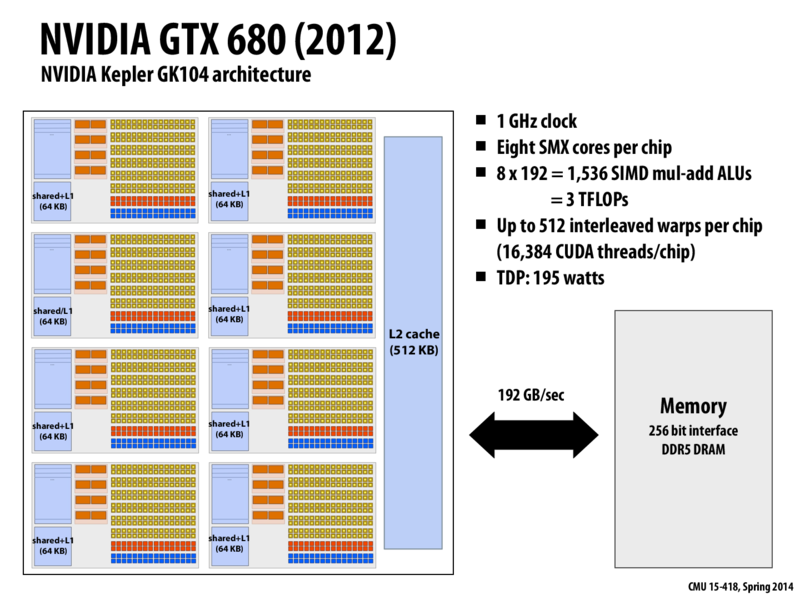
I'd like to try to summarize the architecture of this GPU:
The GPU is composed of some number of cores (SMX units), with a shared cache.
Each SMX unit has:
A shared cache, which will be split into <= 16 thread block contexts (fewer if the 48K of shared memory isn't enough for 16 blocks).
Space for up to 64 warp contexts, where a warp represents something that's running/trying to run on the core right now. There's 256K allocated for warp contexts, so if the contexts are to big it won't have space for 64.
Four warp selectors, each of which can decode and send out <= 2 instructions from their warp's instruction stream at the same time.
Six blocks of 32 general-purpose ALUs, and two blocks of special ALUs (one for math and one for loads/stores). These mean that the core supports 32-wide SIMD vector computation.
Putting this together, we can figure out the following:
The SIMD width is 32, so each warp cannot represent more than 32 CUDA threads.
CUDA specifies that all the threads of a block must be runnable on a single core, so a single block can't be split into more than 64 warps, or 2048 threads.
A maximum of 2048 threads per core means the chip can support at most 16384 threads at once.
This is all my best guess, so if I got it wrong please let me know :)
This comment was marked helpful 2 times.
kayvonf
@mchoquet: Solid start. I believe everything is correct except:
"At most four warps can be running at once, so a single block can't have more than 4 * 32 = 128 threads in it"
"A shared cache, which may or may not be split into <= 16 thread block contexts (some clarification on the splitting would be appreciated)."
Take a look at my long post on slide 52, then try and make an update to your post, and then you'll have it down.
This comment was marked helpful 0 times.
kkz
Is there a reason the FLOPS value is twice 8x192x1Ghz ~ 1.5TFLOPS?
This comment was marked helpful 0 times.
kayvonf
@kkz: multiply-add is considered two floating point operations. It's 1.5 tera-madds = 3 TFLOPS.
I'd like to try to summarize the architecture of this GPU:
Putting this together, we can figure out the following:
This is all my best guess, so if I got it wrong please let me know :)
This comment was marked helpful 2 times.
@mchoquet: Solid start. I believe everything is correct except:
"At most four warps can be running at once, so a single block can't have more than 4 * 32 = 128 threads in it"
"A shared cache, which may or may not be split into <= 16 thread block contexts (some clarification on the splitting would be appreciated)."
Take a look at my long post on slide 52, then try and make an update to your post, and then you'll have it down.
This comment was marked helpful 0 times.
Is there a reason the FLOPS value is twice 8x192x1Ghz ~ 1.5TFLOPS?
This comment was marked helpful 0 times.
@kkz: multiply-add is considered two floating point operations. It's 1.5 tera-madds = 3 TFLOPS.
This comment was marked helpful 0 times.
@kayvonf ohhh ok, didn't know that haha
This comment was marked helpful 0 times.