






Cilk has other constructs used for parallelism. One pretty neat thing that I found was the concept of reducers, which can be used instead of locks to deal with data races. They also preserve ordering (for example, when used in a cilk_for).
This comment was marked helpful 0 times.

The difference between cilk_sync and barrier is the number of living threads after that point. There is only one thread passing cilk_sync after all the other ones return. While the number of threads keeps the same after barrier.
This comment was marked helpful 0 times.

One important thing to note for the semantics of cilk_spawn is that it makes no guarantees on when the function will be invoked, just that it will be concurrently invoked sometime in the future. Therefore, cilk_sync is used as a scheduling primitive in this system.
This is also discussed later on in this slide.
This comment was marked helpful 0 times.
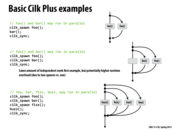

The second illustration is a bad usage of cilk_spawn because it created a thread of control that is useless.
This comment was marked helpful 0 times.

Would the second example really be that much slower? It seems like the thread that's doing nothing would just immediately block on cilk_sync and not be awoken until the other threads have finished, which should involve only very minimal overhead...
This comment was marked helpful 0 times.

I don't think case 2 is bad because its aim is just to mark a place to sync all the threads. It will not waste a thread because of stealing. Without the continuation, it's hard to tell the compiler when to sync all the spawned threads.
This comment was marked helpful 0 times.

I don't see why it would be harder for the compiler to see when to sync all the threads if we do not leave the main thread idle. I think whether case 2 is bad depends on the task.
This comment was marked helpful 0 times.



Note about synchronization -- notice that there are no cilk_syncs. In fact, this sync is not required, since there are implicit syncs at the end of each function call. If this implicit sync did not exist, the code would actually have a race condition. At the highest level (before we start recursing), we see that we spawn a thread to sort [begin, middle], and then we directly sort [middle + 1, last]. If we return from sorting [middle + 1, last] before the cilk_spawn's sort is done, then we could potentially return from quicksort before we have sorted the first half of the list. However, as I mentioned earlier, the implicit sync prevents this issue.
This comment was marked helpful 0 times.

We described in lecture how quick sort is not a very good sorting algorithm to scale to many cores. This is because of the linear amount of work that needs to be done at each level, leading to a linear span. Given that the work complexity of quick sort is O(nlogn), this leads to a speedup of log(n)
In systems with many cores, a distributed sorting algorithm like bucket sort, which partitions the elements into an arbitrary number of buckets at the top level, depending on the number of cores in the system, rather than partitioning the elements in half at each level, would be better for parallelism.
This comment was marked helpful 0 times.


It's important to note that the purpose of Cilk is to expose independent work rather than actually schedule it. Cilk essentially leaves the actual assignment of work to each processor to the scheduler, and so can run on any potential number of processors, including only one. This is also a reason why we might use Cilk over spawning pthreads ourselves.
This comment was marked helpful 0 times.

I'm confused why having more independent work means a higher granularity of work. I get that if we have 10 lists to sort and 3 processors, we have some slack, so if the lists take different amounts of time to finish, we can give the leftover ones to the processors that finish sooner, which lets us use our parallel power more efficiently than if we had 10 lists to sort and 10 processors. But why would having 100 lists to sort and 3 processors mean that we had to manage fine-grained work? Is it just that we would have to assign 100 lists to processors, and the time spent on that computation would be overhead?
This comment was marked helpful 0 times.

@retterermoore Yes, having managing 100 diferent cilk threads results in more overhead than 10. This is why on a previous slide on quicksort, there is a conditional check to see if there are enough elements to warrant spawning another cilk thread, otherwise it would be fast to simply do the sort on a single thread.
This comment was marked helpful 0 times.
I believe that last bullet point is talking about assigning work to processors where the workload is kept constant. Therefore, making more independent work would increase the granularity of it.
This comment was marked helpful 0 times.

I think the last bullet point is saying that there's a balance between breaking work up into many small pieces so that we can divide it more evenly, and keeping relatively large pieces of work so that we don't have to manage too many pieces while still balancing the workload.
This comment was marked helpful 0 times.



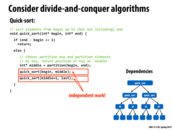
In lecture we discussed how placing foo in work queue is better than putting the continuation in work queue. Why?
This comment was marked helpful 0 times.

@shabnam: We didn't necessarily say categorically that placing foo in the work queue is better than putting the continuation in the work queue. In fact, in the case where worker threads can "steal" work from other queues, putting the continuation into the queue might be the better strategy because then stealing would involve stealing more work (assuming that the continuation spawns off more threads). Further on in the lecture, it actually mentions that in the case where the continuation spawns off more threads and we place the continuation in the queue, there is a provable bound on the work queue storage for a system with T threads. However, one benefit of placing children in the work queue and continuing to execute the continuation is that it exposes all of the parallelism present in the program at the outset.
This comment was marked helpful 0 times.

Also, as mentioned in the lecture, run child first would be a little computational easier, since there is less registers to save for caller saved registers.
This comment was marked helpful 0 times.





The stealing idea is similar to that of keeping a queue at the master level of assignment 4. Since we had I/O intensive work as well as compute intensive work,the idea of giving work to other thread somewhat resembles the homework problem.
This comment was marked helpful 0 times.


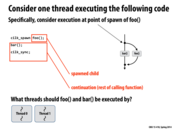
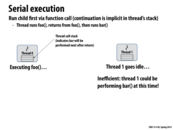
At first I found child stealing/continuation first vs. continuation stealing/child first to be confusing, so I'm going to try to explain the differences between them.
I thought child stealing was easier to understand. I think the way it works is the system keeps executing the continuation and puts the child on thread 0's work queue. Then the child is available to be stolen by other threads in the system.
With continuation stealing, it seems like what happens is that thread 0 immediately starts executing the child and then puts the continuation (from the current point onward) on its work queue. Then the continuation is available to be stolen by other threads. If a thread steals the continuation and it spawns more children, those children will be immediately executed by the thread and the continuation from the new current point will be put on the queue again and be available to be stolen.
This comment was marked helpful 0 times.

I'm going to try to explain continuation first and child first a little bit differently.
When a system runs continuation first, a thread adds all of the child calls to its work queue before attempting to execute any of them. Anything in the body of the continuation up cilk_sync will be executed sequentially, and the work in the cilk_spawns will be added to the queue in order. Then, once the thread reaches cilk_sync, it will run any children still in the queue in order. This allows other threads to steal any of the child calls.
When a system runs child first, each time a thread reaches a call to cilk_spawn, it will execute that work, and put the rest of the calling function (the continuation) into its queue. This allows other threads to steal the (potentially very large) continuation while this thread is executing the first child.
This comment was marked helpful 0 times.

Fork-join parallelism (here the kind expressed by cilk), creates a dependency tree. Certain information must be computed prior to a specific cilk_sync call. We can compute answers to this dependency tree in different orders. Here computing the continuation first, and putting the child on the work queue, corresponds to a BFS traversal. On the other hand, computing the child first, and putting the continuation on the work queue, corresponds to a DFS traversal. One could imagine coming up with many other ways to traverse the dependency tree that could lead to performance improvements.
This comment was marked helpful 0 times.


It seems that the downside of running the continuation first (at least in this example) is that it might fill up your work queue very quickly, and now you have the problem of deciding what to do when your work queue is full.
This comment was marked helpful 0 times.

With child stealing, we have to have O(N) space in the queue to fit all the spawned children. This could potentially use a very large amount of space if there is a lot of work spawned before any other thread has the chance to steal some. As @jinsikl mentioned, we would need a way to decide what to do when the queue is full, so that we can keep spawning children in the continuation.
This comment was marked helpful 0 times.

A quick summary of one of the benefits of continuation stealing -- In code like this, which assumes that the continuation will spawn more threads, stealing the continuation means "stealing a large chunk of work", which implies the overhead cost of stealing is actually worth it.
This comment was marked helpful 0 times.

For those of us who are in 312, this concept should remind us of streams we had to face on the midterm.
This comment was marked helpful 0 times.


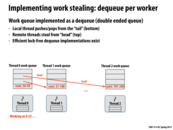


It would be much more beneficial to steal from the top of dequeue because
- we can reduce the overhead from communication by exchanging a "larger" piece of work.
- With run-child-first policy, the local thread would only push and pop at the bottom of dequeue which would potentially increase cache locality.
- Also, stealing from other threads and pushing and popping from local thread would not interfere that much and we could reduce contention to work queue.
This comment was marked helpful 1 times.

This paper written by one of the founders of Cilk arts details scheduling work items by stealing. In particular, it mentions that if an idle thread randomly chooses a thread to steal from but that thread also has an empty queue, then the first thread will uniformly at random choose another thread to steal from. More interestingly though, the paper talks about the motivation behind choosing to steal work instead of having a scheduler distribute the work. The idea is that when a scheduler distributes work, it is always distributing available work even to workers that are busy working. If instead threads steal work only when they're idle, then when all threads are busy, no work will be migrated around. Thus the paper claims that the overall amount of work migrated would be less when work is stolen rather than distributed.
This comment was marked helpful 0 times.

If most of the threads are idle (e.g. one of them is working on a large task and the rest have nothing to do), it seems that they will all be trying to steal from each other repeatedly and unsuccessfully. Would that generate enough overhead to be a significant problem, or does that not matter?
This comment was marked helpful 0 times.

Why is stealing done randomly, instead of keeping track of the size of work queue (or at least estimate it) and stealing from a thread with a lot of work queued up? It seems to make more sense, especially when only a few threads have work.
This comment was marked helpful 0 times.

@eatnow, I imagine they're trying to avoid some sort of global data structure like that because of the pain of doing synchronization on it, as well as the extra coherence traffic. Random guessing probably has much less overhead in the normal case.
This comment was marked helpful 0 times.
@sluck. It's helpful! You guys are great!
This comment was marked helpful 0 times.

Can we have more clarity on why the recursive_for solution is better? and in which scenarios is it better?
This comment was marked helpful 0 times.

The recursive_for is better in this situation where we are going to iteratively spawn a new thread of control, there are a lot of iterations in the loop, and we have a child-first work stealing scheduler. When looking at the example, the program on the left will have a thread take foo(0) and put the continuation in the queue, and then another thread can take foo(1) and put the continuation in its queue, and so on. This will have each iteration of the for loop be added to a work queue sequentially an the work will get started slower. With the right program however, the work will be add to the queue in a tree like manner. Basically the threads of control will keep breaking the working up in halves and then start executive foo(i) in whatever range it has. Basically it allows the work to be distributed to the threads faster. If you expanded the branching of the diagrams at the bottom, you would see that the work is being distributed between the threads a lot faster on the recursive_for example.
This comment was marked helpful 1 times.
From what I understand of the two approaches, the right one saves space on the queue, and also increases time spent on real work per queue pop (since the work division is in bigger granularity).
This comment was marked helpful 0 times.

How would we go about calculating the ideal GRANULARITY constant for the cilk recursive function call. I realize that cilk is not an actual execution framework so the results might be highly dependent on the hyper threading available on the system or other system specific attributes. Still, I feel that ideal GRANULARITY could still be affected by cilk intrinsics and the stealing mechanisms underneath cilk.
This comment was marked helpful 0 times.
To me, silk is designed and optimized for divide-and-conquer programming paradigm. So everything that looks like divide-and-conquer will possibly run better. Here, we just changed the iterative loop into a divide-and-conquer look.
This comment was marked helpful 0 times.

It seems like the bookkeeping for stolen work is a global data structure is that right? Otherwise people would have to notify thread0 even if thread0 might be done with its own work and start stealing other stuff.
This comment was marked helpful 0 times.
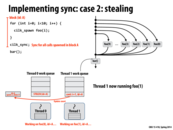
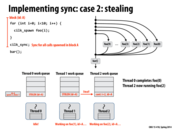

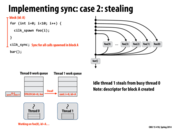
As explained in class, each processor has a queue (although it is also a stack) that work resides in. When a processor goes idle, it chooses another random processor from which to steal work from, and then attempts to steal the work. Each processor can only steal take work from either its own work queue's front, or from another work queue's back. The reasoning is because if we are working on our own queue, we would like to do the work that is next in line; however, if we're stealing work from another processor, we want to take only the work that they would get to last.
This comment was marked helpful 1 times.

The reason we want the stealer to get the later work from the thread they are stealing from is because that work is further away in likely both time and space. This means that the original worker thread will be more likely to preserve cache locality when transitioning from one task to the next, rather than skipping over tasks because some had been stolen out from underneath it.
This comment was marked helpful 2 times.
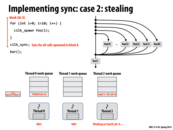
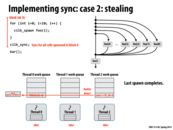
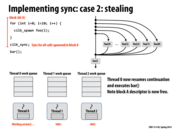
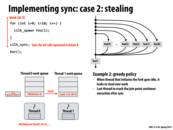
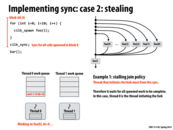
The greedy policy is better because other thread which finishes its work does not need to worry about the sync point, since the only the last thread reaches the sync point is responsible for it. If in the first approach, the spawn threads instead tries to find some other work to do, it may not respond quickly when the last thread finishes to deal with the sync point. Also, I think the block id A is needed as there might be other cilk_spawn outstanding, so the id A is a unique identifier for this spawn work.
This comment was marked helpful 0 times.
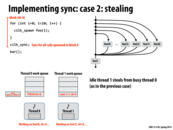
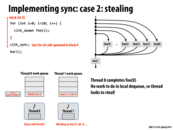
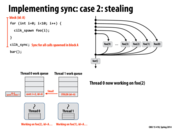
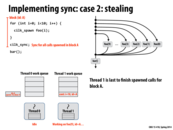
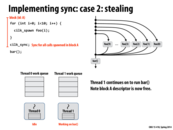

In the greedy policy, what bookkeeping is needed when a processor steals? Since we don't need to know what thread initiated work (since we implement sync by continuing work on the last thread), what else is there to keep track of?
This comment was marked helpful 0 times.
I am pretty sure the bookkeeping refers to popping the work from the double ended queue.
This comment was marked helpful 0 times.

One of the overheads is the reference counting of completed children that needs to occur after a steal. If a processor completes its current task, then looks at the bottom of the dequeue and sees there's no more work because of a steal, then the processor needs to make sure the caller frame (managed elsewhere at this point) gets notification that this child task has completed. I'm not sure about Cilk Plus specifically, but the research versions of Cilk lazily created these structures only when work was actually stolen.
This comment was marked helpful 0 times.

Just wanted to note that threads steal from random cores, not nearby ones.
The reason why is explained in this faq on the main site for Cilk. They also answer some other interesting queries one might have such as why they use a dequeue rather than a FIFO queue :
This comment was marked helpful 0 times.

What causes the gaps along the time (clocks) axis within each stage? For example, why doesn't the green transaction's part on the response bus occur earlier?
This comment was marked helpful 0 times.
This looks like a cache protocol so possibly the gaps on the request bus are waiting for other processors to acknowledge the request? I'm not sure about the gap in the response bus though...
This comment was marked helpful 0 times.
The gaps in the request bus are periods of bus inactivity when all the nodes are performing the snoop (slide). The gaps between the end of a request and the start of a response for a particular transaction are due to latency of handling the request (ex: retrieving a cache line from main memory).
This comment was marked helpful 0 times.