post by jpaulson: The following code works, which surprised me: (I expected that I would have to write volatile int x, but I don't, and in fact declaring x as volatile gives warnings).
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void *set(void *var);
void *test(void *var);
int main() {
pthread_t thread1, thread2;
int x = 0;
pthread_create(&thread1;, NULL, set, &x);
pthread_create(&thread2;, NULL, test, &x);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
exit(0);
}
void *set(void *var) {
*(volatile int *)var = 1;
}
void *test(void *var) {
while (!(*(volatile int *)var));
printf("x has been set: %d!\n", *(int *)var);
}
post by sfackler: As noted by Wikipedia, the volatile type class is not appropriate for synchronization between threads:
In C, and consequently C++, the volatile keyword was intended to[1]
allow access to memory mapped devices
allow uses of variables between setjmp and longjmp
allow uses of sig_atomic_t variables in signal handlers.
Operations on volatile variables are not atomic, nor do they establish a proper happens-before relationship for threading.
The use of volatile for thread synchronization happens to work on x86 because that architecture defines an extremely robust memory model (See Intel Developer Manual 3A section 8.2). Other architectures may not ensure that the write to x in the set thread is ever made visible to the thread running test. Processors with relaxed memory models like this do exist. For example, in CUDA
The texture and surface memory is cached (see Device Memory Accesses) and within the same kernel call, the cache is not kept coherent with respect to global memory writes and surface memory writes, so any texture fetch or surface read to an address that has been written to via a global write or a surface write in the same kernel call returns undefined data.
The C11 standard added the stdatomic.h header defining atomic data types and operations. The set and test functions would call atomic_store and atomic_load and the compiler would insert any memory barriers necessary to ensure everything would work on whatever architecture the program is being compiled on. Compilers also usually have atomic builtin functions. GCC's are here.
kayvonf: @sfackler. The issue here is not atomicity of the update to the flag variable x. (Atomicity is ensured in that a store of any 32-bit word is atomic on most systems these days.) The code only requires that the write of the value 1 to x by a processor running the "set" thread ultimately be visible to the processor running the "test" thread that issues loads from that address.
@jpaulson's code should work on any system that provides memory coherence. It may not work on a system that does not ensure memory coherence, since these systems do not guarantee that writes by one processor ultimately become visible to other processors. This is true even if the system only provides relaxed memory consistency. Coherence and consistency are different concepts, and their definition has not yet been discussed in the class. We are about two weeks away.
Use of volatile might no longer be the best programming practice, but if we assume we are running on a system that guarantees memory coherence (as all x86 systems do), the use of volatile in this situation prevents an optimizing compiler from storing the contents of the address *var in a register and replacing loads from *var with accesses to that register. With this optimization, regardless of when the other processor observes that the value in memory is set to one (and a cache coherent system guarantees it ultimately will), the "test" thread never sees this update because it is spinning on a register's value (not the results of the load from *var).
This comment was marked helpful 0 times.
mmp
Note that C++11 has built-in language support for acquire and release memory semantics, which let the programmer precisely explain what is desired here. I believe the following code is what one would want in this case:
#include <atomic>
std::atomic<int> x = 0;
// thread 1:
x.store(1, std::memory_order_release);
// thread 2
while (x.load(std::memory_order_acquire) == 0) { }
Closely related, Boehm's Threads Cannot Be Implemented As a Library is a great read--highly recommended. It's a great example of many people believing something for many years--that thread parallelism could be retrofitted into C/C++ just via libraries like pthreads--and then a smart guy, Boehm, pointing out perfectly reasonable things compilers might and did do that are completely unsafe in the context of threading.
(It's like we'd all been building suspension bridges for 100 years before someone re-did all the math and figured out that the calculations everyone was using to validate bridge designs were actually totally bogus and we were all just lucky that the bridges were still standing. These observations from him eventually convinced the language standards committees that they had to account for threading directly in their language specs, which has been a good thing in the end..)
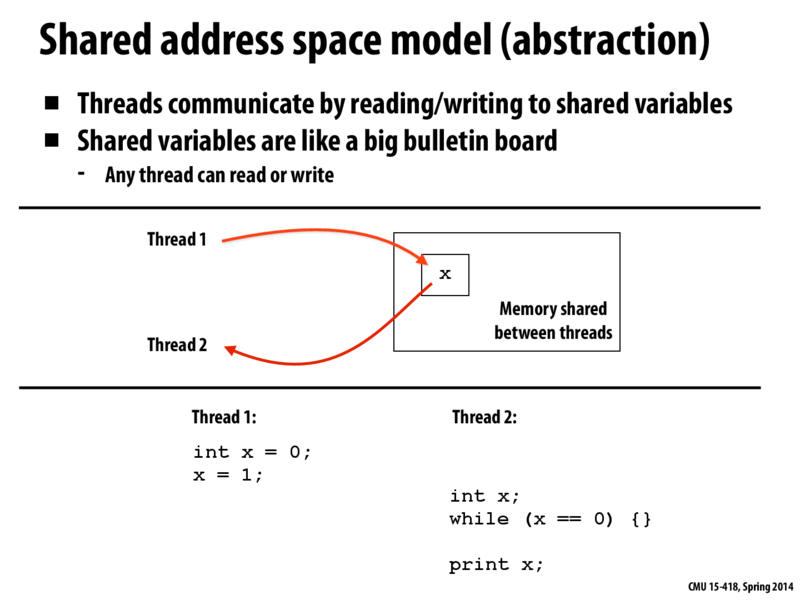
Cool student comments from last year:
post by jpaulson: The following code works, which surprised me: (I expected that I would have to write
volatile int x, but I don't, and in fact declaringxas volatile gives warnings).post by sfackler: As noted by Wikipedia, the
volatiletype class is not appropriate for synchronization between threads:The use of
volatilefor thread synchronization happens to work on x86 because that architecture defines an extremely robust memory model (See Intel Developer Manual 3A section 8.2). Other architectures may not ensure that the write toxin thesetthread is ever made visible to the thread runningtest. Processors with relaxed memory models like this do exist. For example, in CUDACUDA C Programming Guide
The C11 standard added the
stdatomic.hheader defining atomic data types and operations. Thesetandtestfunctions would callatomic_storeandatomic_loadand the compiler would insert any memory barriers necessary to ensure everything would work on whatever architecture the program is being compiled on. Compilers also usually have atomic builtin functions. GCC's are here.See also Volatile Considered Harmful for a view from a kernel programmer's perspective.
kayvonf: @sfackler. The issue here is not atomicity of the update to the flag variable
x. (Atomicity is ensured in that a store of any 32-bit word is atomic on most systems these days.) The code only requires that the write of the value 1 toxby a processor running the "set" thread ultimately be visible to the processor running the "test" thread that issues loads from that address.@jpaulson's code should work on any system that provides memory coherence. It may not work on a system that does not ensure memory coherence, since these systems do not guarantee that writes by one processor ultimately become visible to other processors. This is true even if the system only provides relaxed memory consistency. Coherence and consistency are different concepts, and their definition has not yet been discussed in the class. We are about two weeks away.
Use of
volatilemight no longer be the best programming practice, but if we assume we are running on a system that guarantees memory coherence (as all x86 systems do), the use ofvolatilein this situation prevents an optimizing compiler from storing the contents of the address*varin a register and replacing loads from*varwith accesses to that register. With this optimization, regardless of when the other processor observes that the value in memory is set to one (and a cache coherent system guarantees it ultimately will), the "test" thread never sees this update because it is spinning on a register's value (not the results of the load from*var).This comment was marked helpful 0 times.
Note that C++11 has built-in language support for acquire and release memory semantics, which let the programmer precisely explain what is desired here. I believe the following code is what one would want in this case:
See also this StackOverflow discussion.
Closely related, Boehm's Threads Cannot Be Implemented As a Library is a great read--highly recommended. It's a great example of many people believing something for many years--that thread parallelism could be retrofitted into C/C++ just via libraries like pthreads--and then a smart guy, Boehm, pointing out perfectly reasonable things compilers might and did do that are completely unsafe in the context of threading.
(It's like we'd all been building suspension bridges for 100 years before someone re-did all the math and figured out that the calculations everyone was using to validate bridge designs were actually totally bogus and we were all just lucky that the bridges were still standing. These observations from him eventually convinced the language standards committees that they had to account for threading directly in their language specs, which has been a good thing in the end..)
This comment was marked helpful 0 times.