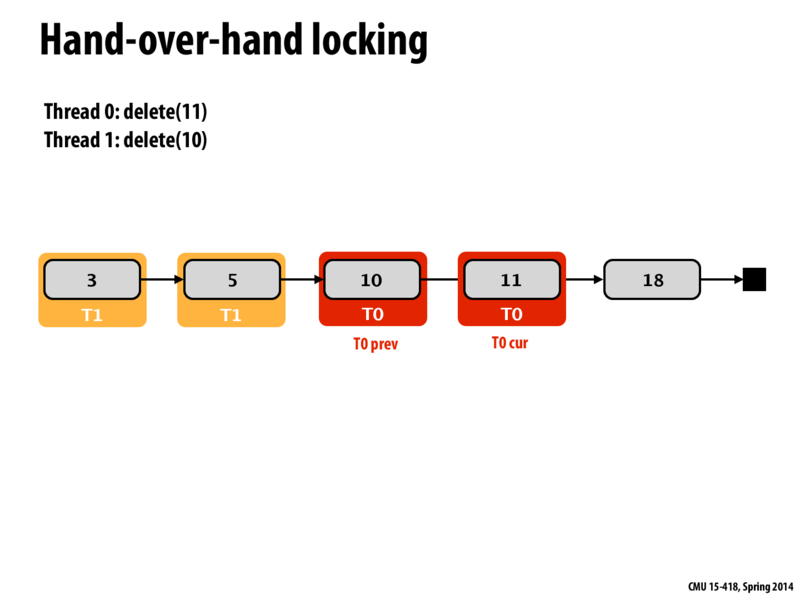
Right after this point, I get the feeling that starvation could happen for T1. Since T1 has acquired all the locks it needs except for node 10, it will wait for node 10. However, it may be possible for another thread to quickly snatch the lock of that node once T0 is done with deleting 11. If for example, the linked list was being cleared from the end, then T1 may starve.
This has been posted in a later slide, but the reason why this implementation shouldn't ever deadlock is that the processes make sure to take the initial lock before trying to take the next one. In this way, no processor will have the lock that another is trying to acquire (because then they would have tried to acquire the previous lock first). In this case, T0 makes sure it has the lock of 10, and there is no way that T1 can have the lock of 11 (which is what T0 needs) without first having lock 10. In this case, deadlock is avoided.
This comment was marked helpful 0 times.
eatnow
I was wondering why we only need 2 locks, then realized that the list is singly linked. I believe that if it is a doubly linked list then we need 3 locks for each deletion.
This comment was marked helpful 0 times.
aew
I agree, as mentioned on slide 12, we would need 3 locks when deleting. Locks for the current, previous, and next node would be needed so that the previous and next nodes aren't deleted during the deletion of the current node.
This comment was marked helpful 0 times.
mofarrel
@pwei
Here starvation cannot occur. Every call to insert, or delete must traverse the singly linked list in order to find the position it wants to modify. This is equivalent to saying that each thread is working from the left to the right in this diagram. This means that when T0 is done deleting 11, T1 is the only thread that will be able to access 10, because all the other threads working on the list, are stuck earlier on in the list (behind T1's locks).
This comment was marked helpful 0 times.
kayvonf
@aew: not quite. You actually only need two. See my comments on the previous and next slides.
In short, a thread T doesn't need a lock on the node after the node to be deleted (let's call it NEXT) because it's certain NEXT cannot be deleted since another thread would require a lock on the to-be-deleted node, which T currently has in order to delete NEXT.
This comment was marked helpful 0 times.
rokhinip
@kayvonf, if this is the case, can't we do insertion with 1 lock?
Suppose I have the lock for 5, I know that the node right after 5 (in this case - 10), is not going to change due to the reasons you cite on the next slide. So if I need to insert 7, I can do so since I'm holding the lock for 5.
I feel like this is true for a doubly linked list too, I should be able to work with just a single lock on the node.
This comment was marked helpful 1 times.
kayvonf
@rokhinip: Let's see. In the case of insertion, it's true that if you have a lock on 5, 10 can't disappear from a delete (since delete always holds PREV and CUR), so you don't have to lock 10 to insert after 5. Note that another thread deleting the node after 10 might actually have a lock on 10 at this point, but that doesn't matter.
But you do have to hand over hand lock as you iterate down the list. So you go from holding one lock, to holding two, to holding one, etc. just as before. Your comment points out one more improvement that in the insert code on slide 8. Instead of locking NEXT, you can check to see if NEXT.value is greater than the value to insert without actually locking NEXT. This seems correct. Someone can verify.
This comment was marked helpful 0 times.
rokhinip
I see. So I can't just do the whole thing with at most 1 lock since I'll need to release said lock at some point, thereby holding no locks at all, and some other thread can come in and change the state.
More specifically, the following could happen with just 1 lock if I'm trying to insert 7 into the above list:
Let curr = ptr to 3
t1 grabs curr->lock.
Checks to see if 5 = curr->next->value > value_to_insert = 7 without acquiring curr->next's lock.
Fails the check so it sets prev = curr and curr = curr->next (so curr now is a pointer to 5)
t1 releases prev->lock (so 3 is now unlocked)
Before t1 can grab curr->lock, the following happens:
t2 grabs prev->lock and curr->lock (So t2 has lock to 3 and 5)
t2 can now delete node 5
t2 releases locks to prev and curr (3 and 5)
t1 resumes and tries to grab lock for curr (Node with 5) but it has been deleted. We segfault.
This comment was marked helpful 1 times.
spilledmilk
With @rokhinip's suggestion, the amount of time that insert holds on to two locks as opposed to one would be greatly reduced. For most of the body of the while loop, only 1 lock would be required. However, at the end, hand-over-hand locking would still be required to ensure that it always has at least 1 lock. I believe it would represent a significant improvement over the current code though.
The improved version of the function would look like:
void insert(List* list, int value) {
Node* n = new Node;
n-> value = value;
Node* prev, *cur;
lock(list->lock);
prev = list->heard;
cur = list->head->next;
lock(prev->lock);
unlock(list->lock);
while (cur) {
if (cur->value > value)
break;
Node* old_prev = prev;
prev = cur;
cur = cur->next;
lock(prev->lock);
unlock(old_prev->lock);
}
prev->next = n;
n->next = cur;
unlock(prev->lock);
}
This comment was marked helpful 1 times.
shabnam
@rokhinip The final problem you describe with using just 1 lock is absolutely correct.
Right after this point, I get the feeling that starvation could happen for T1. Since T1 has acquired all the locks it needs except for node 10, it will wait for node 10. However, it may be possible for another thread to quickly snatch the lock of that node once T0 is done with deleting 11. If for example, the linked list was being cleared from the end, then T1 may starve. This has been posted in a later slide, but the reason why this implementation shouldn't ever deadlock is that the processes make sure to take the initial lock before trying to take the next one. In this way, no processor will have the lock that another is trying to acquire (because then they would have tried to acquire the previous lock first). In this case, T0 makes sure it has the lock of 10, and there is no way that T1 can have the lock of 11 (which is what T0 needs) without first having lock 10. In this case, deadlock is avoided.
This comment was marked helpful 0 times.
I was wondering why we only need 2 locks, then realized that the list is singly linked. I believe that if it is a doubly linked list then we need 3 locks for each deletion.
This comment was marked helpful 0 times.
I agree, as mentioned on slide 12, we would need 3 locks when deleting. Locks for the current, previous, and next node would be needed so that the previous and next nodes aren't deleted during the deletion of the current node.
This comment was marked helpful 0 times.
@pwei Here starvation cannot occur. Every call to insert, or delete must traverse the singly linked list in order to find the position it wants to modify. This is equivalent to saying that each thread is working from the left to the right in this diagram. This means that when T0 is done deleting 11, T1 is the only thread that will be able to access 10, because all the other threads working on the list, are stuck earlier on in the list (behind T1's locks).
This comment was marked helpful 0 times.
@aew: not quite. You actually only need two. See my comments on the previous and next slides.
In short, a thread T doesn't need a lock on the node after the node to be deleted (let's call it NEXT) because it's certain NEXT cannot be deleted since another thread would require a lock on the to-be-deleted node, which T currently has in order to delete NEXT.
This comment was marked helpful 0 times.
@kayvonf, if this is the case, can't we do insertion with 1 lock?
Suppose I have the lock for 5, I know that the node right after 5 (in this case - 10), is not going to change due to the reasons you cite on the next slide. So if I need to insert 7, I can do so since I'm holding the lock for 5.
I feel like this is true for a doubly linked list too, I should be able to work with just a single lock on the node.
This comment was marked helpful 1 times.
@rokhinip: Let's see. In the case of insertion, it's true that if you have a lock on 5, 10 can't disappear from a delete (since delete always holds PREV and CUR), so you don't have to lock 10 to insert after 5. Note that another thread deleting the node after 10 might actually have a lock on 10 at this point, but that doesn't matter.
But you do have to hand over hand lock as you iterate down the list. So you go from holding one lock, to holding two, to holding one, etc. just as before. Your comment points out one more improvement that in the
insertcode on slide 8. Instead of locking NEXT, you can check to see if NEXT.value is greater than the value to insert without actually locking NEXT. This seems correct. Someone can verify.This comment was marked helpful 0 times.
I see. So I can't just do the whole thing with at most 1 lock since I'll need to release said lock at some point, thereby holding no locks at all, and some other thread can come in and change the state.
More specifically, the following could happen with just 1 lock if I'm trying to insert 7 into the above list:
Let curr = ptr to 3
Before t1 can grab curr->lock, the following happens:
t1 resumes and tries to grab lock for curr (Node with 5) but it has been deleted. We segfault.
This comment was marked helpful 1 times.
With @rokhinip's suggestion, the amount of time that
insertholds on to two locks as opposed to one would be greatly reduced. For most of the body of the while loop, only 1 lock would be required. However, at the end, hand-over-hand locking would still be required to ensure that it always has at least 1 lock. I believe it would represent a significant improvement over the current code though.The improved version of the function would look like:
This comment was marked helpful 1 times.
@rokhinip The final problem you describe with using just 1 lock is absolutely correct.
This comment was marked helpful 0 times.