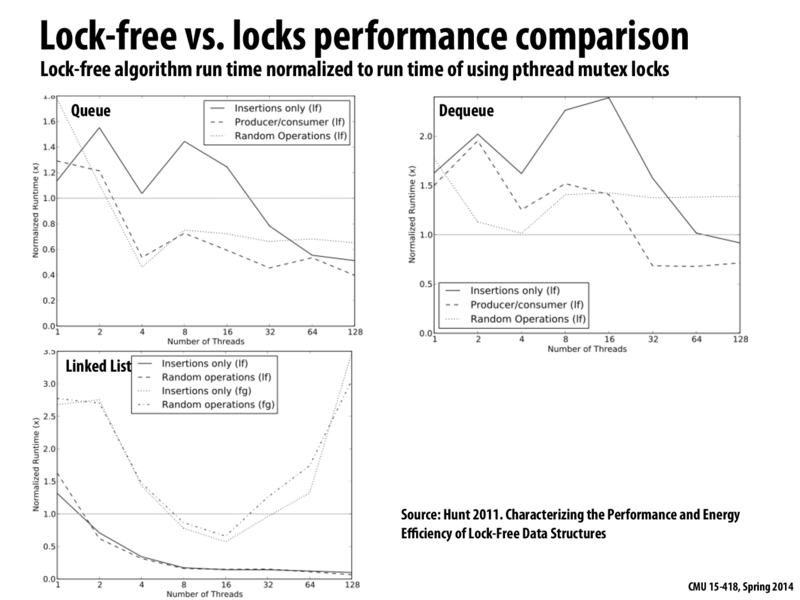
Can someone explain why is it that lock free linked-list starts doing so poorly with >16 threads whereas queue and dequeue seem to do better?
This comment was marked helpful 0 times.
achugh
It is not the lock-free linked lists that are doing poorly. They are represented by the two dark at bottom of the graph (indicated by lf in the legend).
It is actually the fine-grained(fg) locking solution which was discussed in the beginning of the lecture that is doing poorly with >16 threads. This may be because of high memory usage but I am not completely sure.
This comment was marked helpful 0 times.
Dave
So the miss rates actually turn out to be about the same for both fg and lf at high thread counts.
Hunt attributes the sharp increase in normalized runtime on a linked list at high thread counts to the burden of all the additional system calls. Each call to lock requires a context switch, and they add up when traversing the entire list rather than just looking at the top element in a queue.
This comment was marked helpful 0 times.
pradeep
A few more reasons why the fine grained locking might be performing worse are:
1) While traversing the list we have to acquire the lock O(n) time compared to once in a course grained. This means we are doing O(n) writes while acquiring lock which leads to a proportional increase in cache coherence traffic. This would lead to invalidations which means other have to get their cache lines from memory.
2) Another reason which I am not entirely sure could be the fact that fine grained performs better if different threads work on different nodes of the linked list. So by doing a fine grained lock you will not be blocking threads working on other parts of the linked list. This advantage might be diminished to some extent if we have more threads working on the same linked list. Because as we increase threads the probability of threads working on similar regions go up which might lead to increased blocking even in fine-grained.
Can someone explain why is it that lock free linked-list starts doing so poorly with >16 threads whereas queue and dequeue seem to do better?
This comment was marked helpful 0 times.
It is not the lock-free linked lists that are doing poorly. They are represented by the two dark at bottom of the graph (indicated by lf in the legend).
It is actually the fine-grained(fg) locking solution which was discussed in the beginning of the lecture that is doing poorly with >16 threads. This may be because of high memory usage but I am not completely sure.
This comment was marked helpful 0 times.
So the miss rates actually turn out to be about the same for both fg and lf at high thread counts.
Hunt attributes the sharp increase in normalized runtime on a linked list at high thread counts to the burden of all the additional system calls. Each call to
lockrequires a context switch, and they add up when traversing the entire list rather than just looking at the top element in a queue.This comment was marked helpful 0 times.
A few more reasons why the fine grained locking might be performing worse are: 1) While traversing the list we have to acquire the lock O(n) time compared to once in a course grained. This means we are doing O(n) writes while acquiring lock which leads to a proportional increase in cache coherence traffic. This would lead to invalidations which means other have to get their cache lines from memory. 2) Another reason which I am not entirely sure could be the fact that fine grained performs better if different threads work on different nodes of the linked list. So by doing a fine grained lock you will not be blocking threads working on other parts of the linked list. This advantage might be diminished to some extent if we have more threads working on the same linked list. Because as we increase threads the probability of threads working on similar regions go up which might lead to increased blocking even in fine-grained.
This comment was marked helpful 0 times.