Here, sharding is used on a directed graph. This method can be adapted to an undirected graph by creating a directed graph where every edge goes both ways. You only need to read a single shard then to obtain all information about the vertices in that shard. This method of course comes at the expense of space since every undirected edge has to be stored as two directed edges. Is there a more efficient representation for streaming undirected graphs?
This comment was marked helpful 0 times.
uhkiv
Here, the point of this data structure is to maximize disk utility when performing operations that only require a vertex's local neighborhood. Since the entire graph cannot fit in memory and random disk access is VERY expensive, we want to organize the graph into these intervals, so disk access pattern is more predictable (contiguous).
One other interesting thing is how this approach compares in terms of performance and complexity of that of using distributed systems. Sure, failure tolerance and consistency is a pain in the ass for the developer who writes the framework, but the end user won't feel much difference (since using DS underneath a language like Ligra would actually be a reasonable implementation, I think). Also, as we saw with web servers, hitting disk is worse then hitting network and accessing a in-memory cache. Anyone else have an opinion?
This comment was marked helpful 0 times.
bwasti
@uhkiv, I agree a DS approach is likely better suited for this type of computation. It seems like the problem is almost entirely memory bound, which network latencies can easily trump disk latencies on. But as was stated in an earlier slide, the motivation behind this approach was because clustering machines is difficult/expensive.
This comment was marked helpful 0 times.
benchoi
Are there cases where the structure of the graph leads to sharding with very uneven shard sizes, diminishing the benefits of this technique?
This comment was marked helpful 0 times.
vrkrishn
Well from this article, it discusses how finding an ideal distribution of a graph onto many different memory banks is a difficult task and how different distributions of the same data can vastly change the communication overhead of computations on the graph:
Is it possible to sort edges by value (or some key in general)? Does sort by source vertex id have other impacts? One thing I can think of is that destination vertices can be loaded faster but that does not seem to apply to sparse graph.
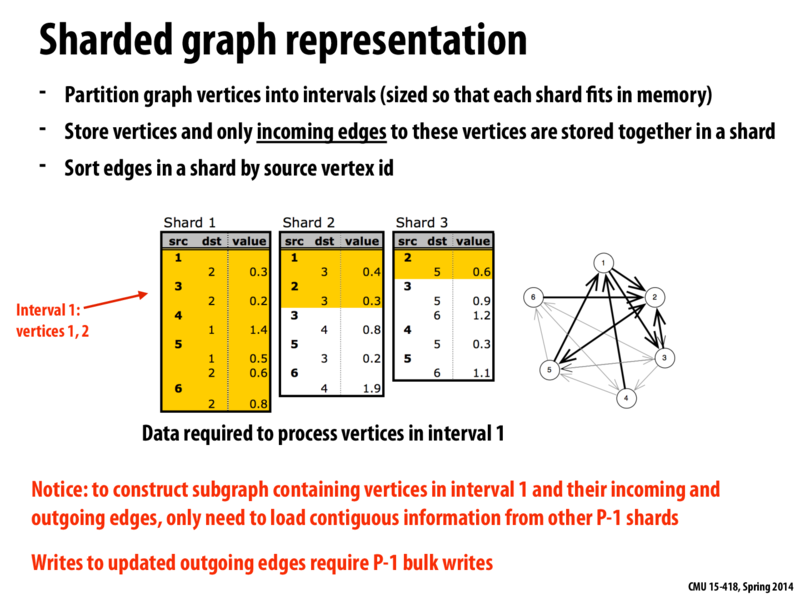
Here, sharding is used on a directed graph. This method can be adapted to an undirected graph by creating a directed graph where every edge goes both ways. You only need to read a single shard then to obtain all information about the vertices in that shard. This method of course comes at the expense of space since every undirected edge has to be stored as two directed edges. Is there a more efficient representation for streaming undirected graphs?
This comment was marked helpful 0 times.
Here, the point of this data structure is to maximize disk utility when performing operations that only require a vertex's local neighborhood. Since the entire graph cannot fit in memory and random disk access is VERY expensive, we want to organize the graph into these intervals, so disk access pattern is more predictable (contiguous).
One other interesting thing is how this approach compares in terms of performance and complexity of that of using distributed systems. Sure, failure tolerance and consistency is a pain in the ass for the developer who writes the framework, but the end user won't feel much difference (since using DS underneath a language like Ligra would actually be a reasonable implementation, I think). Also, as we saw with web servers, hitting disk is worse then hitting network and accessing a in-memory cache. Anyone else have an opinion?
This comment was marked helpful 0 times.
@uhkiv, I agree a DS approach is likely better suited for this type of computation. It seems like the problem is almost entirely memory bound, which network latencies can easily trump disk latencies on. But as was stated in an earlier slide, the motivation behind this approach was because clustering machines is difficult/expensive.
This comment was marked helpful 0 times.
Are there cases where the structure of the graph leads to sharding with very uneven shard sizes, diminishing the benefits of this technique?
This comment was marked helpful 0 times.
Well from this article, it discusses how finding an ideal distribution of a graph onto many different memory banks is a difficult task and how different distributions of the same data can vastly change the communication overhead of computations on the graph:
http://jim.webber.name/2011/02/on-sharding-graph-databases/
This comment was marked helpful 0 times.
Is it possible to sort edges by value (or some key in general)? Does sort by source vertex id have other impacts? One thing I can think of is that destination vertices can be loaded faster but that does not seem to apply to sparse graph.
This comment was marked helpful 0 times.