



I know ISPC uses caches but does anyone have any explicit details about the caches and how ISPC utilizes them? For example, how big are the caches and is what is the average hit/miss rate that ISPC gets. Is ISPC efficient at utilizing caches in terms of speed or in terms of having a high hit rate?
EDIT: sry for the late update, but i figured out my doubts shortly after!
This comment was marked helpful 0 times.

@element03: Could you please rephrase your question since I did not understand the comments "ISPC uses caches" and "how does ISPC utilize them?"
ISPC is a programming language. It is used to express programs. Those programs are compiled into binaries and executed on CPUs. The implementation of those CPUs may contain caches.
This comment was marked helpful 0 times.

ISPC has an excellently written user's guide.
It is highly recommend that you read the following sections:
- The execution model
- The language reference, in particular the part about control flow.
These sections largely discuss ISPC programming abstractions. The performance guide begins to dig deeper into how the compiler will implement these abstractions on a modern multi-core CPU with SIMD instructions.
This comment was marked helpful 0 times.



Do all instances in a gang finish execution at the same time (because they're all running the same instructions?) Or do they finish at different times but we have to wait until they're all done for control to return?
This comment was marked helpful 0 times.
@sbly: I'll turn the question back on you. Given what you know about SIMD execution after assignment 1, what do you think?
This comment was marked helpful 0 times.

Unless ISPC fiugres out how to evenly allocate work ( which I believe is really hard ) I don't think its possible. All of them do not end at the same time in my opinion.
This comment was marked helpful 0 times.

@sbly I highly doubt all instances complete simultaneously. Just like our simulated "programs" in lecture 1, we had the case where one person finished his job early and waited, while another person worked until the very end. Everyone was running the "same instructions" (adding numbers together), but some people had more numbers to add than others.
Similarly, in this case, all threads are running the same instructions, but some instances have to calculate more, and take longer, than others. Thus, any threads which have completed their job wait until all of the other threads have also completed, upon which they return the answer.
This comment was marked helpful 0 times.

As I understand it, each thread is running identical logic on 8-wide vector data which is being manipulated as a single entity. Each ALU then carries identical operations during each clock cycle, and so the threads should finish at the same clock cycle. If I'm completely wrong on this, can some please correct me? :(
edit: assuming appropriate simd implementation on suitable hardware.
This comment was marked helpful 0 times.

I think it depends on the code. If some instances are given way more work then other instances, then the instances will not finish at the same time, but if the workload is approximately evenly distributed among the instances, then they will finish approximately at the same time. Hence, I think the key is distributing the work evenly so that for example, one instance (i.e. one index in the loop) does not have too much work to do then other instances.
Please correct me if I'm wrong, since I'm also slightly confused about the notion.
This comment was marked helpful 0 times.

@kkz is right about this one. SIMD stands for same instruction, multiple data; all the tasks in the gang are running the same instruction stream (not just duplicate streams but actually the same one), so they are always executing the same instructions at the same time. For this case, they'd load a batch of numbers, compute sign on all of them in lockstep, and write those results back out again. In the case where the numbers take different amounts of work to compute they still send the instructions to all the ALUs, but throw away the outputs for those ALUs that didn't need to do that work. A diagram is here.
This comment was marked helpful 0 times.

After finishing the extra credits of sqrt SSE version, I think a gang of instances on a single core actually represents a single vector lane. Every unit of it runs completely same operation for each cycle. In this level, "busy" and "idle" are distinguished by whether the unit is computing useful data (they are all busy in physical view). Those invalid data would be removed by the mask after all units finish their jobs.
This comment was marked helpful 0 times.

I think to achieve simultaneous execution time, it depends on not only the same instructions, but also the same data. Some inputs may cause instructions more time to be executed. This could be observed very clear from problem 4 in assignment 1. If the input data is not evenly distributed then some program instances would take longer to finish.
This comment was marked helpful 0 times.

As @kkz and @mchoquet mentioned, all instances will complete at the same time because they are executing the same instructions. When different inputs require more work, this means that instances with input requiring less work will remain idle. As @analysiser said, this was very apparent in assignment 1. In the first question, uneven distribution of workload also limited the speedup possible by parallelization.
This comment was marked helpful 0 times.

Question: I want to see someone take a crack at describing the semantics of the call to the ISPC function sinx here. What does ISPC programming model dictate this call does? (I'm not talking about implementation, I'm talking semantics)
This comment was marked helpful 0 times.

I feel like I'm just repeating the slide, but here I go: Semantically, the call to the ISPC function will create a group of program instances, which will execute code in parallel (in this case, calculate the sin function for an array of floating point values). Upon completion, the thread that called the ISPC function will resume execution. Any hint on how can I expand?
This comment was marked helpful 0 times.
@aaguilet: No problem at all repeating a slide in your own words. Good work.
However, perhaps to convince you that the exercise is not as trivial as it seems, I'll again repeat the idea of the slide with even more detail. The call of the ISPC function sinx launches a gang of programCount program instances that run concurrently---although as Matt points out, the semantics essentially imply run in parallel---(a "group of program instances" is called a gang). Each instance in a gang has a different programId. When all instances complete execution of the ISPC function sinx then control returns to the calling C code. (just saying "upon completion is vague"... upon completion of what?).
This comment was marked helpful 1 times.
I'm not a 100% sure on this, but I'd guess that "completion" refers to the program counter (not the programCount ISPC variable, but the instruction PC) reaching the end of and returning from the sinx subroutine.
Copy pasting from the ISPC Execution model guide:
"The ispc execution model provides an important guarantee about the behavior of the program counter and execution mask: the execution of program instances is maximally converged. Maximal convergence means that if two program instances follow the same control path, they are guaranteed to execute each program statement concurrently."
And that is assuming that there is conditional control flow in the code. But in this case, sinx does not have any conditionals, so essentially the execution mask for each instruction will be all 1's.
In regards to for loops, here's another copy-pasted example from the guide:
"Consider for example an image filtering operation where the program loops over pixels adjacent to the given (x,y) coordinates:
float box3x3(uniform float image[32][32], int x, int y) {
float sum = 0;
for (int dy = -1; dy <= 1; ++dy)
for (int dx = -1; dx <= 1; ++dx)
sum += image[y+dy][x+dx];
return sum / 9.;
}
In this case, a sufficiently smart compiler could determine that dx and dy have the same value for all program instances and thus generate more optimized code from the start, though this optimization isn't yet implemented in ispc.
In particular, ispc can avoid the overhead of checking to see if any of the running program instances wants to do another loop iteration. Instead, the compiler can generate code where all instances always do the same iterations."
So since in sinx the loop variable j is uniform, technically ISPC will generate code so that all program instances will execute the same exact instructions (concurrently). Although, not sure about the whole "this optimization isn't yet implemented in ispc."
I went off on a tangent there, but to go back to @kayvonf 's question, based on how the execution model is described in that guide, it seems that ISPC will execute sinx step-by-step across all program instances. Should there be something that keeps track of how many more gangs must be made to finish processing all data? (i.e. the most trivial way I can think of is something like
//ISPC part of assembly starts here
gangs = total data / programCount;
for (int i = 0; i < gangs; i++)
//SPMD call
//ISPC part of assembly ends here
)
This comment was marked helpful 1 times.
@selena731. Excellent thinking in your post. (Class this is a good example of digging in). Now that you've done that, here are some suggested fixes/clarifications to your post.
By "completed" I believe @aaguilet and I were simply referring to completion (termination) of the program instance. That is, when all program instances in the gang complete execution of the logic in ISPC function
sinx, the gang itself is complete and the ISPC function then returns to the calling thread of C code.Your statement "it seems that ISPC will execute
sinxstep by step across all program instances" is completely correct. However, ISPC won't do anything to compute how many gangs are needed. There are only two ways to create a gang of program instances in ISPC:
- By calling the IPSC function from C code (
sinxin this case). In this case there is one gang per call. - By using
launchto create tasks, which are executed by a gang. In this case there is one gang per task.
This comment was marked helpful 0 times.

One way to test your understanding of ISPC's mapping of the SPMD programming model abstraction onto SIMD instructions is to see if you understand what the compiler will do if you set the gang size to 8 on a SIMD-width 4 machine. (Or a gang size of 16 and a SIMD-width 8 machine.
A student last year posted the following:
To demonstrate the differences in compiling with different --target options, namely how the double-width is handled, I made a small test program:
export void foo(uniform int N, uniform float input[], uniform float output[])
{
for (uniform int i = 0; i < N; i+= programCount) {
output[i + programIndex] = 5 * input[i + programIndex] + 7;
}
}
It's easy to find the duplicated instructions in the double width output.
sse4:
1e3: 0f 10 14 06 movups (%rsi,%rax,1),%xmm2
1e7: 0f 59 d0 mulps %xmm0,%xmm2
1ea: 0f 58 d1 addps %xmm1,%xmm2
1ed: 0f 11 14 02 movups %xmm2,(%rdx,%rax,1)
sse4-x2:
333: 0f 10 14 06 movups (%rsi,%rax,1),%xmm2
337: 0f 10 5c 06 10 movups 0x10(%rsi,%rax,1),%xmm3
33c: 0f 59 d0 mulps %xmm0,%xmm2
33f: 0f 58 d1 addps %xmm1,%xmm2
342: 0f 59 d8 mulps %xmm0,%xmm3
345: 0f 58 d9 addps %xmm1,%xmm3
348: 0f 11 5c 02 10 movups %xmm3,0x10(%rdx,%rax,1)
34d: 0f 11 14 02 movups %xmm2,(%rdx,%rax,1)
The avx dumps were similar. It's interesting that the movups instructions for each group of 4 are done one after another, but the mulps and addps are grouped.
This comment was marked helpful 0 times.
In class we talked about the possibility of other potential implementations of the ISPC abstraction (e.g., non-SIMD). I'll repeat my in-class point below, but make sure you read to the end to get the full story, as Matt Pharr, the creator of ISPC stepped in to clarify my response:
Kayvon said: Given the semantics of the ISPC programming model, alternative implementations are also possible. For example, for the program above, a perfectly valid ISPC compiler might not emit AVX instructions and simply emit a sequential binary that executes the logic from each of the program instances one after each other. The resulting compiled binary is correct -- it computes what the program specifies it should compute -- it's just slow). Alternatively, it would be valid for the compiler to have spawned eight pthreads, one for each program instance to carry out the logic on eight cores.
The point is that there is nothing in the basic ISPC model that dictates this choice and the programmer need not think about the implementation if he/she simply wants to create a correct program. However, as I'm sure it's now clear in this class, the programmer will need to think about the underlying implementation if an efficient program is desired.
Now, I'm being a little loose with my comments here because there are in fact certain details in ISPC that do put constraints on the implementation. One example is the cross-instance functions (e.g, reduceAdd), which do place a scheduling constraint on execution. Since reduceAdd entails communication of values between program instances, all program instances must run up until this point in the program to determine what values to communicate. (Otherwise, it's impossible to perform the reduction!) Consider an ISPC function that contains a reduceAdd. The ISPC system can not run instance 0 to completion before starting instance 1 because the reduceAdd operation, which must be executed as part of instance 0, depends on values computed by instance 1.
Then Matt Pharr, creator of ISPC corrected me with the following clarification...
Clarification and corrections on @kayvonf: The implementation of ISPC is actually a bit more constrained by the language semantics (and I'll argue that's a good thing.) It'd be difficult to provide an implementation of ISPC that used one CPU hardware thread (think: pthread) per program instance and ran efficiently.
ISPC guarantees that program instances synchronize after each program sequence point, which is roughly after each statement. This allows writing code like:
uniform float a[programCount];
a[programIndex] = foo();
return a[programCount - 1 - programIndex];
In the third line, program instances are reading values written by other program instances in line 2. This is valid ISPC, and is one of the idiomatic ways to express communication between the program instances. (See The ISPC User's Guide for details.)
So one implication of this part of the language abstraction is certainly that it constrains viable implementation options; perhaps one could implement ISPC by spawning a pthread per program instance, but it'd be necessary for the compiler to conservatively emit barriers at places where it was possible that there would be inter-program instance communication. This in turn is tricky because:
In a language with a C-based pointer model like ISPC, the compiler has to be pretty conservative about what a pointer may actually point to.
Barrier synchronization on CPUs is sort of a pain to do efficiently. (This is a challenge for CPU OpenCL implementations; see discussion in this paper for some details and further references.
Both of these also mean that an implementation that implemented program instances as one-to-one with CPU HW threads would make it much harder for the programmer to reason about their program's performance; small changes to the input program could cause large performance deltas, just because they inadvertently confused the compiler enough about what was actually going on that it had to add another barrier. Especially for a language that is intended to provide good performance transparency to the programmer, this is undesirable.
In the end, I don't think there is any sensible implementation of an ISPC gang other than one that ran on SIMD hardware. Indeed, if you take out the foreach stuff in the language and just have the programCount/programIndex constructs, you can look at what is left as C extended with thin abstractions on top of the SIMD units, not even an explicitly parallel language at all. (In a sense.)
This comment was marked helpful 0 times.
I have some questions/concerns about Matt Pharr's reply and hope someone could explain some details to me. Thanks in advance.
He says: "ISPC guarantees that program instances synchronize after each program sequence point, which is roughly after each statement." Is this really preferable for a efficiency-driven language? I understand that this constrain will make inter-instance communication possible, but why do programmers want to synchronize in an ISPC program? For example, if I want to sum up an array like the example in class, it should be my responsibility to use an array of partial sum inside the ISPC code and to avoid synchronization. I remember we talking about one of the "requirements" to use SIMD is the absence of dependencies among different runs of the same program. Thus, wouldn't this constrain defeat the purpose of having ISPC at the first place (an example of a "regionally" unbalanced work load would result in terrible performance)? (or perhaps I'm missing something)
By "barrier", does he mean locks? Also, he says: "an implementation that implemented program instances as one-to-one with CPU HW threads would make it much harder for the programmer to reason about their program's performance." I don't quite understand why this is the case. If they were to use HW thread implementation, isn't it just like having pthreads? Why is pthread hard to reason?
At the end, he says: "if you take out the foreach stuff in the language and just have the programCount/programIndex constructs,… not even an explicitly parallel language at all." But isn't the underlying implementation achieved by using SIMD vectors? Does he mean it only does't LOOK like a parallel language?
This comment was marked helpful 0 times.

Sorry, perhaps it was explained in lecture but what exactly does --target change in an ISPC program? The size of the gang size?
This comment was marked helpful 0 times.
Yes, --target is a compiler directive to set the instruction set targeted and the gang size of a n ISPC program. For example --target sse4-i32x8 says use a gang size of 8 and emit SSE4 instructions. --target avx2-i32x16 means emit AVX2 instructions and use a gang size of 16.
Full reference is http://ispc.github.io/ispc.html#selecting-the-compilation-target.
This comment was marked helpful 0 times.

@lixf: Hi,
I think the efficiency of the semantic ISPC chooses depends on the workload type, as no single language is suitable for every kind of job. If ISPC is not a good fit for the work, then we shouldn't use it.
Barriers are used to order instructions, preventing problems caused by reordering of memory instructions at compile or run time. What I interpret Matt means here is that, since barriers are expensive to execute and using pthreads requires adding (sometimes unexpected) barriers, programmers are hard to reason about performance.
I think he means that if only the programCount/programIndex constructs remain, ISPC doesn't even take advantage of multicores, so it's hard to call it a "parallel" language.
This comment was marked helpful 0 times.

@lixf: For 1., I am guessing that this type of "synchronization" is "free", and comes at no additional cost. If we have a bunch of threads then each thread needs to wait for every other to reach the same point, hence the need for barriers. But in this case, each operation occur across the gang before the next operation.
It looks like increasing the gang size would work until the point where we have more gangs than can fit on the mmx registers. What happens then? Is it simply not allowed, or is ISPC able to do something fancy to ensure the "synchronize after each program sequence point" guarantee?
This comment was marked helpful 0 times.

Lots of good questions and comments here!
Re 1: @lixf makes a fair point that that synchronization isn't generally taken advantage of by programmers--really only in cases where there is inter-program-instance communication, which is not the most common case. I think what I'd say here is that there's essentially no cost to it in practice (it's generally the natural way to compile ISPC programs to a CPU), and there is some value to not requiring explicit synchronization points in the program as written by the programmer for the cases when synchronization is needed..
Re 2: @eatnow explains it well. I was trying to make the point that, given ispc's semantics of synchronization points after every program sequence point, if one wanted to implement ispc where each program instance was in a separate thread, then the compiler would have to emit code such that all threads synchronized after each program statement--this would be really slow. So then a better implementation might try to only synchronize threads after statements where there might have been inter-program-instance communication, but due to C's pointer model, it's hard to reason about that. So there would be lots of unnecessary synchronizations, and the programmer would likely often be surprised that synchronization were happening at places where instances weren't in fact communicating...
On 3, what I actually meant is that it's more of a language for doing computations with short, programCount-sized vectors, than it is a more general parallel language. I'm not sure that's a super important point in any case.
Finally, ispc only supports a few gang sizes--basically from 4 to 16-wide (depending on vector ISA compiled to--SSE vs AVX, etc.) In general, increasing the gang size increases the number of live registers, so if it gets too big, cycles are wasted on register spills/refills.
I think that overs everything, but let me know if anything's still not clear...
This comment was marked helpful 0 times.
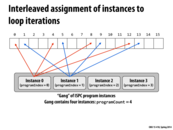




Just a recap, on this slide, Kayvon explained why interleaved execution is better than "chunked" ones (as the one in the next slide). The key point here is actually spatial locality: when the zeroth instance executes on the zeroth SIMD unit, it loads the element 0,1,2,3 (assuming one cache line is 4 elem). Then the remaining three SIMDs don't have to fetch their data from memory again, thus making it faster.
A quick question here: since difference SIMD units can fetch data at the same time, what happens if unit 0 and unit 1 (maybe also 2 and 3) try to fetch the same cache line(like in the example above)? Wouldn't it result in longer stall/inconsistency in cache? How does unit 1,2,3 know that unit 0 is already working on their data?
I'm sure there are some problems with my interpretation, feel free to correct me.
This comment was marked helpful 0 times.

Here, the ISPC code is going to be translated into SIMD vector instructions. A vector load gets 8 * 32 (or 4 * 32 in the case of SSE) bits from memory. If the memory being loaded is not contiguous, ISPC will have to use a vector gather instruction. A vector gather instruction brings together values from across memory, which is more costly as it is searching through memory (violating spatial locality).
This comment was marked helpful 1 times.
Nice @mofarrel. Everyone, the definition of vector gather is on slide 46.
This comment was marked helpful 0 times.

Going back to @lixf's question, there is a case (but not this one) where his or her interpretation is partially correct, and I believe that this is a key difference to be taken into account in writing code that uses thread-level parallelism versus code that uses SIMD processing.
When writing code that utilizes thread-level parallelism, interleaved assignment is not ideal. This is due to the fact that if multiple processors modify data in the same cache line, then each time data is modified, all subsequent attempts from other processors to access or modify data in the cache line will result in a cache miss, a phenomenon known as "false sharing". This false sharing occurs very frequently when using interleaved assignment with multiple threads since the elements that are accessed are adjacent and the threads are usually executed on different processors. More on this topic here and here.
However, when using SIMD processing, as in the ISPC code for this example, interleaved assignment is ideal. As @mofarrel mentioned, using interleaved assignment in ISPC code allows the processor to take full advantage of the fast vector load instruction that loads consecutive bytes from memory instead of the more expensive vector gather instruction that takes a certain number of bits at fixed offsets from the given start address. Because the parallelism in this case is implemented with SIMD vector intrinsics, multiple data values are processed at once on the same processor, removing the possibility of false sharing.
TL;DR: Use blocked assignment with thread-level parallelism and interleaved assignment with SIMD vector intrinsics.
This comment was marked helpful 1 times.
Extremely well-said, @spilledmilk! I think that this is a very fundamental observation, and one that's useful for anyone doing parallel programming to digest well.
One thing that I think is also explained from this observation is that it's often much easier to take a large existing program and apply SIMD parallelism to it than it is to multi-thread it. Multi-threading generally requires a top-down decomposition of work into bigger chunks, while SIMD can be applied to much smaller amounts of data, operating more opportunistically / bottom-up. (For example, it is generally worth applying SIMD to a fairly simple computation a 16-element array in a function, while it isn't worth multithreading that!)
Having digested this on the CPU side, it's worth keeping it in mind as you dig into GPU stuff, where the ~multi-threading and the SIMD is more tightly coupled than it is on the CPU, and where some of these trade-offs are different...
This comment was marked helpful 0 times.

WOAH. Is this gather instruction very related to the gather here?
This comment was marked helpful 0 times.

Isnt this a blocked assignment example?
This comment was marked helpful 0 times.
ARG! Yes it is. Incorrect title, good catch! #fixme
This comment was marked helpful 0 times.

Question: Can someone explain the semantics of ISPC's foreach construct? If you were the ISPC compiler, how might you implement foreach? (a.k.a', how might you translate this program with foreach into a valid ISPC program without it?)
This comment was marked helpful 0 times.
@kayvonf: Let me have a try to get it started... from a high level:
Perform a syntax checking. Besides the C-like rules, also making sure that no varying values are assigned to uniform values.
Slice the foreach range into chunks of the vector size, as specified in the --target flag. An extra for loop may be needed for some remaining elements.
In the chunk size for loop, try to make everything to a vector if possible: for array accesses or variables or constants, create vector temporaries storing them and perform the corresponding vector operation. Those temporaries are later allocated to XMM registers or memory locations.
For uniform variables, they should be just allocated to one position to save storage space. That is, uniform variables live among iterations, while varying variables not. This will help register allocation to just allocate a single place for uniform variables.
For conditional statements, mask (just like in the assignment) could be used.
For loops, they should be treated as normal loops, and mask, again, could be used in the condition checking part.
This comment was marked helpful 0 times.
Ah, to clarify the "imagine you were the compiler comment", what I was really asking was: Can you write an ISPC program that has the exact same outcome as the code above, without using foreach? (That is, what's a source-to-source transformation of the code above, to a program without foreach?)
I'm also still looking for someone to describe the semantics of foreach.
This comment was marked helpful 0 times.
When ISPC compiler encounters a foreach, it translates the loop body into two parts. One part is an ordinary for loop with programCount and programIndex. The difference between the ordinary for and this one is the amount of data they process. The data here can fit exactly into the gang, so the implementation won't have inefficient mask operation. The data that can't fit into the gang is handled by the other part, an if statement.
References:
Efficient Iteration With "foreach" - Intel® SPMD Program Compiler Performance Guide
This comment was marked helpful 0 times.



So I am just trying to untangle this in my head. In the program on the right, we have a uniform return value sum, and a regular old float partial. foreach then creates a bunch of instances of the loop, each with its own partial (call them partial0, partial1, ...). When the loop ends, the function reduceAdd looks for all the things called partialx and sums them to make the uniform sum. I think going from having a bunch of partials running around to having one function grab all of them and add them together is confusing to me (and perhaps I'm thinking about it wrongly).
This comment was marked helpful 0 times.

I think the problem is with reduction operation, the parallelization is not that easy such as saxpy(in assignemnt1). So suppose that are 80 elements and 8 wide SIMD, so there should be 10 elements operation for each wide SIMD. In this case, roughly 8 times faster, because each SIMD execution unit is parallelizing work, although there is synchronization for the final step.
This comment was marked helpful 0 times.

@pwei I think what is happening here is that, since sumall2 is an ISPC function, a call to sumall2 will spawn a gang of ISPC program instances (rather than the foreach creating the instances). My guess would be since (in the implementation) each program instance is run on a different execution unit, and each program instance executes the same instruction at the same time, each program instance therefore has its own copy of the variable partial (since partial doesn't have the uniform modifier attached).
The foreach itself I think of as an indication to ISPC that the body of the loop contains code that is safe to run in parallel, and that it is up to ISPC to assign work accordingly, (see slide 14).
As for the reduceAdd, there's actually a neat explanation of this code on the ISPC github that says there's a single call to reduceAdd at the end of the loop. But I imagine the reduceAdd requires some form of communication between the instances to compute the sum, and then it stores result in the location of sum which has one copy across all program instances.
This comment was marked helpful 0 times.

Every program instance is run on the same execution unit. Different threads run on different execution units.
This comment was marked helpful 0 times.

@yihuaz What exactly do you mean by an execution unit? Is it an ALU on a single core? Each program instance maps to 1 vector lane in a SIMD vector so the computation is performed by a single ALU.
This comment was marked helpful 0 times.

I think he means the portion of the core that does the fetch/decode. In ISPC, each program instance runs on a single ALU, but there is only one fetch/decode for all the program instances. Different threads running at the same time, though, will each perform their own fetch/decode and so can run different instructions.
This comment was marked helpful 0 times.

This would be a good slide for someone to explain. How does this program work?
This comment was marked helpful 0 times.

I guess the easier way to understand the code is to look at the ISPC, ISPC was created because the creator was frustrated with the verbose C+AVX intrinsics code after all. Basically, each member of the "gang" has its own value "partial" where it will store its partial sum. For however the load is split amongst the gang (probably is such a way that each gang member has a continuous block of memory to read from), each gang member adds the value at x[i] to its own value of partial. Eventually all the values in the array x will have been added into one of the partial sums. Afterwards, using "reduceAdd", all the partial values from each gang member is reduced into a single sum.
This comment was marked helpful 0 times.
I guess I'll also take a crack at the AVX intrinsics too. So it looks like partial is some vector of 256 bits value, or the equivalent of the size of 8 floats. So in the loop, with _mm256_load_ps(&x[i]), the next 8 values of the array x that have not been looked thus far are loaded into a new vector, the same length as the vector partial. Then, using _mm256_add_ps, the 8 values of partial are updated by adding the corresponding value from the new vector that was just loaded. After the loop, all the values in the array x will have been added into one of the 8 values in the vector partial. Then at the end, each of the 8 values of the vector partial are summed into one cumulative sum.
This comment was marked helpful 0 times.
I am so confused about the
for (int i = 0; i < 8; i++)
sum += partial[i];
part. I think the partial size is 8 because of it is declared as __mm256?
But in that case, _mm256_add_ps seems execute like:
partial[0] = x[0] + x[8] + x[16] + ...
partial[1] = x[1] + x[9] + x[17] + ...
...
partial[7] = x[7] + x[15] + x[23] + ...
But this seems like weird to me...
This comment was marked helpful 0 times.
partial is a vector of eight elements. The i=0;i<8;i++ loop adds up all the elements in the vector.
The question is, what are the values of these eight elements? And given you're post, it looks like you've got it right.
This comment was marked helpful 0 times.
So as I see the description of _mm256_add_ps(__m256 m1, __m256 m2) is
Performs a SIMD addition of eight packed single-precision floating-point elements (float32 elements) in the first source vector, m1, with eight float32 elements in the second source vector, m2.
Therefore I think my guess should be right. partial should load from continuous memory and be added to a vector of eight values.
This comment was marked helpful 0 times.
So in the ISPC program, assuming that we have a round-robin distribution of loop iterations to program instances, and assuming that we are working with SIMD vector width 8, we then have that $partial_i$ refers to the local partial variable of program instance $i$, $0 < i < 7$. Then $partial_i = x[i] + x[i + 8] + x[i + 16] + ...$.
Similarly, we see that in the C+ AVX intrinsics, partial is an 8 wide vector and as @analysiser points out, $partial[i] = x[i] + x[i + 8] + ...$. We can then see a parallel in the way the partial sums are computed in both.
The final for loop in the C+ AVX intrinsics which sums up the elements of the partial vector corresponds to the reduceAdd in the ISPC instance which sums up the results of the local partial variable of each program instance.
This comment was marked helpful 0 times.

Question: We talked about the ISPC gang abstraction in class, but we did not talk about the semantics of the ISPC "task" abstraction in class. Someone explain the semantics of an ISPC task. Then describe one possible implementation of tasks. Better yet, take a look at the code of how tasks are implemented in ISPC and tell actually how it's really implemented... it's right there for you in the assignment 1 starter code in common/tasksys.cpp.
This comment was marked helpful 0 times.

Whereas ISPC "gangs" is a SPMD abstraction, I feel that the ISPC tasks are more of a Multiple Instruction Multiple Data (MIMD) abstraction. From Wiki, MIMD is:
"Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data."
Although there is no description about how the different tasks are run, the lack of a defined order of execution among tasks and the inability to predict when each task is running each instruction in the functions seem to hint that this is the ideal abstraction.
Now onto the implementation. When looking at the tasksys.cpp file, I notices a lot of the contents of the files are determined by the specific system or user input. From the Github project for ISPC:
"Under Windows, a simple task system built on Microsoft's Concurrency Runtime is used (see tasks_concrt.cpp). On OSX, a task system based on Grand Central Dispatch is used (tasks_gcd.cpp), and on Linux, a pthreads-based task system is used (tasks_pthreads.cpp). When using tasks with ispc, no task system is mandated; the user is free to plug in any task system they want, for ease of interoperating with existing task systems."
The underlying system interactions are completely interoperable! Each of the underlying task structures such as TaskGroups, TaskGroupBase, TaskSys all have varying definitions based on the systems that the user uses with the ISPC compiler.
This comment was marked helpful 1 times.

It was stressed that it's important to separate abstraction from implementation. But based on this slide ("a 'task' that is used to achieve multi-core execution"), it seems to me that the gang abstraction has some level of inherent implementation details, considering that you need another abstraction for multi-core execution. As far as I can tell, only the implementation is preventing the single program from running on the other cores, not the abstraction itself.
EDIT: Maybe I misunderstood the slide. It says the task is used to achieve multi-core execution, but after thinking more about @vrkrishn's comment, I think a more accurate phrase would be that the task is used to perform those otter parallel tasks that cannot be run on a single core. Specifically, MIMD tasks.
This comment was marked helpful 0 times.
@tcz: you make some really good points. To dig deeper, read the creator of ISPC's comments about the level of abstraction achieved on slide 7.
ps. I'm still waiting for someone to tell us how ISPC tasks are implemented!
This comment was marked helpful 0 times.
I think the ISPC tasks are created by its own arguments and mapped to pthread to execute. There are limited number of pthreads, such as 4, but there could be many tasks, each like a instances and form a task list. Each pthread would run tasks from the list until the list becomes empty. Tasks managements are written in software, while pthread control is in OS.
This comment was marked helpful 0 times.
@tcz: you're right that it's the implementation that is intentionally not doing multi-core stuff under the covers.
A different design might have said, "given a foreach loop, automatically decompose the loop domain into disjoint regions and run a task to process each region, in turn using SIMD on each core to help with the region loops". This would certainly be handy in some cases, and less work for users who just wanted to fill the processor with computation as easily as possible.
The reason for this design, for what it's worth, is a strong desire for performance transparency. Choosing to run threads and decompose into tasks introduces meaningful overhead in some cases, and in some cases it isn't what the programmer wanted. (Maybe the overhead was enough that there wasn't a speedup, etc.) In general, I wanted to be sure that an experienced programmer reading ispc code could reason effectively about the assembly output the compiler would generate.
Especially for a tool that's intended for good programmers who want to write fast code, I think it's important that the compiler not surprise the programmer in its output. These surprises are inevitable if the compiler is, for example, applying heuristics to decide if a loop is worth turning into tasks--you might add one more term to an addition expression and cross the point from 'no tasks' to 'tasks' and see an unexpected slowdown in your program because the compiler got the heuristic wrong!
Much better, IMHO, for the programmer to be under full control of thissort of thing.
Of course, other languages can be designed with different goals (or more user friendliness :-) ), and their designers may make different decisions.
This comment was marked helpful 0 times.

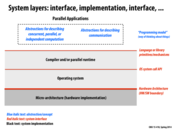


I want to point out that this implementation of the thread abstraction is completely arbitrary.
As an alternative, it is possible to have threads running entirely in user space, which do not communicate with the OS. These types of threads also cannot utilize multiple cores.
This comment was marked helpful 0 times.
@smklein: Good point. This particular slide illustrates only one potential implementation. The implementation of a threading API might be a library that manages threads almost entirely in application space, or a library that leans on the OS to do most of the thread management work. (However, I wouldn't go as far as to say the implementation is "arbitrary", as building it this way would be quite reasonable. ;-))
This comment was marked helpful 0 times.
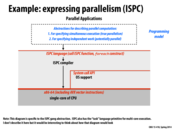
I know it's not described on this slide, but I couldn't find any detailed information about ISPC tasks, besides the fact that they take advantage of multi-core and that ISPC guarantees the function only returns to C/C++ code once all tasks have returned. How would the diagram look for tasks? Would it be any different besides "multi-core" instead of "single-core"?
This comment was marked helpful 0 times.
See if the ISPC task documentation helps you out.
This comment was marked helpful 0 times.


The message passing model reminds of the distributed system implemented in GO. And the key idea is to use the tunnel to share information by communication.
This comment was marked helpful 0 times.

Cool student comments from last year:
post by jpaulson: The following code works, which surprised me: (I expected that I would have to write volatile int x, but I don't, and in fact declaring x as volatile gives warnings).
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void *set(void *var);
void *test(void *var);
int main() {
pthread_t thread1, thread2;
int x = 0;
pthread_create(&thread1;, NULL, set, &x);
pthread_create(&thread2;, NULL, test, &x);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
exit(0);
}
void *set(void *var) {
*(volatile int *)var = 1;
}
void *test(void *var) {
while (!(*(volatile int *)var));
printf("x has been set: %d!\n", *(int *)var);
}
post by sfackler: As noted by Wikipedia, the volatile type class is not appropriate for synchronization between threads:
In C, and consequently C++, the volatile keyword was intended to[1]
- allow access to memory mapped devices
- allow uses of variables between setjmp and longjmp
- allow uses of sig_atomic_t variables in signal handlers.
Operations on volatile variables are not atomic, nor do they establish a proper happens-before relationship for threading.
The use of volatile for thread synchronization happens to work on x86 because that architecture defines an extremely robust memory model (See Intel Developer Manual 3A section 8.2). Other architectures may not ensure that the write to x in the set thread is ever made visible to the thread running test. Processors with relaxed memory models like this do exist. For example, in CUDA
The texture and surface memory is cached (see Device Memory Accesses) and within the same kernel call, the cache is not kept coherent with respect to global memory writes and surface memory writes, so any texture fetch or surface read to an address that has been written to via a global write or a surface write in the same kernel call returns undefined data.
The C11 standard added the stdatomic.h header defining atomic data types and operations. The set and test functions would call atomic_store and atomic_load and the compiler would insert any memory barriers necessary to ensure everything would work on whatever architecture the program is being compiled on. Compilers also usually have atomic builtin functions. GCC's are here.
See also Volatile Considered Harmful for a view from a kernel programmer's perspective.
kayvonf: @sfackler. The issue here is not atomicity of the update to the flag variable x. (Atomicity is ensured in that a store of any 32-bit word is atomic on most systems these days.) The code only requires that the write of the value 1 to x by a processor running the "set" thread ultimately be visible to the processor running the "test" thread that issues loads from that address.
@jpaulson's code should work on any system that provides memory coherence. It may not work on a system that does not ensure memory coherence, since these systems do not guarantee that writes by one processor ultimately become visible to other processors. This is true even if the system only provides relaxed memory consistency. Coherence and consistency are different concepts, and their definition has not yet been discussed in the class. We are about two weeks away.
Use of volatile might no longer be the best programming practice, but if we assume we are running on a system that guarantees memory coherence (as all x86 systems do), the use of volatile in this situation prevents an optimizing compiler from storing the contents of the address *var in a register and replacing loads from *var with accesses to that register. With this optimization, regardless of when the other processor observes that the value in memory is set to one (and a cache coherent system guarantees it ultimately will), the "test" thread never sees this update because it is spinning on a register's value (not the results of the load from *var).
This comment was marked helpful 0 times.
Note that C++11 has built-in language support for acquire and release memory semantics, which let the programmer precisely explain what is desired here. I believe the following code is what one would want in this case:
#include <atomic>
std::atomic<int> x = 0;
// thread 1:
x.store(1, std::memory_order_release);
// thread 2
while (x.load(std::memory_order_acquire) == 0) { }
See also this StackOverflow discussion.
Closely related, Boehm's Threads Cannot Be Implemented As a Library is a great read--highly recommended. It's a great example of many people believing something for many years--that thread parallelism could be retrofitted into C/C++ just via libraries like pthreads--and then a smart guy, Boehm, pointing out perfectly reasonable things compilers might and did do that are completely unsafe in the context of threading.
(It's like we'd all been building suspension bridges for 100 years before someone re-did all the math and figured out that the calculations everyone was using to validate bridge designs were actually totally bogus and we were all just lucky that the bridges were still standing. These observations from him eventually convinced the language standards committees that they had to account for threading directly in their language specs, which has been a good thing in the end..)
This comment was marked helpful 0 times.


On modern systems, typically, how large is the shared address space compared to the size of the private address space?
This comment was marked helpful 0 times.

On Unix-y systems (and I think windows too), an address space belongs to a process, and a process can have multiple threads, so all of those threads belonging to the process can read an write to any valid address in the address space. If one thread can read a location in memory, so can another, if they are in the same process. There is a notion of "private" address space for threads, which is thread local storage (http://en.wikipedia.org/wiki/Thread-local_storage), but I am pretty sure that a thread could accidentally access another thread's local storage, since all of the thread local storage resides within the process's address space.
On an x86 system, the address space is defined by the current page directory, and part of the benefit of threads is that since all the threads share the same address, and thus page directory, switching between threads does not require changing the page directory (and the associated performance hit from having to refill the TLB cache for a new page directory).
It is also possible to have to processes share a part of their address space with each other - e.g. mmap shared regions - I guess this is how you could have truly private address spaces between threads, except that each thread really is a process.
This comment was marked helpful 0 times.


If all threads have different address spaces then wouldn't the processor lose lots of cache locality as it swaps out different threads?
This comment was marked helpful 0 times.

@sss: I think it would lose some, but wouldn't hurt performance too much. We talked about methods that sort of hide this, such as switching to a different thread when waiting on memory accesses upon a cache miss. I'd also suspect that cache updates are done significantly more often than context switches.
This comment was marked helpful 0 times.
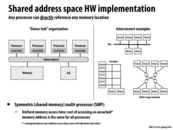
SIMD programming introduces the possibility of running parallel operations on data that is quite close together; in this slide it explains that "caching introduces non-uniform access times". I imagine that caching could potentially be taken advantage of in addition to SIMD programming to lessen runtime, but is there the possibility that caching increases runtime?
This comment was marked helpful 0 times.

I think there are extreme cases when caching can increase running time. When Cache always misses, that is to say, the program does not have locality, then cache cannot provide any speedup. Besides, loading memory into cache also takes time. So the overall running time will increase. But this extreme case almost never exists.
This comment was marked helpful 0 times.
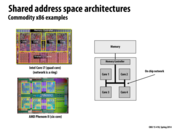
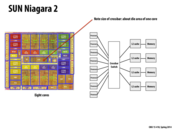
This slide seems to imply that in this class there is no difference between a core and a processor. Is that true? I'm a bit confused, since intel i7 markets itself as a processor, yet has 4 cores...
This comment was marked helpful 0 times.
I think that usually,
a processor is a single piece of silicon, which may have more than one core.
Before the age of multi-core processors, I suppose that core and processor meant the same thing, but now they don't, but sometimes people exchange the two terms.
This comment was marked helpful 0 times.
Cache's inherently point to NUMA Designs but I am just curious to know if there have ever been cache's designed with Uniform Memory Access patterns.
This comment was marked helpful 0 times.

@shabnam I think that NUMA refers to the design of the whole system not necessarily the cache design. Its hard design a system with uniform memory access because of the tradeoffs between the costs of the resources. Caches are typically implemented using SRAM but it would not make sense to use SRAM for the other memory resources since it is quite expensive as compared to DRAM or Disk. With the emergence of new memory technology such as PCM (Phase Change memory) we could see a memory system with a more uniform Memory Access Latency.
This comment was marked helpful 0 times.

@shabnam Well I think the previous slide shows a great example of uniform memory access, since no core has its own local cache, all the accesses would have the same latency. Isn't it what we define as 'uniform'?
This comment was marked helpful 0 times.
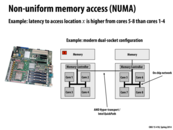

Do operating systems do anything to account for the non-uniform memory access? Specifically in regards to scheduling or to moving threads to a different core to minimize access time.
This comment was marked helpful 0 times.

VMWare explains the dangers and some solutions here: http://pubs.vmware.com/vsphere-4-esx-vcenter/index.jsp?topic=/com.vmware.vsphere.resourcemanagement.doc_40/using_numa_systems_with_esx_esxi/c_what_is_numa.html
The answer is essentially "yes", if the operating system does not employ an intelligent scheduling algorithm, then program performance can vary greatly between runs. Looking around, it seems like there are OSs (specialized for servers) which account for NUMA.
This comment was marked helpful 0 times.

Some interesting stats about the NUMA performance of Blacklight:
Latency to DRAM on the same blade as a processor: ~200 clocks
Latency to DRAM located on another blade: ~1500 clocks
Source: slide 6 of http://staff.psc.edu/blood/XSEDE/Blacklight_PSC.pptx
This comment was marked helpful 0 times.
If having a shared address space is not as desirable in a supercomputer, why does Blacklight implement one?
This comment was marked helpful 0 times.
Good question, and I should definitely clarify my comments. In general, a shared address space is a far more convenient programming abstraction than message passing. The programmer just reads and writes memory, and doesn't need to worry about the details of the memory hierarchy to get to a program that is correct. The problem comes when the programmer begins to think about performance.
To illustrate, consider an extreme example of adopting a shared memory model for writing applications that spanned your smartphone and the cloud. Say your program allocates memory that is required for an image displayed on the phone's UI, and the system happens to make the allocation in memory on Google's servers --- Remember, the system doesn't know what your call to malloc is for, it just chooses a part of the address space and puts the allocation there. Since as a programmer you don't know or care where that allocation is, you are confused by why your program runs so slow --- when the reason is that every frame the UI code accesses the image data, requiring bytes transferred from Google!
The problem is that the abstraction of unified global address space hides all the details of the machine. It tells the programmer, "an address is an address, don't worry about where it's stored, and don't worry about the costs associated with accessing it". But the problem is that the performance differences are so severe in this case, as a programmer you have to know a bit about the implementation to write a useful program. Therefore, a better abstraction would give the programmer mechanisms to at least say "I want an allocation in fast memory for the phone".
In the case of Blacklight, the reason these supercomputers are millions of dollars is that they provide a very high-performance implementation of global shared memory across racks of processors (as compared to, say, if the nodes were connected by Ethernet). This implementation tries to deliver performance that is high enough that it is acceptable to think of all memory being the same. It enlarges the space of programs that scale well without major programmer effort, so really by buying a computer we are paying for the high performance interconnect, and for the programming convenience (shared address space) that having a high performance interconnect provides.
But to squeeze all the performance out of the supercomputer, you will still have to think about data placement, and many programmers conclude that "hey, message passing forces me into a model where I think about communication from the start, so even though it's more work to implement my first correct program (since I have to write all these sends and receives), that program tends to be written very efficiently." In contrast, the shared address space programming model's convenience is also it's drawback: it lets you get a program up and running quickly, but that program may not be written with communication in mind, and thus it might not be very fast.
This comment was marked helpful 2 times.

You mention that performance is the primary downfall of a naively written shared address space program. Doesn't message passing have an implicit overhead associated with constructing the messages that a shared memory model can avoid? (Wikipedia says "In message passing, each of the arguments has to copy the existing argument into a portion of the new message," which is what I'm basing this claim on.) Would a "perfectly" written shared address space program stand to have higher performance than a "perfectly" written message passaging program (without breaking through the abstraction layer of messages)?
This comment was marked helpful 0 times.
@bwasti. Tough question to answer with any level of precision. I guess my best answer is that it depends what machine you are running on. If I'm an architect and don't want to support fast global shared memory, perhaps I put those resources into hardware that accelerates larger messages, or simply more processing cores.
I suppose, given a machine that's highly optimized for shared memory programs, like the one in the picture above, your thinking is reasonable: Given two programs that have the exact same communication pattern, one implemented in terms of loads and stores and the other implemented in terms of a messaging API, then the former would likely be faster because it avoided any overhead associated with the messaging API. Then again, if you wrote both programs to have the same communication pattern, your two programs are essentially the same, and so you can't make much of an argument that one model was more convenient than the other. (which was the initial point: to say that writing shared memory programs was more convenience since you didn't have to use a more rigid message passing structure, and instead get by with a more natural pattern of issuing loads and stores whenever necessary.)
This comment was marked helpful 0 times.

The situation in which I can imagine shared memory being faster is when the latency of access to the memory is extremely low, and there has to be a lot of data shared. I'm imagining a case where multiple cores share a very large cache to which they have fast access, and the multiple threads share data that uses most of the cache and accesses various parts of it often.
It seems to me that message passing is faster in most situations since it forces the programmer to consider latency, which makes a significant difference in high-latency situations (e.g. over a network). Knowing that the message would have to be copied many times, the programmer would avoid sending messages containing tons of data unnecessarily (unlike a shared-memory programmer who might blithely do that).
This comment was marked helpful 1 times.

I've been lucky enough to be able to run a simulation engine on blacklight, and it's remarkable how well the shared memory architecture is abstracted from the programmer. I was able to allocate over 100 Gb of RAM during one simulation, and until now I never even knew that RAM latency was dependent on the physical location of the memory. For programmers who have a project that runs on commodity hardware and need to run a few very large instances of their program without changing the code, blacklight is amazing.
This comment was marked helpful 0 times.

A fat tree is similar to a tree, but unlike the standard trees that you may be used to, a fat tree has 'thicker' links between nodes as you get closer to the root. In terms of bandwidth, this allows the root node to handle incoming data from all of its leaves, whereas each leaf only sends its own data to its parent.
This comment was marked helpful 0 times.
@bwasti I was poking around the SGI UV1000 sales materials, and apparently each blade has an MPI co-processor, so that the work of creating/recieving messages is offloaded from the processor! (I was really impressed)
This comment was marked helpful 0 times.




Supercomputers often only support a message passing parallel programming model. This is because they are composed of many racks of blade chips. Thus, a shared address space model would be inappropriate, because processors are often physically separated by several meters rather than several millimeters of space, and thus cannot effectively share an address space. Message passing is a much more effective way of communicating between processes, by only sending information when needed rather than sharing memory by default.
This comment was marked helpful 0 times.
The motivation of message passing in this content is not that it is impossible to implement a shared address space abstraction, it's that the abstraction would not be particularly helpful to a programmer wanting to program this machine.
The point of an abstraction is to hide implementation details. In the case of shader memory, the abstraction presents a single address space to the programmer, so the programmer doesn't need to think about where data lies in the machine to write a correct program. The problem is that in this large of a machine a load might take a few cycles, or it might take tens of thousands of cycles (or maybe even millions), depending on what address is accessed. As a programmer writing a supercomputing application, you care about performance (why else use a supercomputer?!?!), so since data placement is so critical to performance, you almost certainly would want to write code that took data placement into account. At that point the shared memory abstraction's main benefit (not having to think about data placement) is not very helpful to you! Message passing is can be useful in this context since it makes communication explicit in the program. In a shared address space model you would just see a memory load in code, and then to determine if it was an expensive one, you'd have to reason about what the address might be and where in the machine that might be.
Good abstractions hide the details programmers don't want to care about, and hide details that are better left to the compiler/runtime system/OS/hardware to manage.
This is a critical point, and one that will keep coming up in the class.
p.s. I say more on the merits of the shared memory abstraction here.
This comment was marked helpful 3 times.


What are the benefits/main uses of message passing abstractions when the hardware is shared address?
This comment was marked helpful 0 times.

I'll take a crack at this...
I believe there are cases in which the message passing paradigm is a more natural fit for expressing an algorithm (in particular, Distributed Algorithms - http://en.wikipedia.org/wiki/Distributed_algorithm).
For example, consider the "program" from the first day of class where each processor has a number, and we wanted to sum them all up. The standard shared-memory solution would be to have a global sum variable, and then have all of the processors lock the variable, add their element, and then unlock the variable. However, a message passing solution could easily express the 210 "reduce" algorithm or the "row-by-row" algorithm, which has a lower time complexity.
Here's an article which tries to answer, "Is message passing obsolete?" (it answers 'no') - http://www-users.cs.umn.edu/~kumar/papers/passing.ps. The main points the article makes are that message passing is useful because it enables programmers to account for access conflicts, to optimize data movement between processors, and to conceptualize parallel programmers in a different--and often more natural--way.
This comment was marked helpful 0 times.


I was lost in this last part of today's lecture. What has data-parallel model to do with communication? what does 'map' stand for?
This comment was marked helpful 0 times.
This slide refers to the higher order function map. map(f, C) applies the function f to each element of the collection C.
You may wish to refer to http://en.wikipedia.org/wiki/Map_(higher-order_function) or your 15-210 notes.
This comment was marked helpful 0 times.

I find this a very interesting thought. I'm very much into functional programming, but I've never ever ever thought of how the functional paradigm maps to the actual computer hardware (it's so high level, unlike C, that it has never made sense to me to think about it). I wonder how would the mapping to threads/cores be like with such functional languages? (Maybe not SML since SMLNJ is not parallel).
This comment was marked helpful 0 times.
A great final project in this class, if someone was super-ambitious and has compilers experience, would be to attempt a parallel implementation of some small subset of ML.
You also might want to take a peak at parallel Haskell. But in my opinion Haskell's lazy evaluation makes it a nightmare for reasoning about performance.
This comment was marked helpful 1 times.

Question: looking back, I'm a bit confused why the data-parallel programming model is proposed as one in the same class as the message passing and shared memory models. It appears that message passing and shared memory define how we let processors operate on the same data, but do not affect the actual algorithms themselves (e.g. you could change the abstraction implemented under the OpenMPI API to use a shared memory space and achieve an equivalent parallel sort in assignment 3).
The data-parallel programming model, however, defines how we structure and operate on the data used in our parallel algorithms. As mentioned in later slides, we have to think of the input as a stream and operate on it as such. However, the fact that our input is represented as a stream can operate under either the message passing or shared memory paradigms. Why exactly do we call it one of three parallel programming models, then?
This comment was marked helpful 1 times.
Good points @wcrichto. I think the best way to answer your question is that a program model and it's associated abstractions encourage the programmer to think about their program in a certain way, or to structure it in a certain form. I agree with you that data-parallelism is a much more rigid structure than the other two. With the massing passing model being a more rigid structure than the shared memory model. In general, the more structure a programming model encourages/enforces on programs, the more limited the space of applications that can easily be expressed in it. However, more structure also means that the system (compiler, hardware, etc.) typically can do more for the programmer, such as how in the data parallel model parallelization and scheduling decisions are largely handled by the system, not the application.
In the limit are domain-specific programming models that give up generality for very efficient implementations of a smaller class of programs.
This comment was marked helpful 0 times.



Question: Why is this program non-deterministic?
This comment was marked helpful 0 times.

There is no guarantee on the order in which program instances operating with different will be executed. As a simple example, consider a call to the function shift_negative where N = 4 and x = [-1.0, 3.5, -2.0, 4.2]. Suppose that the SIMD width of the chip is such that a gang consists of four program instances.
Consider the final value of y[1]. The following program instances will be working on that output element:
a) Program instance with i = 1. This instance will try to write 3.5 at y[1] (as it will enter the else case; 3.5 >= 0).
b) Program instance with i = 2. This instance will try to write -2.0 at y[2-1] = y[1] (as it will enter the if case; -2.0 < 0).
Hence, depending on which program instance gets executed first, the result may differ.
This comment was marked helpful 1 times.
I am still confused. Shouldn't the program be deterministic, looking at the discussion on slide 7(of the same lecture)?
"ISPC guarantees that program instances synchronize after each program sequence point, which is roughly after each statement."
In other words, the else branch should always be executed after the if branches?
This comment was marked helpful 0 times.
@eatnow I'm not a 100% sure about this but since we are using the foreach construct, we are simply telling the ISPC compiler that the iterations of the loop is in parallel. We have no knowledge as to how the iterations of the loop are assigned to program instances by the ISPC compiler (although we generally tended towards round-robin earlier in the lectures). As such, while the program instances are synchronized after every step - due to implementation with SIMD - we don't know which loop iterations the program instances which are running, correspond to. Thus it is possible for the program to be non-deterministic.
Someone please correct me if I'm wrong. My reasoning seems to vastly different from @arjunh since I'm citing the foreach construct and our lack of knowledge about its implementation rather than the fact that program instances might finish at different times.
Edit: I believe that if we explicitly implemented the round-robin allocation of loop iterations to the program instances - or even the chunk size allocation method for that matter - then this program will be deterministic since as @eatnow points out, the else branch will always be executed after the if branch.
This comment was marked helpful 0 times.

Are there any relation between term kernel presented here and the term Kernel for an operating systems?
This comment was marked helpful 0 times.
No, they are different concepts. Here a kernel refers to the side-effect-free function that is mapped onto the collection.
Stream programming systems sometimes refer to the function as a kernel ("computation kernel") and the collection as a stream.
This comment was marked helpful 0 times.

How does a compiler know to feed elements that pass through foo directly to bar? Is it just because the output for foo and input for bar are the same stream? Would adding lines of code between foo and bar affect this optimization?
This comment was marked helpful 1 times.
Yes, the idea is that a stream programming language compiler is fully aware of the computation DAG. It knows foo produces tmp. And tmp is consumed by bar. It also might be able to realize that bar is not ever used again. Since this "structure" is known---as conveyed by the stream programming abstractions, the compiler could attempt to generate an optimized implementation, perhaps by scheduling the computation such that...
Question: How might the compiler use knowledge of the structure of a stream program in mapping it efficiently to the Quad-core CPUs in GHC 5205?
This comment was marked helpful 0 times.
If the compiler knows that two consecutive function calls will be operating on essentially the same stream, I could see an optimization on minimizing accesses to memory where the same regions of memory are operated on by the same processors in the course of running foo and bar.
I guess it's basically an extension of producer-consumer locality across multiple cores, but you just ensure that each core doesn't have to write its share of the input stream back to memory before running bar on the same set of data.
Is there really anything else significant from the structure of a stream program? It seems like between the innate parallelism of streams (independent data sets) and the ability to break up streams across multiple cores constitutes the majority of the benefits.
This comment was marked helpful 0 times.

I'd be very interested to hear the class' thoughts on this one. ;-)
This comment was marked helpful 0 times.

In my opinion, data-parallel is more abstract than previous two model. It means compiler takes charge of more work from programmer, so I think it's more efficient when compiler are smart enough to handle codes, such as prefetch in previous example. Or data is independent from each other, map can be done easily. However, if data dependency is not so clear, then we have to do it manually. At this time, former two model can let programmer control more.
This comment was marked helpful 0 times.

I'm confused about this slide. The point is that y[2*i+1] = y[2*i] = result isn't valid ISPC code, right? I'm also not entirely sure what either program is attempting to achieve.
This comment was marked helpful 0 times.

@Dave y[2*i+1] = y[2*i] = result; is equivalent to: y[2*i+1] = result; y[2*i] = result;. The drawback is not in the ISPC code, it is in the data-parallel/stream program above.
My understanding of this slide is the following. ISPC syntax allows you to describe data parallel operations element-wise. While in stream programming syntax, you describe operations on streams of data. There is no problem if your program operates on a very regular stream (everything is in form of x[i], y[i], ...). However if your program involves some irregular stream such as y[2*i+1], y[x[3*i]], ... you will need a library of ad-hoc operators. If you are unlucky that the library does not contain the function you want (imagine you don't have stream_repeat in your library), you will have to implement this function in the library. And Kayvon's experience tells us this situation happens all the time with stream programming models.
This comment was marked helpful 1 times.

I liked how during lecture Kayvon described ISPC as allowing the programmer to shoot themselves in the foot. Because that is the same way I describe C. I am of the opinion that if one wants to write high performance code, then relying on the compiler to generate the "best" output is not good enough. The convenience of having safety and built-in operations for more regular functions is nice, but having more control, at the cost at having to implement more by hand, seems to be more useful in the long run.
This comment was marked helpful 0 times.

I can definitely see where languages like ISPC would be more useful (when you want more specific control, the compiler won't generate efficient enough code, etc.) and when stream programming would be more useful (the compiler would probably make good choices, there is a lot of complication in preventing race conditions, etc.). And I agree that when you get to the point where you are writing parallel code on a lot of data, the extra performance you might be able to get from ISPC would be worth it. However, I think stream programming is useful especially when starting to learn about parallel code, because it abstracts away a lot of the more complicated things, and it also helps you form an intuition about parallelism. I'm sure this isn't true for everyone, but for me I think it was really useful to have taken 150 and 210 before this so I could understand parallelism better before really getting into the details.
This comment was marked helpful 0 times.

So an example really helped me out here. If you have your input be [1.2, 0.2, 4.1, 3.5], and your indices be [1,3,0,2], then I believe gather would result with an output of [0.2, 3.5, 1.2, 4.1], and scatter would result with [4.1, 1.2, 3.5, 0.2].
So in my mind gather takes the set of indices and says, okay at index i I want the input element from indices[i], whereas scatter would say take the input from index i and put it in the output at index indices[i]. (now that I write this, I realize it's probably not much better than the code... but the example might help!)
This comment was marked helpful 3 times.
Question: Another way to understand gather and scatter is for someone to want to write sequential C-code for:
void gather(float* src, int* indices, float* dst);
void scatter(float* src, int* indices, float* dst);
This comment was marked helpful 0 times.
I'll give it a go! Assuming they all have equal length N
void gather(float* src, int* indices, float* dst) {
for (int i = 0; i < N; i++) {
dst[i] = src[indices[i]];
}
}
void scatter(float* src, int* indices, float* dst) {
for (int i = 0; i < N; i++) {
dst[indices[i]] = src[i];
}
}
This comment was marked helpful 1 times.
Each of these programs seems to use only one of either gather or scatter. Is there an example that would use both operations?
This comment was marked helpful 0 times.



We've spent plenty of time working with functional syntax in 150/210, so I think it's pretty familiar to most of us. I've also found that functional's relative lack of flexibility is sometimes helpful in coming up with a solid solution to a problem. Would it be possible/advisable to have a language that has options for both imperative and functional syntax?
This comment was marked helpful 0 times.
There are many languages that have options for both imperative and functional syntax. Off the top of my head, Python was built to be multi-paradigm, Javascript is inherently functional, and even C++ can be functional. Of course, I don't think its advisable to in most cases, with the exception of explicitly multi-paradigm languages, but it is certainly doable in many languages.
This comment was marked helpful 0 times.


I think it's worth pointing out that these programming models are not mutually exclusive and many programs make use of two or more. For example, a distributed map/reduce cluster could use a distributed file system to share data between instances. A master machine could use message passing to tell each compute instance what to do, and they in turn could use multiple threads and/or SIMD to process data parallel data with a shared address space. They would then pass messages back to the master to indicate completion, failure, etc.
This comment was marked helpful 0 times.

It seems like the three explained here are not necessarily different in a way that it is possible to mimic the behavior of one in form of the other. For instance, if the MPI is only used the gather up the separate data, then it would be similar to having a case of shared address space where there is no need to worry about different threads accessing the same data (such as thread i only access sharedData[i]).
This comment was marked helpful 0 times.


Some more info on Roadrunner, if anyone's interested. It was the first supercomputer to hit a petaflop (compare with 54 petaflop peak of today's fastest supercomputer) but went out of commission last March. Those IBM Cell CPUs are fancier versions of the Cell processors from the PlayStation 3.
This comment was marked helpful 0 times.

Currently, the world's fastest supercomputer is the Tianhe-2 from China's National University of Defense Technology. It is said to have a peak performance of 54.9 PFlops and has neo-heterogeneous nodes, which means there is more flexibility and efficiency for developers. There is a presentation from the university on Tianhe-2 here.
This comment was marked helpful 3 times.

Question: I used the term "abstraction distance" in this summary without ever defining it in the lecture. What do you think I meant here? (note: my comment on slide 35 is relevant)
This comment was marked helpful 0 times.

I understand this as how strongly associated the top-level programming language/library and the hardware instruction architecture are, how closely they reflect each other, or how many details of hardware implementation are hidden by the programming language (the 'abstraction'). The SIMD vector intrinsics we work with in Program 2 (if they really did translate into vector instructions for the CPU) are thus an example of really low abstraction distance, while a functional language like SML is an example of high abstraction distance. Because the logic we use to develop programs and algorithms usually doesn't involve thinking in terms of hardware loads/stores and bit-wise operations, a high abstraction distance can allow for a more intuitive programming model; but makes it difficult to have fine-grained control over performance at the hardware level since those details are often hidden.
This comment was marked helpful 0 times.

Applying the term abstraction distance to this lecture, ISPC tasks definitely have a greater abstraction distance than Pthreads. With Pthreads, the programmer has finer control over targeting each thread to complete a specific task, so much of the abstraction is taken away. However with ISPC tasks, the programmer has the actual functionality hidden from view through the layer of abstraction that is the gang of instances, which decide themselves how to complete a task without programmer input.
This comment was marked helpful 0 times.

I think "abstraction distance" is a measurement of how much work it takes to go from the abstraction to the actual implementation. So for example C would have a low abstraction distance compared to other higher level languages. The slide is mentioning that an abstraction should shoot for the right amount of abstraction distance. Too much would mean that programs become unpredictable, and too little would mean that the abstraction becomes inflexible.
This comment was marked helpful 0 times.
Question: Knowing what you know now, why do you think I make such a big deal about knowing when one is talking about a system's abstractions (and their semantics), and when one is talking about a system's implementation?
This comment was marked helpful 0 times.
I think kayvonf answered this at lecture 3, slide 35, his own comment. "the abstraction would not be particularly helpful to a programmer wanting to program this machine".
This comment was marked helpful 0 times.
I think learning an abstraction can help you reason about the correctness of a certain program but it can't necessarily address matters of efficiency whereas knowing precisely how an abstraction is implemented can lend to writing efficient code. A good example of this is the interleaved vs chunked memory accesses among ISPC instances. From the abstraction's point of view these are identical, they will result in the same output, but from an implementation point of view interleaved memory accesses will result in much higher performance. Understanding the abstraction can help you apply skills from a particular architecture across many different architectures but understanding the implementation can help you apply skills to a particular architecture efficiently. It is important to understand the difference because if you confuse the two, what may be efficient on one architecture is ridiculously inefficient on another.
This comment was marked helpful 2 times.
Difference of concurrency and parallelism also illustrates the idea of abstraction and implementation. Abstraction is from the software's perspective of view while implementation talks about hardware.
This comment was marked helpful 0 times.
I think that it is important to stress that the abstraction is different than the implementation because they are actually describing an algorithm/structure on different levels. For example, while the ISPC "foreach" abstraction launches a so-called 'gang' of instances, we don't necessarily know that this is implemented as vector instructions with vector lanes until we get into the implementation. The idea is that the implementation could change without changing the abstraction, thus maintaining the same interface for the user and not rendering previously written code invalid.
This comment was marked helpful 0 times.
@yrkumar, you are correct in your comments about the difference between abstraction and implementation, but I believe you have mischaracterized the semantics of the
foreachconstruct. Care to make an update? Hint.This comment was marked helpful 0 times.
Going off of Kayvon's post in the other slide, the
foreachconstruct is just there to tell the compiler that any of these iterations can be done in parallel. However,foreachdoesn't actually launch any parallel iterations. Instead, it just lets the compiler divide up the various iterations among the different threads which are already working in parallel. Thus, there are no guarantees about how or where each iteration will be executed, but that shouldn't matter because we already claimed that the order of these iterations didn't matter by designating the loop aforeachloop.This comment was marked helpful 1 times.
@TheRandomOne: very well said.
This comment was marked helpful 0 times.