Note that the block dimensions (as determined by threadsPerblock) does not divide Nx and Ny evenly, this the global device function has to guard for out-of-bounds array accesses.
This comment was marked helpful 0 times.
rokhinip
Question: Why is the kernel launch not like map(kernel, collection)? As we've seen so far in the examples and the code that we've written in assignment 2, the CUDA code is data parallel and I believed we used the map analogy to illustrate that in the earlier lecture.
Edit: I noticed that it says that number of kernel invocations is not related to the size of the data set. Presumably, map(kernel, collection) implies a dependence on the size of the collection and so, we can't draw similarities between a kernel launch and the map. Nevertheless, am I right to say that CUDA is an example of the data parallel model?
This comment was marked helpful 0 times.
kayvonf
@rokhinip. Yes and no. (mostly yes). CUDA kernel launch is very much data parallel in spirit as you suggest. You can think of the "collection" in this case as being the resulting stream of blocks.
However, what is not a data parallel abstraction are CUDA threads in a thread block. Those threads are much more like conventional threads than independent iterations of a for loop. They are not assumed to be independent (as they can synchronize using __syncthreads) and they have semantics of running concurrently.
This comment was marked helpful 0 times.
rokhinip
@kayvonf: I see. So on the thread blocks level of abstraction, we can say that we have data parallelism since they can be executed in any order on the cores of the GPU. However, for the threads within a thread, since they communicate with each other through __shared memory and __syncthreads(), they probably fall closer to the shared address space model.
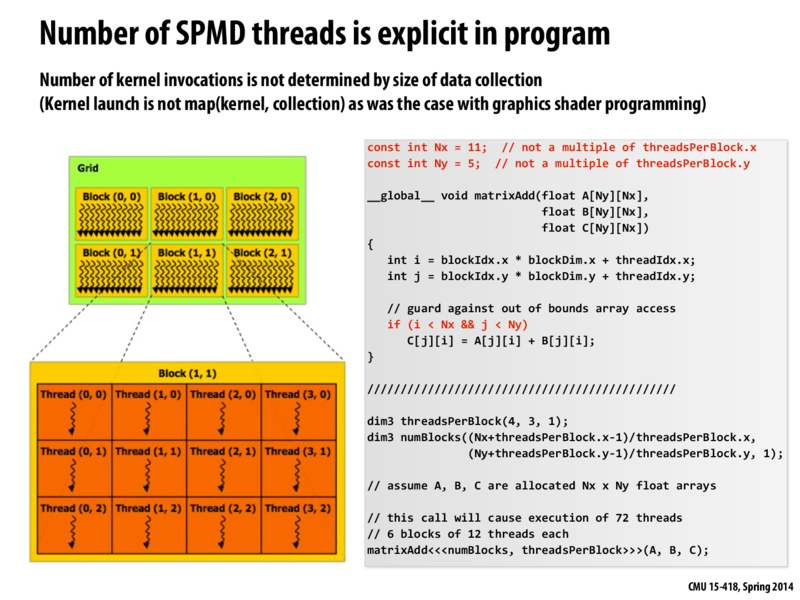
Note that the block dimensions (as determined by
threadsPerblock) does not divideNxandNyevenly, this the global device function has to guard for out-of-bounds array accesses.This comment was marked helpful 0 times.
Question: Why is the kernel launch not like map(kernel, collection)? As we've seen so far in the examples and the code that we've written in assignment 2, the CUDA code is data parallel and I believed we used the map analogy to illustrate that in the earlier lecture.
Edit: I noticed that it says that number of kernel invocations is not related to the size of the data set. Presumably, map(kernel, collection) implies a dependence on the size of the collection and so, we can't draw similarities between a kernel launch and the map. Nevertheless, am I right to say that CUDA is an example of the data parallel model?
This comment was marked helpful 0 times.
@rokhinip. Yes and no. (mostly yes). CUDA kernel launch is very much data parallel in spirit as you suggest. You can think of the "collection" in this case as being the resulting stream of blocks.
However, what is not a data parallel abstraction are CUDA threads in a thread block. Those threads are much more like conventional threads than independent iterations of a for loop. They are not assumed to be independent (as they can synchronize using
__syncthreads) and they have semantics of running concurrently.This comment was marked helpful 0 times.
@kayvonf: I see. So on the thread blocks level of abstraction, we can say that we have data parallelism since they can be executed in any order on the cores of the GPU. However, for the threads within a thread, since they communicate with each other through __shared memory and __syncthreads(), they probably fall closer to the shared address space model.
This comment was marked helpful 0 times.