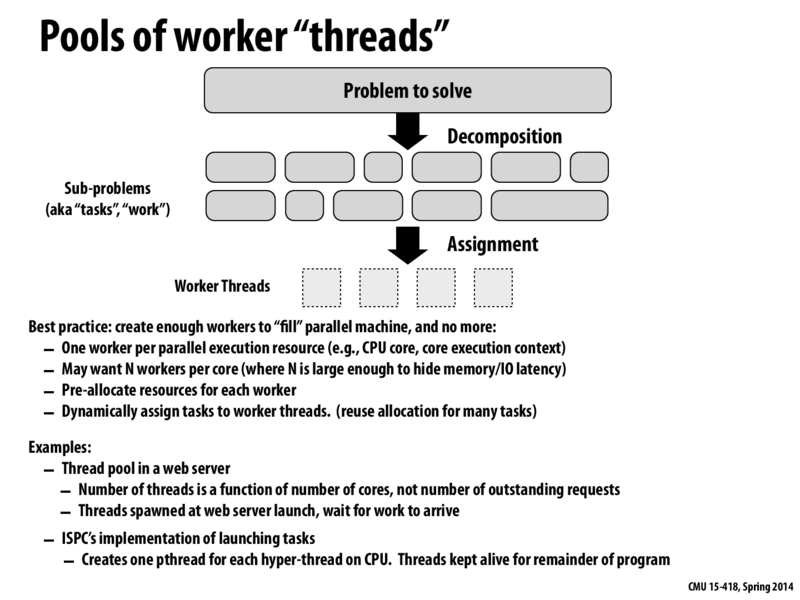
For the first and second points under 'Best practice', what is the difference? The first point indicates that the best practice is to have one worker per parallel execution resource, while the second says that we may want multiple workers per core, which is a parallel execution resource.
This comment was marked helpful 0 times.
arjunh
@bstan: My understanding is as follows:
a) Each parallel execution resource should be used in some manner; it is a waste to write parallel code that can run on N cores, only for some of those N cores/execution contexts to be unused during the program's execution. This is a bare minimum requirement, applicable to any parallel program.
b) Additionally, depending on the program's context (memory accesses, IO handling), it may make sense to have additional workers on a single core, to hide the latency of those operations. This is a more specific requirement, which depends on the nature of the parallel program
This comment was marked helpful 0 times.
rokhinip
With reference to those 2 points, the 2nd claim doesn't quite seem to apply to CUDA as clearly. It seems like in the context of CUDA, a worker is a block of threads and we have that each block is assigned to a core/unit of parallel execution resource.
It doesn't seem to make much sense to assign more than 1 block of thread to a core since each block already has multiple threads to run concurrently to hide latency. Unless of course, each block of thread really only has 1 thread then it makes sense to have multiple blocks assigned to a core.
This comment was marked helpful 0 times.
kayvonf
@rokhinip: Your reasoning is great and shows good understanding of the key concepts in play. However, there is a good reason to run multiple thread blocks on a single core. (And it fact GPUs certainly do). Consider running one thread block on a core, and consider a problem that might occur if a program has __synchthreads in it. A similar problem might arise if all threads issue a memory request at the same time (like in the convolve example), or if some of the threads in a block terminate earlier than others.
This comment was marked helpful 0 times.
rokhinip
@kayvonf: Sorry this is late but based on what you're saying, it sounds like if the block as a whole stalls (perhaps due to a memory request although this latency should once again be small since the memory bandwidth on GPUs is so high) or if some threads in the block finish before others, having another block of threads assigned to the core would use the resources in the core rather than have them be idle.
For the first and second points under 'Best practice', what is the difference? The first point indicates that the best practice is to have one worker per parallel execution resource, while the second says that we may want multiple workers per core, which is a parallel execution resource.
This comment was marked helpful 0 times.
@bstan: My understanding is as follows:
a) Each parallel execution resource should be used in some manner; it is a waste to write parallel code that can run on N cores, only for some of those N cores/execution contexts to be unused during the program's execution. This is a bare minimum requirement, applicable to any parallel program.
b) Additionally, depending on the program's context (memory accesses, IO handling), it may make sense to have additional workers on a single core, to hide the latency of those operations. This is a more specific requirement, which depends on the nature of the parallel program
This comment was marked helpful 0 times.
With reference to those 2 points, the 2nd claim doesn't quite seem to apply to CUDA as clearly. It seems like in the context of CUDA, a worker is a block of threads and we have that each block is assigned to a core/unit of parallel execution resource.
It doesn't seem to make much sense to assign more than 1 block of thread to a core since each block already has multiple threads to run concurrently to hide latency. Unless of course, each block of thread really only has 1 thread then it makes sense to have multiple blocks assigned to a core.
This comment was marked helpful 0 times.
@rokhinip: Your reasoning is great and shows good understanding of the key concepts in play. However, there is a good reason to run multiple thread blocks on a single core. (And it fact GPUs certainly do). Consider running one thread block on a core, and consider a problem that might occur if a program has
__synchthreadsin it. A similar problem might arise if all threads issue a memory request at the same time (like in the convolve example), or if some of the threads in a block terminate earlier than others.This comment was marked helpful 0 times.
@kayvonf: Sorry this is late but based on what you're saying, it sounds like if the block as a whole stalls (perhaps due to a memory request although this latency should once again be small since the memory bandwidth on GPUs is so high) or if some threads in the block finish before others, having another block of threads assigned to the core would use the resources in the core rather than have them be idle.
This comment was marked helpful 0 times.