Just a recap, on this slide, Kayvon explained why interleaved execution is better than "chunked" ones (as the one in the next slide). The key point here is actually spatial locality: when the zeroth instance executes on the zeroth SIMD unit, it loads the element 0,1,2,3 (assuming one cache line is 4 elem). Then the remaining three SIMDs don't have to fetch their data from memory again, thus making it faster.
A quick question here: since difference SIMD units can fetch data at the same time, what happens if unit 0 and unit 1 (maybe also 2 and 3) try to fetch the same cache line(like in the example above)? Wouldn't it result in longer stall/inconsistency in cache? How does unit 1,2,3 know that unit 0 is already working on their data?
I'm sure there are some problems with my interpretation, feel free to correct me.
This comment was marked helpful 0 times.
mofarrel
Here, the ISPC code is going to be translated into SIMD vector instructions. A vector load gets 8 * 32 (or 4 * 32 in the case of SSE) bits from memory. If the memory being loaded is not contiguous, ISPC will have to use a vector gather instruction. A vector gather instruction brings together values from across memory, which is more costly as it is searching through memory (violating spatial locality).
This comment was marked helpful 1 times.
kayvonf
Nice @mofarrel. Everyone, the definition of vector gather is on slide 46.
This comment was marked helpful 0 times.
spilledmilk
Going back to @lixf's question, there is a case (but not this one) where his or her interpretation is partially correct, and I believe that this is a key difference to be taken into account in writing code that uses thread-level parallelism versus code that uses SIMD processing.
When writing code that utilizes thread-level parallelism, interleaved assignment is not ideal. This is due to the fact that if multiple processors modify data in the same cache line, then each time data is modified, all subsequent attempts from other processors to access or modify data in the cache line will result in a cache miss, a phenomenon known as "false sharing". This false sharing occurs very frequently when using interleaved assignment with multiple threads since the elements that are accessed are adjacent and the threads are usually executed on different processors. More on this topic here and here.
However, when using SIMD processing, as in the ISPC code for this example, interleaved assignment is ideal. As @mofarrel mentioned, using interleaved assignment in ISPC code allows the processor to take full advantage of the fast vector load instruction that loads consecutive bytes from memory instead of the more expensive vector gather instruction that takes a certain number of bits at fixed offsets from the given start address. Because the parallelism in this case is implemented with SIMD vector intrinsics, multiple data values are processed at once on the same processor, removing the possibility of false sharing.
TL;DR: Use blocked assignment with thread-level parallelism and interleaved assignment with SIMD vector intrinsics.
This comment was marked helpful 1 times.
mmp
Extremely well-said, @spilledmilk! I think that this is a very fundamental observation, and one that's useful for anyone doing parallel programming to digest well.
One thing that I think is also explained from this observation is that it's often much easier to take a large existing program and apply SIMD parallelism to it than it is to multi-thread it. Multi-threading generally requires a top-down decomposition of work into bigger chunks, while SIMD can be applied to much smaller amounts of data, operating more opportunistically / bottom-up. (For example, it is generally worth applying SIMD to a fairly simple computation a 16-element array in a function, while it isn't worth multithreading that!)
Having digested this on the CPU side, it's worth keeping it in mind as you dig into GPU stuff, where the ~multi-threading and the SIMD is more tightly coupled than it is on the CPU, and where some of these trade-offs are different...
This comment was marked helpful 0 times.
cwswanso
WOAH. Is this gather instruction very related to the gather here?
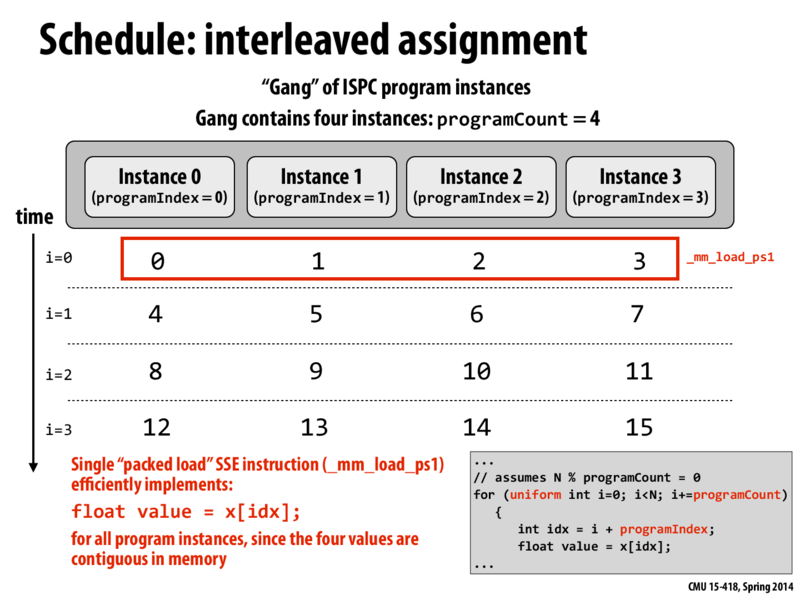
Just a recap, on this slide, Kayvon explained why interleaved execution is better than "chunked" ones (as the one in the next slide). The key point here is actually spatial locality: when the zeroth instance executes on the zeroth SIMD unit, it loads the element 0,1,2,3 (assuming one cache line is 4 elem). Then the remaining three SIMDs don't have to fetch their data from memory again, thus making it faster.
A quick question here: since difference SIMD units can fetch data at the same time, what happens if unit 0 and unit 1 (maybe also 2 and 3) try to fetch the same cache line(like in the example above)? Wouldn't it result in longer stall/inconsistency in cache? How does unit 1,2,3 know that unit 0 is already working on their data?
I'm sure there are some problems with my interpretation, feel free to correct me.
This comment was marked helpful 0 times.
Here, the ISPC code is going to be translated into SIMD vector instructions. A vector load gets 8 * 32 (or 4 * 32 in the case of SSE) bits from memory. If the memory being loaded is not contiguous, ISPC will have to use a vector gather instruction. A vector gather instruction brings together values from across memory, which is more costly as it is searching through memory (violating spatial locality).
This comment was marked helpful 1 times.
Nice @mofarrel. Everyone, the definition of vector gather is on slide 46.
This comment was marked helpful 0 times.
Going back to @lixf's question, there is a case (but not this one) where his or her interpretation is partially correct, and I believe that this is a key difference to be taken into account in writing code that uses thread-level parallelism versus code that uses SIMD processing.
When writing code that utilizes thread-level parallelism, interleaved assignment is not ideal. This is due to the fact that if multiple processors modify data in the same cache line, then each time data is modified, all subsequent attempts from other processors to access or modify data in the cache line will result in a cache miss, a phenomenon known as "false sharing". This false sharing occurs very frequently when using interleaved assignment with multiple threads since the elements that are accessed are adjacent and the threads are usually executed on different processors. More on this topic here and here.
However, when using SIMD processing, as in the ISPC code for this example, interleaved assignment is ideal. As @mofarrel mentioned, using interleaved assignment in ISPC code allows the processor to take full advantage of the fast vector load instruction that loads consecutive bytes from memory instead of the more expensive vector gather instruction that takes a certain number of bits at fixed offsets from the given start address. Because the parallelism in this case is implemented with SIMD vector intrinsics, multiple data values are processed at once on the same processor, removing the possibility of false sharing.
TL;DR: Use blocked assignment with thread-level parallelism and interleaved assignment with SIMD vector intrinsics.
This comment was marked helpful 1 times.
Extremely well-said, @spilledmilk! I think that this is a very fundamental observation, and one that's useful for anyone doing parallel programming to digest well.
One thing that I think is also explained from this observation is that it's often much easier to take a large existing program and apply SIMD parallelism to it than it is to multi-thread it. Multi-threading generally requires a top-down decomposition of work into bigger chunks, while SIMD can be applied to much smaller amounts of data, operating more opportunistically / bottom-up. (For example, it is generally worth applying SIMD to a fairly simple computation a 16-element array in a function, while it isn't worth multithreading that!)
Having digested this on the CPU side, it's worth keeping it in mind as you dig into GPU stuff, where the ~multi-threading and the SIMD is more tightly coupled than it is on the CPU, and where some of these trade-offs are different...
This comment was marked helpful 0 times.
WOAH. Is this gather instruction very related to the gather here?
This comment was marked helpful 0 times.