignment" implementation.
Moral of the story? Doing more work to preserve locality and maintain a balanced workload still has the potential to decrease overall computation time.
This comment was marked helpful 0 times.
Looking at the complexity of writing code for the extra assignment computation, and only 5s of increase in time (compared to the total 30s), is this really worth it? Can we really argue that the right hand side approach uses the resources better?
This comment was marked helpful 0 times.
@selena731: I guess it just matters how much performance you want to squeeze out, and how willing you are to obtain it. The more advanced assignment scheme improves performance by about 15% over random assignment.
This comment was marked helpful 0 times.
Programming to eliminate bandwidth problems seems to be programming to the hardware. If I were on a machine with a tiny cache, the speed up from attempting to find locality may not be worth it, right? In places where multiple types of machines and hardware are used, I'd imagine there is a bit of a tradeoff that needs to be considered.
This comment was marked helpful 0 times.
This is a really interesting example as it correctly shows that sometimes doing extra work for assignment or balancing might lead to over all higher speedups.
This comment was marked helpful 0 times.