What confused me about this is the meaning of the import region for $P$. Aren't $A$ and $B$ (and other particles in the import region of $P$) at a distance of more than $R$ apart? They could be as far as $\sqrt 2 R$ apart it seems.
This comment was marked helpful 0 times.
jmnash
Yes, A and B are more than distance R apart from each other if you were to draw a straight line between them. However, one of the ideas behind neutral territory is that when A and B are interacting, you don't have to import everything in the space between them. So, you only have to import the rows and columns that actually contain A and B. Since A and B are distance R from P, you only have to import data up to distance R away from P in 4 directions. In each of these 4 directions, the area is bR. Then the $b^2$ comes from the yellow region that is already on P. That is why the size of the import region is $4bR + b^2$. It doesn't matter how far A and B are from each other, only how far each of them is from P.
I think this is what you were asking about... Is this explanation correct?
This comment was marked helpful 0 times.
smklein
It kind of seems to me like moving to the same x/y square is... somewhat arbitrary? Would there be any potential advantage of this mechanism over, say, hashing the combination of an ID of "A" and "B", to consistently process the interaction between A and B on an effectively random processor?
This comment was marked helpful 0 times.
aew
I'm not sure, but I think selecting the x/y square would improve spatial locality over simply selecting a random processor.
For example, if we had a mesh interconnect on the above slide, A and B would only be two links away from the yellow square. But if we had selected a random processor, chances are that that processor would be much further. Choosing the x/y square reduces the latency of communication between processors.
Can someone verify this?
This comment was marked helpful 0 times.
spilledmilk
Question: Why is the import region of the yellow square just the blue regions? Wouldn't it be all pairs of points where the first point has its X coord in the blue row and the second point has its Y coord in the blue column?
This comment was marked helpful 0 times.
benchoi
@spilledmilk: that would only be the case if the range were infinite - there are many pairs satisfying your description whose points are too far away from each other, so we need not communicate all of those points to the yellow square.
This comment was marked helpful 0 times.
eatnow
@spilledmilk: If you're asking why it is not the whole row and the whole column, it is because we are not considering interactions beyond the specified radius.
Also I think it should be the first point with X coordinate in the blue column, and Y coordinate in the blue row
This comment was marked helpful 0 times.
tcz
@sbly @jmnash Is part of the interaction computation checking the distance between the points? If so, it seems like the motivation behind this is that processor P will have to pull both A and B into memory anyway, so you might as well check their interaction with each other while you have them. This way, the pair (A,B) is only ever loaded by one processor.
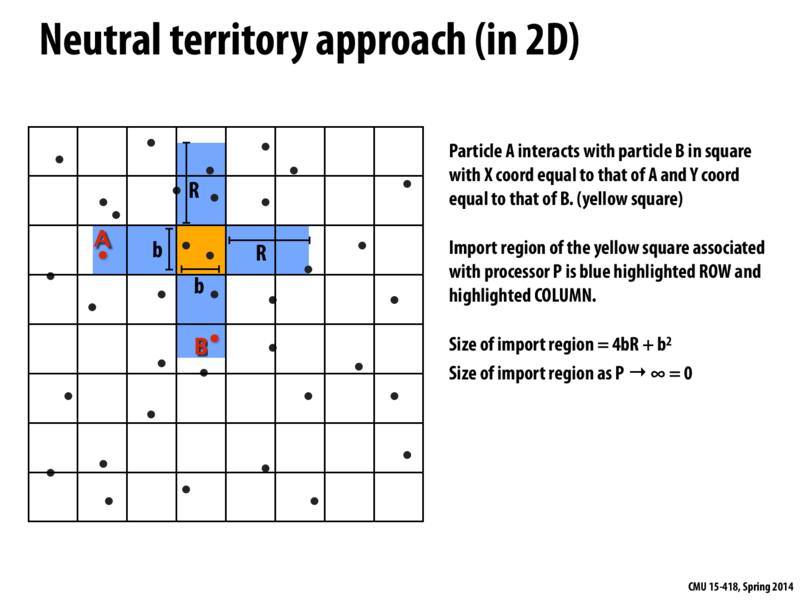
What confused me about this is the meaning of the import region for $P$. Aren't $A$ and $B$ (and other particles in the import region of $P$) at a distance of more than $R$ apart? They could be as far as $\sqrt 2 R$ apart it seems.
This comment was marked helpful 0 times.
Yes, A and B are more than distance R apart from each other if you were to draw a straight line between them. However, one of the ideas behind neutral territory is that when A and B are interacting, you don't have to import everything in the space between them. So, you only have to import the rows and columns that actually contain A and B. Since A and B are distance R from P, you only have to import data up to distance R away from P in 4 directions. In each of these 4 directions, the area is bR. Then the $b^2$ comes from the yellow region that is already on P. That is why the size of the import region is $4bR + b^2$. It doesn't matter how far A and B are from each other, only how far each of them is from P.
I think this is what you were asking about... Is this explanation correct?
This comment was marked helpful 0 times.
It kind of seems to me like moving to the same x/y square is... somewhat arbitrary? Would there be any potential advantage of this mechanism over, say, hashing the combination of an ID of "A" and "B", to consistently process the interaction between A and B on an effectively random processor?
This comment was marked helpful 0 times.
I'm not sure, but I think selecting the x/y square would improve spatial locality over simply selecting a random processor. For example, if we had a mesh interconnect on the above slide, A and B would only be two links away from the yellow square. But if we had selected a random processor, chances are that that processor would be much further. Choosing the x/y square reduces the latency of communication between processors. Can someone verify this?
This comment was marked helpful 0 times.
Question: Why is the import region of the yellow square just the blue regions? Wouldn't it be all pairs of points where the first point has its X coord in the blue row and the second point has its Y coord in the blue column?
This comment was marked helpful 0 times.
@spilledmilk: that would only be the case if the range were infinite - there are many pairs satisfying your description whose points are too far away from each other, so we need not communicate all of those points to the yellow square.
This comment was marked helpful 0 times.
@spilledmilk: If you're asking why it is not the whole row and the whole column, it is because we are not considering interactions beyond the specified radius.
Also I think it should be the first point with X coordinate in the blue column, and Y coordinate in the blue row
This comment was marked helpful 0 times.
@sbly @jmnash Is part of the interaction computation checking the distance between the points? If so, it seems like the motivation behind this is that processor P will have to pull both A and B into memory anyway, so you might as well check their interaction with each other while you have them. This way, the pair (A,B) is only ever loaded by one processor.
This comment was marked helpful 0 times.