


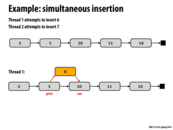
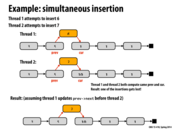

It helped me in lecture and I think it might help clarify here, Node 6 still exists, and is pointing to Node 10, it just doesn't have 5 pointing to it, so can't ever be found.
This comment was marked helpful 4 times.

Another situation, as mentioned in the lecture, is simultaneous deletion. An example, considering a linked list of 3->5->10->11->18, is when deleting 5 and 10 simultaneously. 10 will get deleted and 5 will point to 10. It will cause the loss of the entire linked list, except the head.
This comment was marked helpful 0 times.

@cwswanso totally agree with you. That helped me too!
This comment was marked helpful 0 times.


A quick optimization that can be had here is to move the "unlock(list->lock);" above "delete cur;" in delete(), so that it looks like this:
if (cur->value == value) {
prev->next = cur->next;
unlock(list->lock);
delete cur;
return;
}
since delete is implemented using malloc's free(), it could be that free() takes a long time, so it would be worth it to allow other linked-list deletes to occur while free() is occuring. Also, if malloc is multithreaded, this allows us to take advantage of that.
This comment was marked helpful 0 times.

@Q_Q: I think your optimization breaks exclusivity and sometimes it will release the lock before deleting, leading to a corrupted linked list.
This comment was marked helpful 0 times.

@yetianx I don't think so. By the time delete cur is called, the node pointed by cur is no longer in the list. So it's safe to release the lock before calling delete. Of course, we have to assume that delete is correctly implemented to handle concurrent execution by multiple threads (but that seems like a pretty safe assumption to make).
This comment was marked helpful 1 times.

In certain cases when not too many threads are competing for resources, using a global lock data structure is faster than using a fine-grained lock data structure because a fine-grained lock data structure has more overhead.
This comment was marked helpful 0 times.




Having one lock while traversing (for a short period of time), seems to be alright.
In the case where you are traversing the list and have not found a goal node, you will be able to release the prev node because you definitely do not care about it. You are guaranteed not to care about the previous nodes and how they are modified because the earliest node you could care about is the single node you have a lock for.
goal node: d
operation: delete
->(a)->(b)->(c)->(d)->(e)->
->(a)->(b*)->(c)->(d)->(e)-> [we don't care about a because we haven't found d]
->(a)->(b)->(c)->(d)->(e)->
->(a)->(b)->(c*)->(d)->(e)-> [we don't care about b, guaranteed]
->(a)->(b)->(c)->(d)->(e)-> [d was found]
->(a)->(b)->(c*)->(e)-> [d deleted]
->(a)->(b)->(c)->(e)-> [release c]
goal node: d
operation: insert before d
->(a)->(b)->(c)->(d)->(e)->
->(a)->(b*)->(c)->(d)->(e)->
->(a)->(b)->(c)->(d)->(e)->
->(a)->(b)->(c*)->(d)->(e)-> [we don't care about b, guaranteed]
->(a)->(b)->(c)->(d)->(e)-> [d was found]
->(a)->(b)->(c)->(i)->(d)->(e)-> [i inserted before d]
->(a)->(b)->(c)->(i)->(d)->(e)-> [release c,d]
I think these demonstrate that as you hold at least one lock you are guaranteeing that no other threads pass your lock. Holding one lock at a time implies that you are still searching for the goal node and thus do not care about the previous node.
This comment was marked helpful 2 times.

It seems to me that, in the release-prev-then-lock-next order of lock/unlock, you should maintain three invariants:
- You are not interested in any nodes before the "cur" node (ie, the first node in the list that you have locked). I believe this implies that whatever changes happen before cur, you don't care about.
- No otter threads can "leapfrog" you in their traversal, because they need you to unlock cur before they can lock/access it.
- The earlier of the two nodes you have locked will not be deleted, so the "following" thread will never have a pointer to a to-be-deleted node.
As a result, if you are the "leading" thread, you do not care about modifications to the list you've already seen. If you are the "following" thread, you cannot grab a node until it is done being modified. So it seems that having a single lock may not be a problem.
It looks like this code implements the 3 lock-2 lock-3 lock style of traversal, as illustrated in the following slides.
Since you're deleting cur, you may even be able to get away without the line
unlock(cur->lock);
in the delete while loop.
EDIT: Comment race condition, sorry @bwasti.
This comment was marked helpful 0 times.

One performance problem inherent in this implementation is that if one thread is updating something near the beginning of the list, other threads won't be able to get past it to update something completely different at the end.
Perhaps when a node is locked, an additional pointer can be put on the first locked node to allow other threads to "skip past" the locked region? This additional pointer would also carry information about the value of the first node past the locked region so threads know whether they should skip, or wait for the region to be unlocked because they also need to work with it.
This comment was marked helpful 0 times.

I believe the potential problem that could arise from having pointers that allow skipping past locked nodes is that when updating a node in the list, you would also have to also update all of the extra pointers that point to it, which could call for even more locks and overshadow any performance gains from the skip pointers.
This comment was marked helpful 0 times.

After class it was determined that everyone else was correct, and I was not. It is sufficient to release the lock for old_prev prior to acquiring the lock for cur.
The code presented in lecture was correct code, but it was conservative about what lock needed to be held. I've updated the code above to release the lock for old_prev then acquire the lock for cur as the above discussion begun by @bwasti suggests. Good job everyone.
Side note: Last year I presented the never-hold-more-than-two-locks at a time algorithm as discussed above, but this year when preparing for lecture I thought I determined a case where it could lead to a race, and so I changed it to more conservative variant. Dumb professors.
You may also want to see the discussion on slide 10, where we're continuing the optimize this code even further.
This comment was marked helpful 0 times.

Note that simply eliminating the prev->lock code from the above would produce multiple problems.
1 - 2 - 3 - 4 - 5
T1: delete 3 T2: delete 3
T1 acquires L3 (lock 3). T2, sitting at cur = 2, sets cur = cur->next, so cur = 3. T2 acquires L2.
T1 sets 2 -> 4, unlocks L3.
Here, we have two bad scenarios: 1. T1 deletes L3. T2 then attempts to read L3 which is now unallocated, segfault. 2. T2 gets the lock on L3, then T1 deletes L3. Now T2 attempts to read node 3, segfault.
This comment was marked helpful 0 times.

Is there a good way to ensure that you aren't missing a race condition? Or is the only way to be absolutely sure brute-force checking the states of all threads when they are attempting to modify the same data. It seems very easy to show that something does have a race condition, but not to be completely certain that it doesn't have race conditions when working with fine grain locks.
This comment was marked helpful 0 times.
Not really. Some tools do try to find race conditions, but none of them can work all of the time.
This comment was marked helpful 0 times.

Can somebody explain why we need a list lock here? I do not see why lock the head and the next of head needs to be in lock step.
This comment was marked helpful 1 times.

@yanzhan2 I think it's because we need to assign the prev pointer to the start of the list (list->head). If the node is to be inserted at the head of the list, then you need to make sure that only one thread had the previous head of the list.
Otherwise, you could have two threads trying to insert to the front of the list at the same time; they may then both store the original head of the list. When one thread completes its insertion, the other thread won't recognize the changed head.
Could you clarify where you intend to place the lock? My understanding is that when you lock a node, you can't go past the node, but you can still assign a pointer to that node.
This comment was marked helpful 0 times.
@yanzhan2, to give a simple example, consider the list A → B.
- P1 does
prev = list->head = A - P2 does
delete(A -> B, A) - P1 does
cur = list->head->next
The third step segfaults, as A has been deleted.
This comment was marked helpful 0 times.
@wcrichto,A has been deleted? P2 delete A or B?
This comment was marked helpful 0 times.

@yanzhan2 I believe that is what Will is saying here. P2 deletes A from the list (and the list is just A -> B), so when P1 does cur = list->head->next, the head of the list (A) has been deleted, so there is no next, and a segfault occurs.
This comment was marked helpful 0 times.
@arjunh, but the existence of list->lock cannot prevent two threads from starting from the same old head.
@wcrichto, the comment said "assume the case of delete head handled here". So I guess deleting the head should not be handled here.
This comment was marked helpful 0 times.
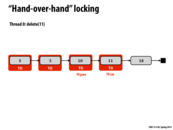
Note: This is a meaningless slide to see in it's final build form. An animation was shown in class.
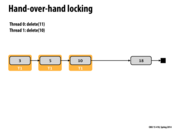
The hand-over-hand locking procedure:
- Starts with 3 and 5 locked.
- Releases 3, takes 10
- Releases 5 takes 11
- Now with 10 and 11 locked, the deletion of 11 can occur.
This comment was marked helpful 0 times.

Hand-over-hand locking means that we can't unlock(node) until we lock(node->next). To see why this is needed, suppose we unlock(5) prior to lock(10). There is now a point at which 5 and 10 are both free, which enables someone else to successfully delete(10), before we are able to traverse the list and delete 11.
This comment was marked helpful 0 times.
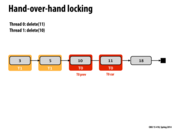

Right after this point, I get the feeling that starvation could happen for T1. Since T1 has acquired all the locks it needs except for node 10, it will wait for node 10. However, it may be possible for another thread to quickly snatch the lock of that node once T0 is done with deleting 11. If for example, the linked list was being cleared from the end, then T1 may starve. This has been posted in a later slide, but the reason why this implementation shouldn't ever deadlock is that the processes make sure to take the initial lock before trying to take the next one. In this way, no processor will have the lock that another is trying to acquire (because then they would have tried to acquire the previous lock first). In this case, T0 makes sure it has the lock of 10, and there is no way that T1 can have the lock of 11 (which is what T0 needs) without first having lock 10. In this case, deadlock is avoided.
This comment was marked helpful 0 times.

I was wondering why we only need 2 locks, then realized that the list is singly linked. I believe that if it is a doubly linked list then we need 3 locks for each deletion.
This comment was marked helpful 0 times.

I agree, as mentioned on slide 12, we would need 3 locks when deleting. Locks for the current, previous, and next node would be needed so that the previous and next nodes aren't deleted during the deletion of the current node.
This comment was marked helpful 0 times.

@pwei Here starvation cannot occur. Every call to insert, or delete must traverse the singly linked list in order to find the position it wants to modify. This is equivalent to saying that each thread is working from the left to the right in this diagram. This means that when T0 is done deleting 11, T1 is the only thread that will be able to access 10, because all the other threads working on the list, are stuck earlier on in the list (behind T1's locks).
This comment was marked helpful 0 times.
@aew: not quite. You actually only need two. See my comments on the previous and next slides.
In short, a thread T doesn't need a lock on the node after the node to be deleted (let's call it NEXT) because it's certain NEXT cannot be deleted since another thread would require a lock on the to-be-deleted node, which T currently has in order to delete NEXT.
This comment was marked helpful 0 times.

@kayvonf, if this is the case, can't we do insertion with 1 lock?
Suppose I have the lock for 5, I know that the node right after 5 (in this case - 10), is not going to change due to the reasons you cite on the next slide. So if I need to insert 7, I can do so since I'm holding the lock for 5.
I feel like this is true for a doubly linked list too, I should be able to work with just a single lock on the node.
This comment was marked helpful 1 times.
@rokhinip: Let's see. In the case of insertion, it's true that if you have a lock on 5, 10 can't disappear from a delete (since delete always holds PREV and CUR), so you don't have to lock 10 to insert after 5. Note that another thread deleting the node after 10 might actually have a lock on 10 at this point, but that doesn't matter.
But you do have to hand over hand lock as you iterate down the list. So you go from holding one lock, to holding two, to holding one, etc. just as before. Your comment points out one more improvement that in the insert code on slide 8. Instead of locking NEXT, you can check to see if NEXT.value is greater than the value to insert without actually locking NEXT. This seems correct. Someone can verify.
This comment was marked helpful 0 times.
I see. So I can't just do the whole thing with at most 1 lock since I'll need to release said lock at some point, thereby holding no locks at all, and some other thread can come in and change the state.
More specifically, the following could happen with just 1 lock if I'm trying to insert 7 into the above list:
Let curr = ptr to 3
- t1 grabs curr->lock.
- Checks to see if 5 = curr->next->value > value_to_insert = 7 without acquiring curr->next's lock.
- Fails the check so it sets prev = curr and curr = curr->next (so curr now is a pointer to 5)
- t1 releases prev->lock (so 3 is now unlocked)
Before t1 can grab curr->lock, the following happens:
- t2 grabs prev->lock and curr->lock (So t2 has lock to 3 and 5)
- t2 can now delete node 5
- t2 releases locks to prev and curr (3 and 5)
t1 resumes and tries to grab lock for curr (Node with 5) but it has been deleted. We segfault.
This comment was marked helpful 1 times.
With @rokhinip's suggestion, the amount of time that insert holds on to two locks as opposed to one would be greatly reduced. For most of the body of the while loop, only 1 lock would be required. However, at the end, hand-over-hand locking would still be required to ensure that it always has at least 1 lock. I believe it would represent a significant improvement over the current code though.
The improved version of the function would look like:
void insert(List* list, int value) {
Node* n = new Node;
n-> value = value;
Node* prev, *cur;
lock(list->lock);
prev = list->heard;
cur = list->head->next;
lock(prev->lock);
unlock(list->lock);
while (cur) {
if (cur->value > value)
break;
Node* old_prev = prev;
prev = cur;
cur = cur->next;
lock(prev->lock);
unlock(old_prev->lock);
}
prev->next = n;
n->next = cur;
unlock(prev->lock);
}
This comment was marked helpful 1 times.
@rokhinip The final problem you describe with using just 1 lock is absolutely correct.
This comment was marked helpful 0 times.
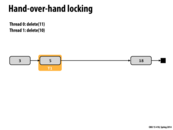
There shouldn't be a need for T1 to hold onto all 3 locks here right? It should be able to let go of the lock for 3 and then grab 10. This is cause we have the lock for 5 and so we know that 10 could not be deleted by any other thread.
This comment was marked helpful 0 times.
To delete 10 you need locks for 5 (prevNode) and 10 (curNode).
If you have the lock for 10, you know:
- No other thread can insert after 10, since inserting requires a previous pointer.
- No other thread can be deleting 18, since deleting requires a previous pointer.
This comment was marked helpful 1 times.

The key necessity of hand-over-hand locking is that you must have the locks for everything you are modifying. For a singly-linked list, this means having the lock for the node whose data you are modifying and the lock for the node before it whose pointer you are modifying. For a doubly-linked list the locks for the nodes before AND after whose pointers' you are modifying are both required.
This comment was marked helpful 0 times.

To build on what @asinha said, the reason for this is that if you do not have a lock on something you might be editing, then another thread might come up and cause problems. For instance, when considering the doubly linked list, if you just have a lock on the curr and next nodes, then another thread can delete the prev node while you were trying to set prev->next = next. It is clear to see how this can cause problems. Therefore, when editing anything, you need a lock on anything that can be affected.
This comment was marked helpful 0 times.
While it is correct to have locks on all the nodes whose data you're modifying, it may not be necessary. As Kayvon describes in the previous slide, if you have a lock for a node, you know that no one will insert after it and no one will be able to delete it or the next node. Therefore, as it maybe even be possible to get away with inserting with 1 lock and deleting with 2 on both singly-linked and doubly-linked lists, as @rokhinip describes.
This comment was marked helpful 0 times.
@spilledmilk: I was actually wrong in my hypothesis and we do need 2 locks for insertion.
This comment was marked helpful 0 times.


The previous linked-list code is deadlock free because threads only wait for locks in one direction. A later thread could never exceed a previous thread on the linked-list. Notice that the first thread never needs to wait for locks and it could end eventually. Then the second thread becomes the first one. By induction, all threads operating on the linked-list must end at sometime. Thus, the linked-list is deadlock-free.
This comment was marked helpful 0 times.

It was mentioned in class that we can find a middle-ground by choosing to lock at a larger granularity. But I have a hard time imagining how this would apply on the linked list problem. How might we lock on a granularity in between the hand-over-hand and locking the entire list range?
This comment was marked helpful 0 times.
@ruoyul you could have a lock for, say, every other node. Then locking any one node implicitly locks the node in front of it as well. So you might have to exclude four nodes to do a single delete, but overall you're taking less locks when traversing the list.
This comment was marked helpful 0 times.

@wchricto's solution seems like a good one to me, but extra care would have to be taken to ensure that the lock granularity remains consistent in the face of insertions and removals from the list. This would be annoying, but doesn't seem impossible to me. Can anyone think of a scheme that reduces the number of locks, but is simpler to manage? The best thing I can think of is to have $k$ locks and assign each node a number from 1 to $k$ based on whatever lock is least-used at the time of its insertion. This has a downside over the earlier answer in that a lock's nodes are spread around the list, so operations nowhere near each other can still interfere.
This comment was marked helpful 0 times.

Can someone explain to me what fine-grained locking is exactly?
I understand how it works with the linked list but i was hoping for some sort of general terminology in regards to fine-grained locking.
This comment was marked helpful 0 times.

@elemental03 The "naive" coarse-grained way to handle locking for a data structure is to just put one lock around the entire structure. For many data structures, though, there are sets of operations that can run in parallel on different parts of the structure without issue. Fine-grained locking is when we individually lock smaller subcomponents of the data structure, allowing operations that won't interfere with each other to be done on it in parallel.
This comment was marked helpful 1 times.


I didn't have time to implement delete, but I think this solution works for just insert operations.
typedef struct Tree
{
Node* root;
} Tree;
typedef struct Node
{
int value;
Node* left;
Node* right;
int lock;
} Node;
void insert(Tree* tree, int value)
{
lock(tree->root->lock);
insert_r(tree->root);
}
void insert_r(Node* node, int value)
{
if (value == node->value) return;
if (value < node->value)
{
lock(node->left->lock);
if (node->left == NULL)
{
Node* n = malloc(sizeof(Node));
n->left = NULL;
n->right = NULL;
n->value = value;
node->left = n;
unlock(node->left->lock);
unlock(node->lock);
}
else
{
unlock(node->lock);
insert(node->left, value);
}
}
else if (value > node->value)
{
lock(node->right->lock);
if (node->right == NULL)
{
Node* n = malloc(sizeof(Node));
n->left = NULL;
n->right = NULL;
n->value = value;
node-right = n;
unlock(node->right->lock);
unlock(node->lock);
}
else
{
unlock(node->lock);
insert(node->right, value);
}
}
}
I think the recursive structure of the code makes locks easier to handle. In particular, there are less pointers to deal with. Of course this code could be completely wrong, so let me know!
This comment was marked helpful 0 times.

don't you need unlock for if (value ==node->value) case ?
This comment was marked helpful 0 times.
@sbly The check for if (node->left == NULL) should happen before lock(node->left->lock). Otherwise the code might segfault. I also think you meant to call insert_r instead of insert, otherwise things don't typecheck. Here's a possible delete implementation, using the structs as defined by sbly.
void delete(Tree *tree, int value) {
// assume tree->root->value != value, don't want to handle that case
lock(tree->root->lock);
delete_r(tree->root, value);
}
void delete_r(Node *parent, int value) {
/* lock on parent is held on entry, so we're guaranteed that
* there won't be any modifications to parent->left and
* parent->right
*/
Node *next;
next = value < parent->value ? parent->left : parent->right;
if (next == NULL) {
unlock(parent->lock);
return;
}
if (next->value == value) {
Node *new_child = delete_self(next);
if (next == parent->left) {
parent->left = new_child;
} else {
parent->right = new_child;
}
unlock(parent->lock);
return;
}
lock(next->lock);
unlock(parent->lock);
delete_r(next, value);
}
I imagine that delete_self deletes the given node, returning NULL or returning the new head of that subtree. This is done by returning the right-most child in the left subtree or the left-most child in the right subtree. This traversal also needs to happen by locking each node, similar to how the linked list traversal was implemented.
This comment was marked helpful 0 times.

@sbly I believe the implementation is right, although if it is a C program, I think one problem happens when calling:
else
{
unlock(node->lock);
insert(node->left, value);
}function insert passes a pointer to Node, whereas according to definition
void insert(Tree* tree, int value)
{
lock(tree->root->lock);
insert_r(tree->root);
}It seems requires a pointer to Tree.
This comment was marked helpful 0 times.

I think the deletion case is not as simple...Because we need to reshuffle the tree, we need to always hold on to the parent's lock as well.
This comment was marked helpful 0 times.
The implementation provided by @sbly is incorrect. If my tree is the node containing value 1 and I call insert(T, 1) then I will lock the root node but never release it.
This comment was marked helpful 0 times.

On a strong memory consistency model processor, this bounded queue (also a circular buffer) doesn't need any sort of locking because the producer never modifies head and the consumer never modifies tail. They do read each other's variables, but this is okay because tail and head only ever increment. Since the purpose of reading the other party's variable is to prevent getting ahead of the other party, reading a stale value which has not been incremented yet is safe, because reading a stale value will not cause either party to overrun the other one.
This comment was marked helpful 0 times.

What is the use of the reclaim pointer? Is it just to maintain a pointer to deleted elements so that they can be deleted later?
This comment was marked helpful 0 times.

Note that in pop the node with the popped value isn't deleted. The head pointer is just moved up one. The reclaim pointer is there so that push can then clean up the unneeded nodes. Both allocation of nodes as well as deallocation of nodes are performed in the same thread (pop) so that we don't have to worry about having to make a thread safe version of alloc and free.
This comment was marked helpful 0 times.

To further clarify what LilWaynesFather is saying, when we push to the queue, we have to allocate memory for the Node structure that contains the new data, and when we pop from the queue, we then would have to (eventually) free that structure. The act of freeing structures we can separate from the act of popping structures, which we do in the above code by using the reclaim pointer.
According to the man page for malloc, there are mutexes that help avoid corruption in memory management, so if we were to use malloc/free, we wouldn't have to worry about it being thread safe, but I imagine a single thread handling all of the allocations and deallocations would reduce the amount of contention over the mutexes. As a programmer, I imagine it would also make it easier to track our allocations and deallocations and thus reduce the number of memory leaks :)
This comment was marked helpful 0 times.
The above comments focus on keeping allocation/free in the same thread, but you also observe that in this implementation, only the pushing thread touches tail and reclaim, and only the popping thread touches head. As a result, just like in the bounded queue case on the previous slide, the code need not synchronize accesses to these variables.
This comment was marked helpful 0 times.

The reason to use a reclaim pointer is we want the insertion and deletion of node in one thread. If we do not use reclaim, then thread-safe memory allocation is needed. If we delete node in pop operation, then head would possibly delete the node which the tail is pointing to, while it is inserting another node, then it would cause problem.
This comment was marked helpful 1 times.
Can this be explained further. Why do we need thread safe memory allocation.
This comment was marked helpful 0 times.

I believe we need to have thread safe memory allocation so that we are able to allocate and free memory concurrently, which would possibly happen when both the reader and writer try to pop and push (respectively) at the same time.
This comment was marked helpful 0 times.

What problems would develop from trying to allocate and free memory concurrently? The best instincts I have for the issues that would develop is that, if a piece of memory starts to be freed, and that location is marked as free, and then another thread begins to allocate that memory while it is still being freed, then some of that memory could continue to be freed. However, that seems like it would be trivial to avoid. I'm not sure what other issues would be present, at least that also wouldn't be easy to avoid.
This comment was marked helpful 0 times.

We need thread safe memory allocation also to avoid two threads trying to allocate one memory block at the same time.
This comment was marked helpful 0 times.

One solution to this could be lease the lock instead of giving the lock to a thread. If the thread dies holding the lock, it will expire in time and then it can be used by other threads. This is often used in distributed settings with a master node that grants leases to locks. If a thread wants to use a lock after its expired, it simply try to lease that lock again.
This comment was marked helpful 0 times.

The issue with leasing is that you need a centralized master in charge of handling leases and determining when they end, or otherwise have each system independently keep track of time (and then you run into issues like clock drift).
This comment was marked helpful 0 times.

Another possibility to resolve could be simply sending the failure message and make other thread work on the same job, though this would increase the throughput significantly. Renting lock does seem more efficient, but if it was the case where threads don't usually die, just a simple solution might work as well.
This comment was marked helpful 0 times.
@woojoonk I think you mean decrease the throughput.
This comment was marked helpful 0 times.

I know we say that any one thread is allowed to starve, I'm just wondering if this is ever actually a problem in practice? Based on the later graphs, I don't think it would be, but I'm not sure
This comment was marked helpful 0 times.

@cwswanso I think it may be an issue in systems where one thread is slower than the others, or perhaps in distributed systems. A very hypothetical case:
- Let's say that we have two nodes; A and B, in a distributed system
- Each node has two+ cores, and is running two+ threads concurrently
- All the threads are trying to access a resource in node A (in a fashion similar to the following slides, where if something has changed, you try again)
Then the threads in node A would be able to get/modify the shared resource a lot faster than threads in node B (because of communication latency) which could cause threads in node B to starve if there's no machanism to implement any order/fairness
This comment was marked helpful 0 times.

Why is it only that any one thread is allowed to starve? Why is the case with all threads starving except one that makes progress not allowed by this definition?
This comment was marked helpful 0 times.

@cardiff I think you may be misunderstanding the wording (or I may be misunderstanding you). This definition says that at least one thread is guaranteed to make progress. And thus, this means every other thread might possibly be starved.
This comment was marked helpful 0 times.
@cardiff What this is saying is that there exists at least one thread that will make progress, but that this is not necessarily any particular thread. Therefore, any given thread might be starved, although all threads will never simultaneously be starved.
This comment was marked helpful 0 times.
Oh, so based on these responses, I would interpret the line as follows: There must be at least one thread allowed to make progress at any given time, but it doesn't have to consistently be the same thread. Thus, if you pick one thread to examine, no matter which one you pick, it could be allowed to starve at some point by this definition.
This comment was marked helpful 0 times.
@cardiff Yep, sounds correct!
This comment was marked helpful 0 times.


A lock-free stack is speculative: we assume that we're able to change the stack, and right before we actually "commit" the change, we check if another thread has modified the stack. If another thread has, then we "fail", and try again (which is why we have the while(1) loop). Since the "commit" operation is an atomic compare_and_swap, we ensure we won't run into race conditions. This differs from a stack with locks because some thread is always capable of making progress (modifying the stack).
However, the implementation on this slide is actually incorrect (due to the ABA problem), which we can see on the next slide.
This comment was marked helpful 0 times.

This lock-free implementation of stack is different from using a spin lock to push and pop elements. This is because if we had used a spinlock, the thread holding a spinlock could end up blocking other threads needing to push and pop in scenarios such as when it gets a page fault. Whereas in this case even if this happens other threads can still execute their compare and swap operation and the thread that got a page fault, comes back and fails its compare and swap and tries again.
This comment was marked helpful 1 times.
@tomshen, In a way, your comment reminds me of how transactional memory works in an optimistic manner. We assume we can make the change and before we commit to it, we make another check in TM and it is analogous to the CAS here.
This comment was marked helpful 1 times.
Note this works because compare_and_swap is atomic meaning no other thread can sneak in between the check of "whether other thread was modified by other thread" and actually committing the new change, therefore no race condition!
This comment was marked helpful 0 times.
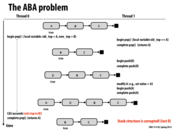
Here when thread 0 is about to do the initial pop, its local values of old_top is A and new-top is B. Suppose lets say at this point just before popping, it got swapped out and thread 1 starts executing. Thread 1 further goes on to pop A and then Push D and push the A back again. Now lets say thread 0 is context switched again. Now from thread 0's view the old_top is still A and hence the compare and swap passes. This leads to B replacing A and hence we effectively end up losing D all together.
p.s. Important thing to note is do not consider A, B, C as values but rather the address location of these nodes.
This comment was marked helpful 0 times.

Yes, it's important to remember the assumption that A and B are both addresses. It means when Thread 1 pushed A back into stack, Thread 0 though it's still the same node. Counter of number of pop is one solution of this situation. But I think in most cases, programmers prefer to pass a new copy of the value or object into stack, rather than the reference. So, I think's this situation won't happen much, hopefully!
This comment was marked helpful 0 times.

Why would the fact that they're passing values rather than references solve the problem? It seems like we could still have lots of problems, for instance both threads get A when they call pop in parallel, whereas your program would probably want one thread to get A and one thread to get the next element in the stack. I also don't think the problem referred to in the slides is fixed by passing values, only the problem where A could get a different value passed to it.
This comment was marked helpful 0 times.
A helpful story that illustrates the ABA problem (in real life!) can be found on Wikipedia!
This comment was marked helpful 2 times.

I think the main reason why ABA problem occurs is that we only get a promise "the head isn't changed", which doesn't ensure anything happens beyond the scope. But a lock on the list ensures no concurrent operation will be performed while some process is holding it.
This comment was marked helpful 0 times.


According to http://en.wikipedia.org/wiki/ABA_problem, another solution to the ABA problem is having a "tagged state reference" in the low bits of a pointer to keep track of number of edits to that pointer. The page also mentions that the technique still suffers from the wraparound problem. Apparently it's used in transactional memory as well!
This comment was marked helpful 0 times.

The push here does not need a counter to avoid the ABA problem. Because it will not always add an item to the top. Even that top has been deleted and then added again, as long as it is the top, we are fine.
This comment was marked helpful 1 times.


Using 4 bytes for a pointer and 4 bytes for two shorts, it seems like it would be possible to use cmpxchg8b for a "Triple compare and swap" on x86 (the same idea extends to x86-64 systems). Do complex lock-free data structures make use of this ability? Or is there a reason to avoid doing so?
This comment was marked helpful 1 times.
Honestly, I have no idea. If anyone does run into this case, certainly let us know.
This comment was marked helpful 0 times.



To summarize, this implementation just looks at what the original value after after was, and uses the atomicity of compare_and_swap to only insert the new node when this value is what we expect (guaranteeing that we do not overwrite a value that was just inserted in the same place). If the compare returns false, old_next will become the value that was just inserted in the next iteration.
This comment was marked helpful 0 times.



Can someone explain why is it that lock free linked-list starts doing so poorly with >16 threads whereas queue and dequeue seem to do better?
This comment was marked helpful 0 times.

It is not the lock-free linked lists that are doing poorly. They are represented by the two dark at bottom of the graph (indicated by lf in the legend).
It is actually the fine-grained(fg) locking solution which was discussed in the beginning of the lecture that is doing poorly with >16 threads. This may be because of high memory usage but I am not completely sure.
This comment was marked helpful 0 times.

So the miss rates actually turn out to be about the same for both fg and lf at high thread counts.
Hunt attributes the sharp increase in normalized runtime on a linked list at high thread counts to the burden of all the additional system calls. Each call to lock requires a context switch, and they add up when traversing the entire list rather than just looking at the top element in a queue.
This comment was marked helpful 0 times.
A few more reasons why the fine grained locking might be performing worse are: 1) While traversing the list we have to acquire the lock O(n) time compared to once in a course grained. This means we are doing O(n) writes while acquiring lock which leads to a proportional increase in cache coherence traffic. This would lead to invalidations which means other have to get their cache lines from memory. 2) Another reason which I am not entirely sure could be the fact that fine grained performs better if different threads work on different nodes of the linked list. So by doing a fine grained lock you will not be blocking threads working on other parts of the linked list. This advantage might be diminished to some extent if we have more threads working on the same linked list. Because as we increase threads the probability of threads working on similar regions go up which might lead to increased blocking even in fine-grained.
This comment was marked helpful 0 times.


First of all, it did not even occur to me that when writing parallel code, I was assuming that my code is the only thing running on the machine. I suppose I am, but I've never even really thought about it. If I did not make this assumptions, what kinds of things would change about the way I parallelized my code?
Some of the other problems associated with using locks (and why you may want to use lock-free data structures), which I think might've been mentioned earlier in the lecture: reading and writing locks for every operation results in more memory transactions, and storing a lock for each smaller structure in a larger data structure can take up a lot of space in memory.
This comment was marked helpful 0 times.

@jmnash yeah me neither. I guess this is a fair assumption to make, because each program is in its own process anyways and so races can't occur within black boxes. However of course we need to keep in mind how performance can be affected by other users on the same machine (like on Blacklight).
This comment was marked helpful 0 times.
I think the main reason we assume our code is the only thing running is because that's the way it's been in this class; our goal has been to write the fastest-running code possible, and code runs fastest when it has exclusive access to the machine. In particular, other programs running on the machine can cause weird and inconsistent performance patterns, which is frustrating for students and bad for autograding.
This comment was marked helpful 0 times.



I found a fascinating paper on a lock free implementation of maps when I was looking for ways to implement a lock-free graph. Here is the link to the paper:
http://erdani.com/publications/cuj-2004-12.pdf
In summary, the main tool introduced is the concept of a hazard pointer, which is basically a single-writer, multiple reader, shared pointer. Basically when reading a map, a processor must first acquire a hazard pointer and store the mem-address of the map it is reading in memory. After the processor is done reading the map, it releases the hazard pointer.
To update the map, the writer processor will create a completely new map and store the old map in a retired map vector. Periodically, scans are performed through the vector to see if any of the current hazard pointer still point to each map in the retired set. If no pointers exists, then it is safe to delete the map.
The overhead of copying a map is not significant because the paper assumes that Map Reads are much more common than Map Writes.
This comment was marked helpful 1 times.
In the insert case, suppose thread A acquires the prev and cur pointers before it is descheduled and thread B takes over. Then, thread B can acquire the same prev/cur pointers and insert a node between the two. Now, when thread A is rescheduled, it simply uses the same prev and cur pointers that it had before, effectively overwriting the node inserted by thread B.
In the delete case, the same exact scenario could occur but would result in a deletion of a node that was no longer in the linked list.
This comment was marked helpful 0 times.
Another thing that could happen is that the
insertanddeleteare happening at the same time. Insideinsert, it could be that nodes pointed to byprevorcurare deleted (memory is freed) bydelete. This can lead to weird errors if the freed memory is reallocated, and is being used by some other thread.This comment was marked helpful 0 times.
In general, without inserting locks, we run the risk of race conditions, especially when we try to change elements of data structures that are heavily dependent on other elements. Depending on the order in which the threads execute instructions, we can produce wildly different results, such as those described above.
This comment was marked helpful 0 times.