So here we discussed interesting tradeoffs between keeping the final addition of sums as a linear operation rather than implementing a reduce or something similar to parallelize the final addition. What we found that if P >= N, the + P addition term starts to play a significant role in the total computation time of the problem.
Overall, if we are working on a high pixel density image with a standard multi-core computer, the extra synchronization management needed to distribute the reduce might start to outweigh the benefits of changing the +P term into a +log(P) term.
However, if we are working on a supercomputer with a bajillion processors to process a small image, we find that there will be processor idle time or large waste of time trying to optimize the final addition
This comment was marked helpful 0 times.
sss
Here wouldn't it be possible now, with the phase 2 change, to merge phase 1 with phase 2? As now we can just combine the step of increasing the brightness with the computation of the partial sum on each pixel.
This comment was marked helpful 0 times.
kayvonf
@sss: I like your thinking. Could you elaborate more on your proposal to "merge"? Why do you think would that idea might improve the performance of the program as compared to the two-step strategy discussed above?
This comment was marked helpful 0 times.
sss
Here I feel that having a phase distinction means that: Only when all processing in phase 1 completes then the computation of partial sums begins. Which I think would be fine the case of small images where every pixel can be computed in parallel, and all pixels are done in 1 computation step; however in the case of large images, once the computation on that pixel group is done, the threads might as well perform some phase 2 computation, as it's already loaded, for the group and write a final value into memory. This is so that that group of pixels doesn't have to be touched or cared about again. I think this'll save some IO memory loading as well as context switching.
This comment was marked helpful 0 times.
kayvonf
good! But let me try and explain in the terminology of the course.
By reordering the computation, you are able to reduce its bandwidth requirements by performing two operations each each time you load a pixel rather than just one. Note that you have not changed the amount of computation done. So your transformation has increased the arithmetic intensity of the program (or, in other words, reduced the communication-to-computation ratio).
The program was changed from:
// step 1
for (int i=0; i<N; i++)
pixel[i] = increase_brightness(pixel[i]);
// step 2
float sum = 0.f;
for (int i=0; i<N; i++)
sum += pixel[i];
float average = sum / N;
To:
float sum = 0.f;
for (int i=0; i<N; i++) {
pixel[i] = increase_brightness(pixel[i]);
sum += pixel[i];
}
float average = sum / N;
Notice that if N is sufficiently large that the entire image cannot fit in cache, then due to capacity misses the image will need to be loaded again from memory in the second for loop. The restructured code avoids this miss by performing both the brightness increase and the summation back-to-back, thus requiring only one load.
My code example is not parallel for simplicity, but this transformation works equally well in the parallel case as well.
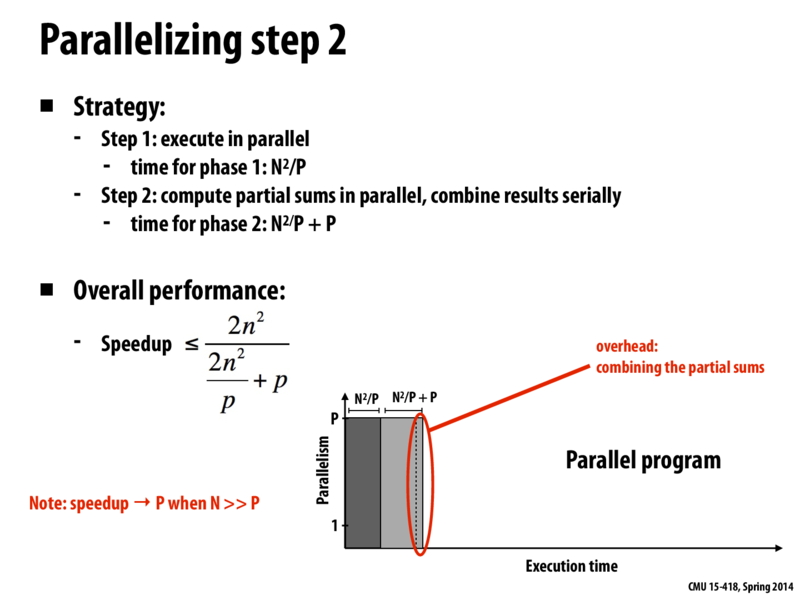
So here we discussed interesting tradeoffs between keeping the final addition of sums as a linear operation rather than implementing a reduce or something similar to parallelize the final addition. What we found that if P >= N, the + P addition term starts to play a significant role in the total computation time of the problem.
Overall, if we are working on a high pixel density image with a standard multi-core computer, the extra synchronization management needed to distribute the reduce might start to outweigh the benefits of changing the +P term into a +log(P) term.
However, if we are working on a supercomputer with a bajillion processors to process a small image, we find that there will be processor idle time or large waste of time trying to optimize the final addition
This comment was marked helpful 0 times.
Here wouldn't it be possible now, with the phase 2 change, to merge phase 1 with phase 2? As now we can just combine the step of increasing the brightness with the computation of the partial sum on each pixel.
This comment was marked helpful 0 times.
@sss: I like your thinking. Could you elaborate more on your proposal to "merge"? Why do you think would that idea might improve the performance of the program as compared to the two-step strategy discussed above?
This comment was marked helpful 0 times.
Here I feel that having a phase distinction means that: Only when all processing in phase 1 completes then the computation of partial sums begins. Which I think would be fine the case of small images where every pixel can be computed in parallel, and all pixels are done in 1 computation step; however in the case of large images, once the computation on that pixel group is done, the threads might as well perform some phase 2 computation, as it's already loaded, for the group and write a final value into memory. This is so that that group of pixels doesn't have to be touched or cared about again. I think this'll save some IO memory loading as well as context switching.
This comment was marked helpful 0 times.
good! But let me try and explain in the terminology of the course.
By reordering the computation, you are able to reduce its bandwidth requirements by performing two operations each each time you load a pixel rather than just one. Note that you have not changed the amount of computation done. So your transformation has increased the arithmetic intensity of the program (or, in other words, reduced the communication-to-computation ratio).
The program was changed from:
To:
Notice that if
Nis sufficiently large that the entire image cannot fit in cache, then due to capacity misses the image will need to be loaded again from memory in the secondforloop. The restructured code avoids this miss by performing both the brightness increase and the summation back-to-back, thus requiring only one load.My code example is not parallel for simplicity, but this transformation works equally well in the parallel case as well.
This comment was marked helpful 2 times.