





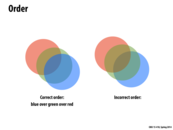



The trivially parallel renderer fails on a number of levels. The color of the circle intersections are incorrect because the color rendering is done in the incorrect order--in fact, it's entirely non-deterministic, whereas to be correct it must be in reverse depth order. The artifacts are the result of nonatomic rendering--the rendering has stripes because the execution of different threads is interleaved, whereas each layer of rendering should be dependent on the previous layer.
This comment was marked helpful 0 times.

To further clarify, some stripes appear solid green because the thread responsible for that portion of the image has essentially "overridden" concurrent contributions (by red, blue circles) due to the non-atomicity of the the pixel-write operation.
This comment was marked helpful 0 times.

Could someone clarify for me whether the second picture here (the square one) is the same algorithm that is trying to draw the 3 circles (and failing artistically), or another one just to demonstrate interleaving.
This comment was marked helpful 0 times.

@sss The square photo is an example of 10K random circles drawn "correctly" (ie. preserving ordering and atomicity).
This comment was marked helpful 0 times.







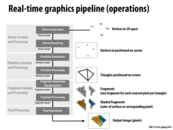

By "triangles positioned on screen"/"primitive generation" does that mean every single vertex is connected to every other one (basically like a complete graph) or are just some of the vertices connected?
This comment was marked helpful 0 times.

The are several modes of how to group vertices into triangles. The simplest is to say every group of three vertices in the input vertex stream defines a triangle. More complicated modes also exist, as the triangle strip, shown here. A full listing of OpenGL supported primitive modes is here.
This comment was marked helpful 0 times.

In the past while dabbling in OpenGL, it was always strange to me why they decided to call "fragment shaders" what I thought of as "pixel shaders". Now it all makes sense. The fragment shaders that you write in GLSL determine the color of a pixel-like object, which is called a fragment. But, the actual color of the pixel on the screen is a combination of fragments. OpenGL blends those overlapping fragments differently depending on whether or not blending is enabled and what the blend function is set to.
This comment was marked helpful 0 times.



To elaborate further, graphics programming APIs moved away from the parametrized model for displaying materials and lights because it was too limiting in terms of the materials that could actually be displayed (i.e. only particular fields could be edited, thus allowing for a limited amount of materials possible). As seen in the next few slides, giving the user control of certain parts of the pipeline logic resulted in opening up the possible graphics that could be displayed.
This comment was marked helpful 0 times.
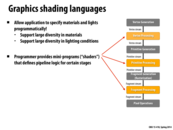

It seems like this entire pipeline could be turned into code (like we are doing with the renderer in assignment 2), instead of having certain portions implemented in hardware. Is this where GPUs are heading? Or would this sacrifice to much graphics performance?
This comment was marked helpful 0 times.
@mofarrel. A great question that researchers continue to wrestle with. The question is whether the loss of efficiency (performance, power, etc.) is justified by the greater flexibility afforded by implementing more of the pipeline in software. Some friends and I made one attempt, called GRAMPS a couple of years back. Some of my Ph.D. students are continuing to think about this question.
This comment was marked helpful 0 times.





If the color was being used to encode the particle position, doesn't this significantly limit the bounds of the particle position based on the number of available colors? (I am assuming that the output array size corresponds to the number of particles in the simulation rather than the number of available positions... is this correct?)
This comment was marked helpful 0 times.



So when a GPU receives work/instructions, how does that affect that actual graphics processing? Are the completely separated? What happens when the GPU receives computational instructions and instructions to produce graphics at the same time?
This comment was marked helpful 1 times.
To my knowledge, modern GPU implementation time multiplex the GPU between executing compute mode programs and graphics mode programs. (They run compute mode program, then the driver context switches to a graphics one much like how an OS context switches processes onto a CPU.) Going forward, GPUs will evolve to be able to run graphics work and compute mode work concurrently. (I may be wrong, and it might be possible to already do so on the latest GPUs today. Someone should try and figure that out.)
This comment was marked helpful 0 times.
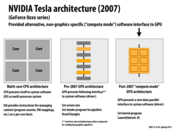


Question: How would you compare the following programming abstractions:
- a CUDA thread
- a CUDA thread block
- a pthread
- ISPC program instance
- ISPC task
This comment was marked helpful 0 times.

To answer the question in the slide, I would say CUDA is both a data-parallel model and a shared address space model. It's data-parallel since the 'device' codes execute on multiple data like SPMD. And we know that thread blocks have some shared memory. From abstraction's perspective, the model provides '__shared__' to explicitly define shared data. And from the implementation details, we know that GTX480/680 has an L1 data cache acting as shared memory. But is CUDA also a message passing model? Since we can use 'cudaMemcpy' between the host and the device, does it count as message passing?
This comment was marked helpful 0 times.



blockIdx.x ranges from 0 to 2, as there are three blocks along the x dimension.
blockDim.x is equal to 4, as this is the size of a block in the x dimension.
threadIdx.x refers to the index within one block along the x dimension. It ranges from 0 to 3.
This comment was marked helpful 6 times.

Are there any limitations to the dimensions/size of the block? I know at the end of lecture we said a block couldn't have more than 2048 threads which makes sense since each core is limited to 2048 threads and a block has to run in entirety on a core, but are there other requirements?
This comment was marked helpful 0 times.

There are limitations based on the GPU you are using, you can run some query for the GPU device in CUDA, there are samples code in CUDA 5.5, you can install them in Mac/Linux/Windows, and just run the device query program, it will show a lot information and limitation about your GPU.
This comment was marked helpful 0 times.

@tchitten I think CUDA compute capabilities table tells you the details.
This comment was marked helpful 0 times.

The dim3 thing in CUDA is to facilitate calculation on two dimensional or three dimensional arrays. Then no need to do the index conversion, just use it as it is defined.
This comment was marked helpful 0 times.


I was looking at the code above, and thought that there has to be a wrapper function for the part that's below ///// line. In other words, starting from dim3 threadsPerBlock (..) .. till the Kernel call has to be within a wrapper function. But it's not shown here in the slides. Is that right?
I am not sure what dim3 means. In the assign. base code, number of blocks and number of threads are given as constants. How does that differ from this?
This comment was marked helpful 0 times.

If we're thinking in C/C++, the code below ///// would probably be included in your main() function.
According to this useful link, dim3 is a vector of 3 elements (x, y, and z), so threadsPerBlock(4,3,1) initializes the threadsPerBlock vector with x=4,y=3,z=1. Notice that in the example above, thread indexes (threadIdx) and block indexes (blockIdx) also have 3 components: an x, y, and z, rather than the usual single-valued index. By specifying that the number of threads in a block is 4x3x1, we tell CUDA not only that there are 4x3x1=12 threads in a block, but also that the threads in each block should have indices that span 4 x-values, 3 y-values, and 1 z-value. For example the 12 threads in the first block will have the following x-y-z indices:
(0,0,0), (1,0,0), (2,0,0), (3,0,0)
(0,1,0), (1,1,0), (2,1,0), (3,1,0)
(0,2,0), (1,2,0), (2,2,0), (3,2,0)
Similarly, the block indices are in a Nx/threadsPerBlock.x by Ny/threadsPerBlock.y by 1 array.
This is helpful for indexing into data when the data being processed in parallel has more than one dimension; for example a 12x3 element 2-D array, where you want each block of threads to process a 4x3 section of that array. The previous slide illustrates this quite well.
This comment was marked helpful 1 times.

I thought CUDA execution was asynchronous with the CPU threads. If the call to matrixAdd doesn't return until all threads have terminated, why do we need cudaThreadSynchronize?
This comment was marked helpful 0 times.
@adsmith. Your understanding is correct. The call to matrixAdd may return prior to the GPU completing the work associated with the launch call. A more lengthly discussion is here.
This comment was marked helpful 0 times.


__global__ denotes a function that can only be called from host (run by CPU) and must return void.
__device__ denotes a function that can only be called from device (run by GPU) and can return anything.
(From Slide 24 of CUDA Programming Model Overview, NVIDIA Corporation 2008)
This comment was marked helpful 2 times.

So what exactly is the difference between __device__ and __global__ again? I'm a little confused.
This comment was marked helpful 1 times.

So basically functions marked with __global__ are called by host (CPU) and executed on GPU, whereas __device__ are functions that are called by device (GPU) and also executed on GPU.
This comment was marked helpful 5 times.

To add to that, I think of global functions as "global" in that they span across the host and device (host calls functions to be executed on the device, as @yuyang mentions), and device functions as "device" in that they only involve the device (a device might call a device function as a subroutine or helper function).
This comment was marked helpful 0 times.

Note that the block dimensions (as determined by threadsPerblock) does not divide Nx and Ny evenly, this the global device function has to guard for out-of-bounds array accesses.
This comment was marked helpful 0 times.

Question: Why is the kernel launch not like map(kernel, collection)? As we've seen so far in the examples and the code that we've written in assignment 2, the CUDA code is data parallel and I believed we used the map analogy to illustrate that in the earlier lecture.
Edit: I noticed that it says that number of kernel invocations is not related to the size of the data set. Presumably, map(kernel, collection) implies a dependence on the size of the collection and so, we can't draw similarities between a kernel launch and the map. Nevertheless, am I right to say that CUDA is an example of the data parallel model?
This comment was marked helpful 0 times.
@rokhinip. Yes and no. (mostly yes). CUDA kernel launch is very much data parallel in spirit as you suggest. You can think of the "collection" in this case as being the resulting stream of blocks.
However, what is not a data parallel abstraction are CUDA threads in a thread block. Those threads are much more like conventional threads than independent iterations of a for loop. They are not assumed to be independent (as they can synchronize using __syncthreads) and they have semantics of running concurrently.
This comment was marked helpful 0 times.
@kayvonf: I see. So on the thread blocks level of abstraction, we can say that we have data parallelism since they can be executed in any order on the cores of the GPU. However, for the threads within a thread, since they communicate with each other through __shared memory and __syncthreads(), they probably fall closer to the shared address space model.
This comment was marked helpful 0 times.

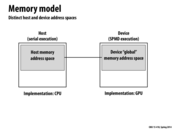

deviceA acts as a handle. The address space of the GPU is (in this example) separate from the CPU's address space, and for this reason, deviceA is a reference.
There is no real reason that deviceA is a float * -- Kayvon mentioned in class that it could have been typedef'd to a more distinguishable type.
This comment was marked helpful 0 times.
If we were to copy memory from device to host, would we use something along the lines of "cudaMemcpyDeviceToHost" as the 4th param of "cudaMemcpy"?
edit: It indeed looks like we do :)
This comment was marked helpful 0 times.

@kkz
I think one of the caveats is "cudaMemcpyDeviceToDevice", if you want to copy from one device address space to another. It seems if the fourth enum value is wrong there would be a segment fault in runtime.
This comment was marked helpful 0 times.

In lecture there was some explanation of why this implementation of cudaMalloc is very "forward looking" but I'm still not completely sure I understand. So the reason why cudaMalloc returns a float* (a pointer pretty much) is that it expects that in the future there will be global shared address space between the cpu (host) and gpu (device). Then we would actually be passing in a pointer for some address in memory. However, since that hasn't happened, the pointer acts like a handle that is used to by cudaMemcpy to copy the message to. The pointer can't actually be accessed like an actual pointer by the host.
This comment was marked helpful 0 times.
@kkz Yes that's right and CUDA library doc about cudaMemcpy tells you what other values you can use for 4th parameters.
There are
cudaMemcpyHostToHost Host -> Host
cudaMemcpyHostToDevice Host -> Device
cudaMemcpyDeviceToHost Device -> Host
cudaMemcpyDeviceToDevice Device -> Device
cudaMemcpyDefault Default based unified virtual address space
Also, note that cudaMemcpy's first parameter is always destination pointer and second argument is source pointer. It is easy to overlook the fact!
This comment was marked helpful 0 times.

It should be noted memory allocated with cudaMalloc can only be 'dereferenced' or 'set' in a kernel function or with a call to cudaMemcpy. Remember that cudaMalloc allocates memory on the device, which is different from the host memory. So, you can't dereference device memory when on the CPU side (host side).
(source: personal mistake; trying to set the last element of the array after the upsweep phase in scan to 0 outside the kernel function/without using cudaMemcpy. This yields a seg-fault, which can be confusing if the distinction between host memory and device memory is not clear).
This comment was marked helpful 1 times.
Also, note that the signature for cudaMalloc is cudaError_t cudaMalloc(void **devPtr, size_t size). The reason for using a void** instead of a void* (as you might expect from using malloc/calloc) is that all CUDA functions return an error-code explaining why it failed (if it did). A full explanation is given here
If this is confusing, it's because it is; the same thread mentions that a far better API design would have simply added another argument to the function as a sort of 'error-code storage argument' (quite similar to the int* status argument in the waitpid function, which can be probed to see what caused the process to terminate).
This comment was marked helpful 1 times.

I was on anandtech and I saw that AMD has recently released "HSA," which allows for their integrated CPU and GPU on the same chip to share exactly the same address space, just like Kayvon said. Obviously it's faster to have the GPU and CPU share the same address space because copies aren't required, but also pointed out in what I read was that structures with pointers in them (like linked lists or trees) need to have their pointers rewritten when they get copied to another address space. With one address space that isn't necessary!
This comment was marked helpful 0 times.
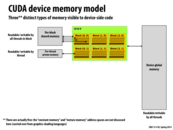
When I was struggling to grasp the concept of GPU memory in OpenCL, I looked in the deep pages of google search and found an interesting analogy to the real world. So I hope Kayvon doesn't kill me for this since it's not exactly CUDA, but here's the execution and memory model of OpenCL: A Day at School
Hope this helps!
This comment was marked helpful 3 times.

What is the relation between "texture memory" and what we see here? Is it a special subset of device global memory? Are there any hack-y things we can do with it, or is it just a different model for the same resources that we're already using?
This comment was marked helpful 0 times.

From looking it up, it appears texture memory has particularly good 2D spatial locality, so it could be handy in any application where that's particularly relevant: http://cuda-programming.blogspot.com/2013/02/texture-memory-in-cuda-what-is-texture.html
This comment was marked helpful 1 times.
cudaMemcpy only copies data from main memory to global memory. However, using shared memory in the block has a much better performance.
This comment was marked helpful 0 times.
Texture memory is backed by GPU DRAM, so yes, it's just a subset of global memory. However, in modern GPUs a texture read a special instruction services by a special fixed function processor with its own cache. (with caching policies specific to texture data access).
More detail on what a texture fetch actually does can be found in 15-869 slides here.
This comment was marked helpful 0 times.

Here, the lecture notes says CUDA will implicit synchronize all the threads, but in the homework description, it says "Note that CUDA kernel's execution on the GPU is asynchronous with the main application thread running on the CPU. Therefore, you will want to place a call to cudaThreadSynchronize following the kernel call to wait for completion of all CUDA work.", which means we need to do the synchronization ourselves.
I'm confused about this.
This comment was marked helpful 0 times.
Both statements are correct.
When a CUDA kernel is called, the kernel is not complete until all threads have terminated. You can think of each kernel launch as a command sent to the GPU. By default, the GPU will process these commands in order. That is, if your program launches K1 and then K2. All K1 threads will complete before any thread from K2 begins execution. Thus you can think of there being a barrier between the threads described by K1 and the threads described by K2.
CUDA however, says nothing about the order of kernel execution compared to execution of the main host thread. When the CUDA launch call returns, it does not mean the kernel is complete. If the main CPU thread wants to know the kernel is complete, cudaThreadSychronize can be used since cudaThreadSynchronize only returns when all prior kernel launches are complete.
This comment was marked helpful 0 times.
So to clarify, a CUDA kernel is the function that being called to run on a GPU. It is a non-blocking call from the CPU code so to check the result of our function call, we need to call cudaThreadSynchronize from our CPU code to synchronize and finish the work of all the thread blocks. This is in contrast to the __syncthreads function which is called within the GPU code in order to synchronize the threads within a single block.
This comment was marked helpful 1 times.
On the subject of synchronization constructs, some other atomic functions that help with synchronized access to memory are included as builtins in gcc. See the reference here. These are especially useful in assignment 3.
This comment was marked helpful 0 times.
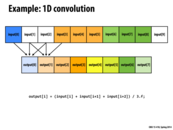


It seems like we could replace the loading phase with:
int start_idx = blockIdx.x * blockDim.x;
support[threadIdx.x] = input[start_idx + threadIdx.x];
if (threadIdx.x >= THREADS_PER_BLK - 2) {
support[THREADS_PER_BLK] = input[start_idx + THREADS_PER_BLK];
support[THREADS_PER_BLK + 1] = input[start_idx + THREADS_PER_BLK + 1];
This adds two extra loads from memory, but I think it makes the __syncthreads() call unneeded, since the two threads that depend on the last two values load them themselves before continuing. Is this true, and if so would making this change be worth it?
This comment was marked helpful 0 times.

The __syncthreads() call is necessary to ensure that the entire support array has been loaded before continuing. Without the synchronization, it is possible for a thread to reach the addition portion of the code without the other threads that it relies on (namely the threads with IDs threadIdx.x + 1 and threadIdx.x + 2) having finished the loading portion yet, and therefore, the addition would add undefined values. The __syncthreads() call removes the possibility of this race condition.
This comment was marked helpful 2 times.

This code is similar to the way ISPC is coded because the function convolve itself does not itself show any parallelism (other than the call to __syncthreads, which I will come to later). Instead, it is the sequential code for just one thread in one block. The parallelism is invoked in the call to convolve, with the CUDA parameters <<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>. This is similar to using launch in ISPC.
As for the call to __syncthreads, I don't recall ever seeing any barriers in ISPC programs. Are they also needed and we just didn't see any/I just don't remember it? Or is it that ISPC doesn't need them since it takes care of that stuff for you, and CUDA has a lower abstraction distance than ISPC?
This comment was marked helpful 0 times.
@jmnash I believe we didn't see barriers in ISPC programs because it was given that the gangs were independent.
This comment was marked helpful 0 times.

Assuming my understanding is correct, each instance in an ISPC gang is by definition synchronized, due to the semantics mentioned here
"ISPC guarantees that program instances synchronize after each program sequence point, which is roughly after each statement."
Hence barriers are unnecessary between instances of a gang. As for tasks, my guess is that barriers across ISPC tasks is altogether impossible, since tasks may be run one by one sequentially, and not interleaved.
This comment was marked helpful 0 times.

Why it loads data first into a block shared array? Why not directly calculate the result from the input array?
This comment was marked helpful 0 times.

@yetianx Good question! If you look ahead to slide 48, on-chip shared memory is much faster than global memory [reference]. In the 1D convolution example above, you will access each data elements three times per block (spatial locality). If you move the array to block shared memory, you can benefit from this locality such that you don't need to fetch each array element three times from global memory.
This comment was marked helpful 1 times.

The code only uses the x dimension of the thread and block indices. It seems to me that every row of blocks being utilized in this example would calculate the same thing, as would every row of threads in a block. Why don't we use the other (y) dimension here? Certainly using only x helps illustrate the example better, but is there a more profound reason?
This comment was marked helpful 0 times.
@tcz: This example is a 1D convolution. So there are not multiple rows.
The kernel launch creates N/THREADS_PER_BLOCK blocks, with THREADS_PER_BLOCK threads per block . Since I initialize the launch with 1D values blockDim.y is 0.
This comment was marked helpful 0 times.
Why can we initialize the devInput in the host code? I thought we couldn't touch the handles/pointers that we pass to the kernal functions. Otherwise why do we need to move data between the host and device address spaces like in slide 39?
This comment was marked helpful 0 times.
@LilWaynes: Your understanding is correct. The "properly initialize" comment referred to issuing the appropriate cudaMemcpy call to initialize the device array devInput.
This comment was marked helpful 0 times.



So at least to me, the device code is incredibly difficult to decipher. We start with some input array, and we make a shared array (so that other threads can pull from what the current thread is responsible for putting into the array) in order to copy over only exactly what we want. I believe that this would be faster since now the data is in per-block shared memory, rather than the device global memory (lecture 5, slide 40). After syncthreads, since the data is all in support, we can run the individual computation for each thread, and then put that result into output. The host code can then catch all the threads.
This comment was marked helpful 0 times.
A CUDA kernel function, like convole shown above, is a function that is executed in SPMD fashion by multiple CUDA threads. Together these threads are called a CUDA thread block, and one way threads in a block can communicate is by reading and writing values in per-block shared memory (support is a shared memory array in this example). Like an ISPC gang, all threads in a CUDA thread block are executed concurrently, although there are no guarantees of synchronization after each instruction as is the case in ISPC (also see the discussion here). Synchronizing threads in a CUDA thread block requires explicit use of a barrier. You see this in the call to __syncthreads in the middle of the convolve function.
If someone wants to really check their understanding, I'd like to hear your thoughts comparing the concepts of an ISPC gang, a CUDA thread block, and an NVIDIA GPU warp. I'd also like to hear your thoughts on an ISPC uniform values vs. CUDA per-block shared memory values.
This comment was marked helpful 0 times.

Let me check: a warp is analogous to an ISPC gang, since the threads in each warp are executed in SIMD lockstep by the 32 ALUs in a single core. A block is an abstraction to make it convenient for the programmer, containing a set of threads which may share data, and the hardware can break down a block into multiple warps so that they can be executed concurrently for latency hiding.
ISPC uniform values are analogous to CUDA per-block shared memory values. However, because instances in an ISPC gang are guaranteed to execute in lockstep (unlike threads in a CUDA block), race conditions can more easily occur when updating shared memory in CUDA, and the use of barriers can help prevent this.
This comment was marked helpful 0 times.
@benchoi @kayvonf are the threads in each warp necessarily executed in SIMD lockstep by the ALUs? I was under the impression that yes they are executed concurrently, but not necessarily in lockstep.
EDIT: Oops I misunderstood, nevermind!
This comment was marked helpful 0 times.

Can someone explain "SPMD fashion by multiple CUDA threads ".
This comment was marked helpful 0 times.
@shabnam: I guess you could draw an analogy between CUDA and ISPC to understand this phrase; in ISPC, we essentially ran a program on a set of data elements in parallel using program instances. This is essentially the notion of SPMD (single program, multiple data).
You can draw a similar picture with CUDA threads and kernels; when a kernel is launched, a bunch of CUDA threads are created; each CUDA thread executes a kernel function.
This comment was marked helpful 1 times.


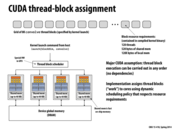

What exactly is this dynamic scheduling policy? And what does it even mean to "respect resource requirements"? Aren't all cores identical, so shouldn't it not matter which block we assign to which core?
This comment was marked helpful 0 times.

If you recall in ISPC, we identified multiple tasks that were data-parallel such that the OS could schedule the tasks to execution units at its leisure. However the OS had no knowledge before execution about how much time each task would take (if you recall there were some rows that took longer to calculate and some that took less time). If the OS assigned and even number of tasks to each processors before execution (static assignment), the different execution units might end up taking vastly different times to complete their tasks.
Therefore, the OS makes a queue of the different tasks. It initially distributes one task to each execution unit and only when that unit is done will another task be assigned to it. This is dynamic assignment because the OS is determining which processor individual tasks are run on during execution of the program.
For example, imagine there is are two processors, one can process one task per unit time and the other can perform 3 tasks per unit time. A static assignment solution to divide the tasks in half would mean the system would have to wait n/2 units of time to finish all the tasks (slowed down by the second processor). In dynamic assignment, the fast processor would request 3 tasks per unit time while the slow processor only would ask for 1 task. Thus 4 tasks per unit time will be completed and the execution time is n/4. Assigning 3:1 distribution of load is not intuitive before execution but actually looking at how the processor performs while running allows the OS to adapt to a different solution.
This comment was marked helpful 1 times.
For the second part, if I recall resource requirements for blocks are that all threads on a block must be run concurrently. Therefore, as much as a dynamic scheduler might want to split a block up, CUDA intrinsics about blocks prevent that assignment.
This comment was marked helpful 0 times.
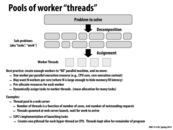

For the first and second points under 'Best practice', what is the difference? The first point indicates that the best practice is to have one worker per parallel execution resource, while the second says that we may want multiple workers per core, which is a parallel execution resource.
This comment was marked helpful 0 times.
@bstan: My understanding is as follows:
a) Each parallel execution resource should be used in some manner; it is a waste to write parallel code that can run on N cores, only for some of those N cores/execution contexts to be unused during the program's execution. This is a bare minimum requirement, applicable to any parallel program.
b) Additionally, depending on the program's context (memory accesses, IO handling), it may make sense to have additional workers on a single core, to hide the latency of those operations. This is a more specific requirement, which depends on the nature of the parallel program
This comment was marked helpful 0 times.
With reference to those 2 points, the 2nd claim doesn't quite seem to apply to CUDA as clearly. It seems like in the context of CUDA, a worker is a block of threads and we have that each block is assigned to a core/unit of parallel execution resource.
It doesn't seem to make much sense to assign more than 1 block of thread to a core since each block already has multiple threads to run concurrently to hide latency. Unless of course, each block of thread really only has 1 thread then it makes sense to have multiple blocks assigned to a core.
This comment was marked helpful 0 times.
@rokhinip: Your reasoning is great and shows good understanding of the key concepts in play. However, there is a good reason to run multiple thread blocks on a single core. (And it fact GPUs certainly do). Consider running one thread block on a core, and consider a problem that might occur if a program has __synchthreads in it. A similar problem might arise if all threads issue a memory request at the same time (like in the convolve example), or if some of the threads in a block terminate earlier than others.
This comment was marked helpful 0 times.
@kayvonf: Sorry this is late but based on what you're saying, it sounds like if the block as a whole stalls (perhaps due to a memory request although this latency should once again be small since the memory bandwidth on GPUs is so high) or if some threads in the block finish before others, having another block of threads assigned to the core would use the resources in the core rather than have them be idle.
This comment was marked helpful 0 times.

Question:
Does the blue SIMD load/store unit always take a warp context, since every warp needs to load and store data? Or is there a hidden context (and decoder) for only this purpose?
In the convolve program, we are explicitly loading the data first into the shared block memory and this shared memory is implemented by dividing the L1 cache on this picture, right? Doesn't the first read automatically loads the first line of data into the cache? Why do we need to explicitly load the data if we are already using a cache?
This comment was marked helpful 0 times.

If anybody is interested, the whitepaper on the GK104 (GTX 680/Kepler) chip goes into extensive detail of how the chip is structured, how warps are scheduled, what the memory bus/regions look like, and more.
This is the paper on the GK104:
http://www.geforce.com/Active/en_US/en_US/pdf/GeForce-GTX-680-Whitepaper-FINAL.pdf
The newer GK110 (GTX 780/Kepler) paper is not about the exact chip we are discussing, but goes into even more detail about how everything works (and describes some cool new features), and GK104 and GK110 are pretty similar.
http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf
Finally, if you're interested in history, the original Fermi (8800 GTX) whitepaper is pretty interesting. Fermi was the very first NVIDIA architecture that had a unified shader architecture, which allowed for complex programmable shaders (vertex, fragment, geometry, etc.) as well as CUDA.
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIAFermiComputeArchitectureWhitepaper.pdf
This comment was marked helpful 3 times.

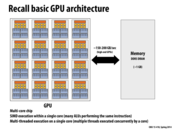
I'd like to try to summarize the architecture of this GPU:
- The GPU is composed of some number of cores (SMX units), with a shared cache.
- Each SMX unit has:
- A shared cache, which will be split into <= 16 thread block contexts (fewer if the 48K of shared memory isn't enough for 16 blocks).
- Space for up to 64 warp contexts, where a warp represents something that's running/trying to run on the core right now. There's 256K allocated for warp contexts, so if the contexts are to big it won't have space for 64.
- Four warp selectors, each of which can decode and send out <= 2 instructions from their warp's instruction stream at the same time.
- Six blocks of 32 general-purpose ALUs, and two blocks of special ALUs (one for math and one for loads/stores). These mean that the core supports 32-wide SIMD vector computation.
Putting this together, we can figure out the following:
- The SIMD width is 32, so each warp cannot represent more than 32 CUDA threads.
- CUDA specifies that all the threads of a block must be runnable on a single core, so a single block can't be split into more than 64 warps, or 2048 threads.
- A maximum of 2048 threads per core means the chip can support at most 16384 threads at once.
This is all my best guess, so if I got it wrong please let me know :)
This comment was marked helpful 2 times.
@mchoquet: Solid start. I believe everything is correct except:
"At most four warps can be running at once, so a single block can't have more than 4 * 32 = 128 threads in it"
"A shared cache, which may or may not be split into <= 16 thread block contexts (some clarification on the splitting would be appreciated)."
Take a look at my long post on slide 52, then try and make an update to your post, and then you'll have it down.
This comment was marked helpful 0 times.
Is there a reason the FLOPS value is twice 8x192x1Ghz ~ 1.5TFLOPS?
This comment was marked helpful 0 times.
@kkz: multiply-add is considered two floating point operations. It's 1.5 tera-madds = 3 TFLOPS.
This comment was marked helpful 0 times.
@kayvonf ohhh ok, didn't know that haha
This comment was marked helpful 0 times.

How exactly does this scheduling process work? Is this implemented with only hardware support? Is it correct to think about this as putting a pile of paper on the table and each person just takes the next piece when they are done(as in the experiment on the first day of class)?
This comment was marked helpful 0 times.

I am confused about warps. To my understanding, warps are groups of CUDA threads where each warp has a number of CUDA threads equal to the number of vector width (correct me if I'm wrong). But what determines how many warps are possible? There are 4 warp selectors in this architecture, so why is the maximum number of warp contexts 64?
This comment was marked helpful 0 times.
CUDA thread blocks are assigned to groups of <= 4 warps based on the size of the thread block (warps have a max size of 32 because the SIMD width is 32), and up to 4 warps are running at any given time. Up to 64 saved warp contexts can exist at once to ensure that the GPU is always busy, even if the current warps have to do slow memory operations. See here and here.
-- EDIT --
My bad, CUDA thread blocks can actually be split into as many as 64 warps at once. The idea is that a block should all be able to run on the same chip, and chips have space for 64 warp contexts.
This comment was marked helpful 0 times.
The reason for 64 warps (2048 threads) in one core is that it needs to hide latency, remember in lecture 2, slide 47, we hide stalls for multithreading. In here, the situation is similar, but we use warps here, so if one warp wait for memory access, other warps could use the resources.
This comment was marked helpful 3 times.

I have a couple of questions about how all of this works.
- The point of a warp context is to utilize all SIMD lanes by running a single execution from each CUDA thread on a single lane, right? (max 32 threads per warp because 32 simd lanes)
- Does a warp context have a fixed size? If not, then the 64 warp contexts per core is a generalization?
- What happens if the shared memory for a single block is very large such that when a core attempts to handle multiple blocks, the shared memory does not fit into the L1 cache. It says that shared memory is allocated on L1 at launch. Is a GPU smart enough to only process the single block (and associated threads) whos data it can store in the L1? Or will something else happen, like interleave processing of another block, and so L1 cache memory will be exchanged for the new block?
This comment was marked helpful 0 times.

I'm trying to understand the relation between blocks, warps, and cores. Can someone colloquially explain how these three things are related?
My understanding is that each core is broken up into warps and each warp contains a certain number of blocks, but I don't understand why we break down into each of these parts or what they're used for exactly.
This comment was marked helpful 0 times.
Warp typically has size 32, and it is executed in lockstep on cores. When you do not consider about performance, you can ignore warp because it is implementation detail, and you can not control warp in CUDA. Programmers would control how each block and thread behave, that is abstraction. Warp is execution(implementation) detail. Cores(SM or SMX in Nvidia term) would execute instructions, and blocks are mapped into cores. You can not say each warp contains blocks.
This comment was marked helpful 0 times.
@yanzhan, technically the concept of a warp is exposed in CUDA. For example, CUDA has builtin "warp vote" instructions and warp shuffle instructions (see Appendix B.13 and B.14 of the CUDA Programmer's Guide version ) that allow the WARP implementation details to bleed into the CUDA language itself. However, other than these intra-warp communication primitives -- which did not exist in the original version of CUDA and were only added subsequently since they were easily supported in hardware and useful to programmers wanting to program GPUs for maximum performance --- in general it is usually perfectly fine to reason about a CUDA program without thinking about it's implementation on an NVIDIA GPU using warps.
This comment was marked helpful 0 times.
An NVIDIA GPU executes 32 CUDA threads together in SIMD lockstep. That is, each of these 32 CUDA threads share an instruction stream. This is an NVIDIA GPU implementation detail and NVIDIA calls these 32 threads that share an instruction stream a WARP. (However, since it is common for CUDA programming make assumptions about the warp size, at this point it would be very hard for NVIDIA to change the warp size without forcing many CUDA applications to be rewritten.).
In practice, 32-consecutive threads in a block are mapped to the same warp. Therefore, a CUDA thread block with 128 threads, such as the convolve example introduced on slide 43 will be executed using four GPU warps. One warp will execute CUDA threads 0-31, another warp will execute threads 32-64 in the block, and so on. The 256-thread block introduced in the modified convolve program in slide 56 will be executed using eight warps.
It is very reasonable to think of a warp as "an execution context". When executing a warp, the GPU will fetch and decode the next instruction needed by the warp and then execute it on 32 SIMD execution units to carry out that instruction in parallel for the 32 CUDA threads mapping to the warp.
The Kepler GPU shown in the figure has support for up to 64 warp execution contexts. Since 32 threads map to a warp, that's support for up to 64*32 = 2048 CUDA threads. However, there are two reasons why the GPU core may run less than 64 warps at once.
- Notice the core has a total of 256 KB of storage for the local registers for these warps. So 256KB / 2048 = 128 bytes (32, 32-bit values) of register space per CUDA thread. If a CUDA program required more than 128 bytes of register space (as determined during compilation), the chip will only be able to run a smaller number of warps at once. So larger register footprint means fewer active warps. Fewer active warps means less concurrency, and therefore less latency hiding is possible using interleaving of warp execution.
- The second reason the core may run less than 64 warps of work at once is if there is insufficient shared memory. Each CUDA thread block may require it's own allocation of shared memory. For example, recall that the 128-thread
convolvethread block required 130 floats of shared memory, or 130x4 = 520 bytes. In this case, the block does not require much storage and thus shared memory does not limit the total number of blocks that can fit on the core. However, if a CUDA program does require a lot of per-block storage, that resource requirement can limit the total number of blocks that can run on the core at once. For example, if the shared memory allocation requirements for theconvolveprogram were sufficiently large that only two blocks could be run on the core at once, then only 2 x 128 = 256 threads (4 warps) could be active on the core at once.
Does that make sense?
This comment was marked helpful 4 times.

Now I have a clear understanding about the warps and threads. But I'm still thinking about the relation between blocks and threads. The maximum number of threads per block in CUDA is 128. Is this number arbitrary or has something to do with the hardware implementation? For example, memory on a chip.
This comment was marked helpful 0 times.
@squidrice Maximum number of threads per block in cuda is 512. It is limited by the size for context store (warp execution contexts on the above slide) on each gpu core.
This comment was marked helpful 0 times.
Also, from my understanding, a block of threads is partitioned into up to 64 warps. Since each warp is executed in SIMD lockstep, we are ensured synchronization amongst them. Therefore, __syncthreads is really used to synchronize across the various warps used to execute the CUDA threads?
This comment was marked helpful 0 times.
@everyone. Clearing up some confusion... The maximum number of threads per block depends on the CUDA compute capability. That number is 1024 for compute capability 2.0 or higher, which includes the GPUs in the lab.
Since a warp consists of 32 CUDA threads, a thread block's execution may be carried out by at most 32 warps.
@rokhinip is correct in point out that __synchthreads is a mechanism to synchronize threads in a block, across warps.
Please see http://en.wikipedia.org/wiki/CUDA for a nice table.
This comment was marked helpful 0 times.
Sorry I am a little confused by this part of clarification:
"Since a warp consists of 32 CUDA threads, a thread block's execution may be carried out by at most 32 warps."
So this is saying that, since each block has at most 1024 threads, and threads in a CUDA thread will always be in the same block (and that it will be stupid to take only, say, 14 threads out of a block that has at least 32 threads left to execute). So they can be carried out by at most 1024/32 that is 32 warps. Am I understanding this correctly?
Also a separate question, does the assignment of warp persist until all the computations are done in the thread? I want to say yes but I am a little unsure. Thanks!!! :D
This comment was marked helpful 0 times.
@Yuyang:
1) I would say yes, although @kayvonf could clarify further.
2) I believe so; the threads in a warp cannot move onto a different set of data until all the threads have completed. This makes sense as the warp structure provides a SIMD model of execution. The threads in a single warp block execute in SIMD style; they cannot progress until they have all finished executing the same set of instructions.
This comment was marked helpful 0 times.


I'm a little confused by the calculation on 'how many of what do we have'.
does each block(abstraction) correspond to a warp(implementation)? Or does one block correspond to multiple warps if we have more than 32 thread in one block?
Since we can only run 6*32 threads at the same time on one core (limited by the number of SIMDs), why do we ever need 64 warps each with 32 threads?
Also, why are there 8 Fetch/Decoder units? Does each one of them serve one warp?
I feel like there's a certain degree of hardware modularity that separates the number of threads, the number of decoders, warps etc. can someone explain how these work together please.
This comment was marked helpful 0 times.
See my attempted explanation here for my thoughts about how blocks/warps work.
As for (2): the point of having more warps is (I think) so that we can ensure something is always running. If a warp is currently stalled waiting to read/write to memory, then at least 1/4 of the chip's computation power won't be used until it's done. Having other warps ready to step in and do some work until the first warp returns from it's slow operation means that more work gets done overall. See here for the relevant slide.
(3). My understanding is that two fetchers serve each of the 4 warps that are currently running. This way all four warps can have 2-way ILP at the same time.
This comment was marked helpful 0 times.

So in lecture we pointed out that blocks are independent, whereas threads might need to communicate (as with a __syncThreads() call). Why exactly did we point that out? I know it led to some sort of deadlock situation, but I'm not quite sure how. It may have involved having too many warps trying to run, or having one warp execute threads from multiple blocks?
This comment was marked helpful 0 times.
The professor made the assumption that for now each block contains 256 threads, but in one time we can execute 4 warps = 128 threads at one time. So the question is, should we finished the 128 threads and then for the next 128 threads left? The answer is not, because it cannot be finished, as 256 threads in one block needs to reach the syncthreads, which is not possible if we want to finish 128 first.
Besides, I believe warps are from the same block.
This comment was marked helpful 0 times.
So if my understanding is correct, warps are an implementation detail on (most/some/all?) GPUs, but there is nothing in CUDA about them. That is, are CUDA code may be very inefficient in that it is not parallel, i.e. unable to execute the same instruction on multiple (up to 32) different data streams. This is different from using ISPC and vector intrinsics, where all the performance gain is from taking advantage of multiple ALUs. In CUDA, the focus seems to be on gaining performance from using multiple cores (although there are also many ALUs per core). This makes sense as GPUs have many more cores than CPUs, so this is the main source of parallelism. Is that correct?
This comment was marked helpful 0 times.
@sbly: in many situations, the warp concept IS essentially just an implementation detail, and this was essentially the case when CUDA first came out. But technically, the concept of a warp is exposed in modern incarnations of the CUDA programming model. Take a look at my comment on slide 52 about how the warp-based execution (largely an implementation decision) bleeds into the modern CUDA programming model.
This comment was marked helpful 0 times.
@kayvonf Do we suffer any inefficiencies when are blocksize is not a multiple of 32? I'm assuming each warp cannot serve more than one block (it wouldn't make much sense otherwise).
This comment was marked helpful 0 times.
@kkz: Yes. There would be one warp that was only "partially full" with active threads. This is a case of execution divergence, since some lanes of the warp would essentially always be masked off.
This comment was marked helpful 0 times.

So from the discussions I can understand that a warp can support 32 threads because of SIMD. These 32 threads must have their own stacks, from what I understand from previous slides, and I'm assuming they are in the warp. I can see that each warp can hold about 256kb, so does that mean each thread gets about 8kb worth of stack memory? Correct me if I'm wrong.
This comment was marked helpful 0 times.

So from what I understand now, a CUDA thread is executed on one SIMD lane. A warp supports 32 CUDA threads. Does that mean the SIMD unit is 32-wide for this specific GPU?
This comment was marked helpful 0 times.
@yihuaz: Yes.
This comment was marked helpful 0 times.


All threads of the same warp execute the program in parallel. If threads of the same warp execute a data-dependent control flow instruction, control flow might diverge and the different execution paths are executed sequentially. Once all paths complete execution, all threads are executed in parallel again.
This comment was marked helpful 0 times.

So CUDA is an abstraction, while WARP is the implementation. To my knowledge, a good abstraction should hide all the details below, and just provide an interface for its users. But in this case, if I make the block size 256 and use synchronization in each block, it will produce dependency and lead to deadlock, right? So if I am writing CUDA codes, I have to know about the hardware details, otherwise I might come up with some unexpected results. In this sense, is CUDA a bad abstraction?
This comment was marked helpful 0 times.
@tianyih. This slide concerns details of implementation. It says that IF a CUDA implementation was not able to run all threads in a thread block concurrently, then certain valid CUDA programs could in fact deadlock. Clearly this is not good, and so a correct CUDA implementation must be able to run all threads in a thread block concurrently.
As a CUDA programmer you do not need to worry about the implementation details of GPU scheduling to ensure your program is correct (unless you write CUDA code in a very specific way that violates the spirit of the independent blocks abstraction, as discussed here). The program shown on this slide is a valid CUDA program, and any chip that claims to be a CUDA implementation will run it correctly. Otherwise, you'd throw it out and buy a new one!
Summary: this slide is only pointing how CUDA's abstractions constrain what implementations are possible. The proposed implementation is not a correct one!
This comment was marked helpful 0 times.

I have a question about the "Threads in thread-block are concurrent". So if a CUDA thread block spans over 4 warps, and we distribute work unevenly to these CUDA threads, will some warps have to wait for the other warps?
This comment was marked helpful 0 times.

I believe so, yes. What i gather from the discussion on earlier slides is that threads in a warp run like the instances of an ISPC gang, completing at the same time. However, the same cannot be assumed about multiple warps. I think what the statement means is that threads in a block are assumed to be independent.
This comment was marked helpful 0 times.

Threads in a warp are executed in SPMD style (which is why we write one CUDA kernel per block, not per thread). So the only real source of load imbalance would be conditionals (we discussed this from an ISPC perspective here: http://15418.courses.cs.cmu.edu/spring2014/lecture/basicarch/slide_028). So threads in a warp can't really finish before other threads, but the same issues from ISPC SIMD apply here.
This comment was marked helpful 0 times.

The main point from the comments above is that threads in a warp will all finish at the same time, similar to the instances of an ISPC gang. This could lead to worse performance than expected due to conditional execution. A thread block is similar to a ISPC gang, because in both their threads/instances run concurrently. This does not imply anything about multiple warps finishing at the same time.
This comment was marked helpful 0 times.
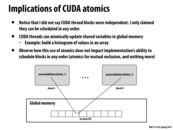

A few questions:
What exactly is the difference between blocks being independent and being scheduled in any order? Does independence imply some strong condition about the state of the threads which isn't true in the implementation of CUDA?
How can one ensure atomicity in memory updates among different cores? If you have two cores each running different CUDA blocks that want to update the same region of shared memory, what kind of communication has to happen to avoid race conditions?
This comment was marked helpful 0 times.
@wcrichto
If you take a look at the CUDA Toolkit Documentation - Thread Hierarchy it implies that because thread blocks are required to execute independently they can be scheduled in any order. Independence refers to control/data dependency; a block cannot rely on the results of another block in order to operate independently.
There is no one simple way to synchronize across all blocks. The best I could come up with was to launch a kernel, cudaThreadSynchronize() and launch another kernel. You could also check out some of the atomic operations in the Toolkit Documentation and perhaps use it to implement a mutex or semaphore. I have not looked too much into it but a host of __threadfence() operations also support memory ordering of sorts.
This comment was marked helpful 0 times.

The program on this slide may cause dead lock, but the one on previous slide would not. The reason is that the global variable may change the control on this slide, while the blocks on the previous one are relatively independent to the value of global memory. Though the previous program is safe from dead lock, the value of the global variable is not reliable, if the change is not atomic.
This comment was marked helpful 0 times.

How are the CUDA atomics implemented? I have 2 ideas that I think I've heard, one is that on a low level the hardware makes sure that the atomic operation occurs in a single clock cycle, and the second idea is of course the use of a mutex. Also, I don't understand the point of atomic operations in terms of only ensuring the integrity of a small set of operations (addition, subtraction, etc.). Why not just put a lock around the operation instead of having to call the CUDA atomics?
This comment was marked helpful 0 times.
Notice that atomic operations (like: atomicAdd, compare_and_swap, test_and_set) synchronize a sequence of loads/stores to a single address. Operations on different addresses can occur independently. To get similar functionality using a mutex, you'd need one mutex per address.
Consider building a histogram in parallel, where threads atomically increment bin counts: e.g., bins[i]++. Imagine if there are thousands of bins. If you wanted the same fine grained synchronization ability, you'd need a mutex per bin.
Processors provide atomic instructions. Mutex implementations are then built using these atomic primitives. We'll talk about how to build higher level synchronization out of atomic operations in a later lecture.
This comment was marked helpful 0 times.

The program in the previous slide will not deadlock since the blocks are not dependent on each other.
In this program, the blocks are dependent on each other. Specifically, we see that block N depends on block 0 having executed first. The problem with this is that it is possible for block N to be scheduled before block 0. If our GPU has a single core, then block N will spin forever, since block 0 will never get scheduled.
This comment was marked helpful 0 times.

I'm a bit confused about how this code works. As I see it, the "startingIndex" can be as high as (N-1) while the main loop is running. This means that "index" can be as high as (N-1) + (127) = N+126, but isn't this out of bounds?
This comment was marked helpful 0 times.

@kkz: I think this code makes the assumption that N is a multiple of 128.
This comment was marked helpful 0 times.
Yeah, it does. It would have become pretty messy if I put a boundary condition for that in there.
This comment was marked helpful 0 times.

If CUDA was created to allow general computation on the GPU, why are the semantics block based and not more similar to the semantics employed by this program? It seems like the abstraction level is slightly contrived. You could potentially have multiple blocks on the same core, right? This seems weird.
This comment was marked helpful 0 times.

A number of good parallel programming courses around the country are taught in CUDA. You may wish to watch the lectures (or even do assignments) from:
This comment was marked helpful 0 times.