Note about synchronization -- notice that there are no cilk_syncs. In fact, this sync is not required, since there are implicit syncs at the end of each function call. If this implicit sync did not exist, the code would actually have a race condition. At the highest level (before we start recursing), we see that we spawn a thread to sort [begin, middle], and then we directly sort [middle + 1, last]. If we return from sorting [middle + 1, last] before the cilk_spawn's sort is done, then we could potentially return from quicksort before we have sorted the first half of the list. However, as I mentioned earlier, the implicit sync prevents this issue.
This comment was marked helpful 0 times.
arjunh
We described in lecture how quick sort is not a very good sorting algorithm to scale to many cores. This is because of the linear amount of work that needs to be done at each level, leading to a linear span. Given that the work complexity of quick sort is O(nlogn), this leads to a speedup of log(n)
In systems with many cores, a distributed sorting algorithm like bucket sort, which partitions the elements into an arbitrary number of buckets at the top level, depending on the number of cores in the system, rather than partitioning the elements in half at each level, would be better for parallelism.
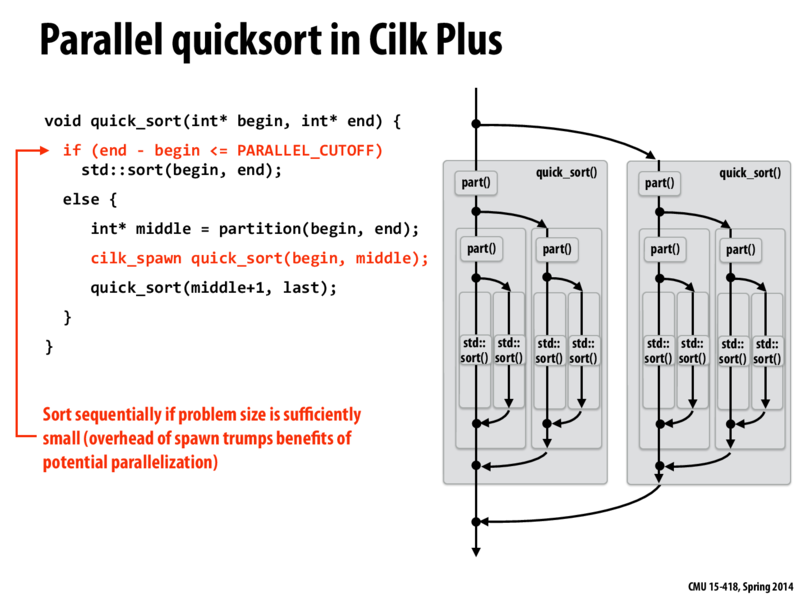
Note about synchronization -- notice that there are no cilk_syncs. In fact, this sync is not required, since there are implicit syncs at the end of each function call. If this implicit sync did not exist, the code would actually have a race condition. At the highest level (before we start recursing), we see that we spawn a thread to sort [begin, middle], and then we directly sort [middle + 1, last]. If we return from sorting [middle + 1, last] before the cilk_spawn's sort is done, then we could potentially return from quicksort before we have sorted the first half of the list. However, as I mentioned earlier, the implicit sync prevents this issue.
This comment was marked helpful 0 times.
We described in lecture how quick sort is not a very good sorting algorithm to scale to many cores. This is because of the linear amount of work that needs to be done at each level, leading to a linear span. Given that the work complexity of quick sort is O(nlogn), this leads to a speedup of log(n)
In systems with many cores, a distributed sorting algorithm like bucket sort, which partitions the elements into an arbitrary number of buckets at the top level, depending on the number of cores in the system, rather than partitioning the elements in half at each level, would be better for parallelism.
This comment was marked helpful 0 times.