In class we walked through a couple of scenarios like this, incrementally decreasing either the length of the critical path or the total number of messages. This particular slide has a critical path of length 3 with 4 messages. P0 asks P1 for some data, but the response to P0's request actually comes from P2. This eliminates the latency of the response going through P1 to get from P2 to P0.
This comment was marked helpful 0 times.
ycp
So something I was thinking about was whether or not this method was faster or slower than simply updating each processor. Surely, there is a great benefit from not having to crowd the the interconnect, but by updating each processor, the critical path (in span) would be 2 correct? One processor sends a message to each other and waits for a response from each of them. Ideally, this could be faster, but I guess the problem is scalability as we are getting better at packing more cores on a chip right?
This comment was marked helpful 0 times.
mofarrel
The entire point of the directory scheme is to avoid broadcasts if possible, as these are slow and create contention (for the bus). The directory allows us to directly address only the processors that have a cache line instead of all the processors. Your scheme would make the directories pointless by requesting a line from all processors.
This comment was marked helpful 0 times.
squidrice
A potential problem for this implementation is the irregular pairing of send and receive. For processor 0 in the slide, it sends a request to the directory of processor 1, yet the response is from processor 2. It's not like the regular scene where send and receive only involve two participants and may need more complex strategy to handle the response.
This comment was marked helpful 0 times.
benchoi
@squidrice: Instead of looking at which processor ID a message was sent to/received from, the requests and responses can be tagged with a request ID. That could be a counter, which raises the problem of how such a shared counter would be maintained, or a random 32-bit number (which raises the problem of collisions, I suppose).
This comment was marked helpful 0 times.
retterermoore
benchoi - maybe if you have P processors, each processor could keep track of how many messages it's sent out and label each message's ID as P*x + n, where x is the number of messages that processor has sent out and n is the unique label of the processor.
So for example, if we have 7 processors, processor 0 would label its first message 0, its second message 7, etc, while processor 1 would label its first message 1, second message 8, etc.
This way we just need to assign each processor a number at the start and have each processor locally keep track of 2 numbers, and we'd guarantee that every message had a unique ID (plus you could figure out which processor the message came from just by looking at the ID)
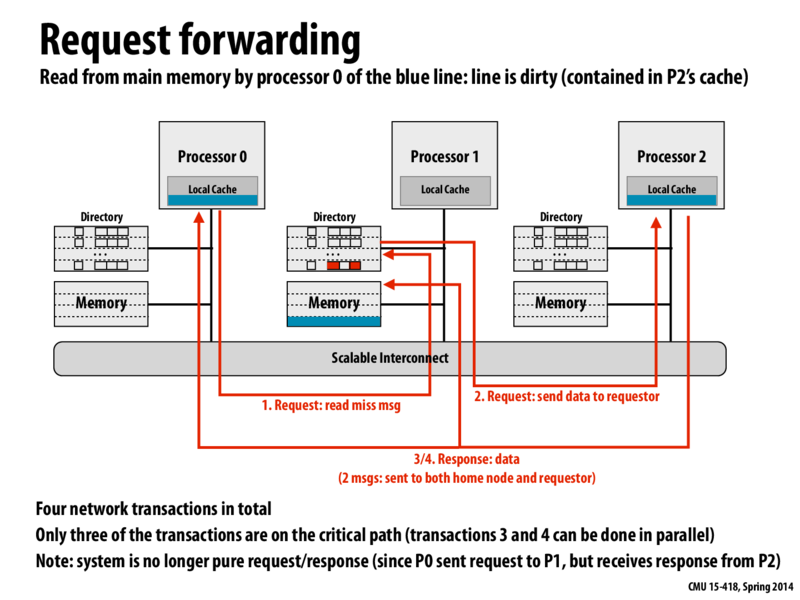
In class we walked through a couple of scenarios like this, incrementally decreasing either the length of the critical path or the total number of messages. This particular slide has a critical path of length 3 with 4 messages. P0 asks P1 for some data, but the response to P0's request actually comes from P2. This eliminates the latency of the response going through P1 to get from P2 to P0.
This comment was marked helpful 0 times.
So something I was thinking about was whether or not this method was faster or slower than simply updating each processor. Surely, there is a great benefit from not having to crowd the the interconnect, but by updating each processor, the critical path (in span) would be 2 correct? One processor sends a message to each other and waits for a response from each of them. Ideally, this could be faster, but I guess the problem is scalability as we are getting better at packing more cores on a chip right?
This comment was marked helpful 0 times.
The entire point of the directory scheme is to avoid broadcasts if possible, as these are slow and create contention (for the bus). The directory allows us to directly address only the processors that have a cache line instead of all the processors. Your scheme would make the directories pointless by requesting a line from all processors.
This comment was marked helpful 0 times.
A potential problem for this implementation is the irregular pairing of send and receive. For processor 0 in the slide, it sends a request to the directory of processor 1, yet the response is from processor 2. It's not like the regular scene where send and receive only involve two participants and may need more complex strategy to handle the response.
This comment was marked helpful 0 times.
@squidrice: Instead of looking at which processor ID a message was sent to/received from, the requests and responses can be tagged with a request ID. That could be a counter, which raises the problem of how such a shared counter would be maintained, or a random 32-bit number (which raises the problem of collisions, I suppose).
This comment was marked helpful 0 times.
benchoi - maybe if you have P processors, each processor could keep track of how many messages it's sent out and label each message's ID as P*x + n, where x is the number of messages that processor has sent out and n is the unique label of the processor.
So for example, if we have 7 processors, processor 0 would label its first message 0, its second message 7, etc, while processor 1 would label its first message 1, second message 8, etc.
This way we just need to assign each processor a number at the start and have each processor locally keep track of 2 numbers, and we'd guarantee that every message had a unique ID (plus you could figure out which processor the message came from just by looking at the ID)
This comment was marked helpful 0 times.