Another interesting queueing problem that can be mitigated with this strategy is the department store checkout queue or telephone operator queue. In the sense of work, each customer waiting brings an independent but potentially different amount of work. And by using a single queue for the system, whenever any operator or clerk gets blocked by a large amount of work, other operators or clerk can still receive work that may have been allocated to that blocked operator in a multi queue system.
This comment was marked helpful 0 times.
uhkiv
As I understand it, ISPC implements the foreach construct by SIMD. Hence, work cannot be assigned dynamically to individual instances. However, it may be possible to achieve dynamic assignment with tasks. For example, with the prime example, we can launch N tasks that only works one number, and when that task is finished, ISPC will schedule another task on the CPU (can someone elaborate?).
On the other hand, CUDA already has a way to achieve dynamic assignment with blocks. When a block finishes, CUDA pulls out another block, and reuses context of the finished block to execute the new one.
This comment was marked helpful 0 times.
rokhinip
I believe ISPC actually uses dynamic assignment to assign workers/pthreads to tasks. When you specify the number of tasks to launch in ISPC, you are specifying the granularity of each task aka the chunk of work to be executed by each worker.
This comment was marked helpful 0 times.
elemental03
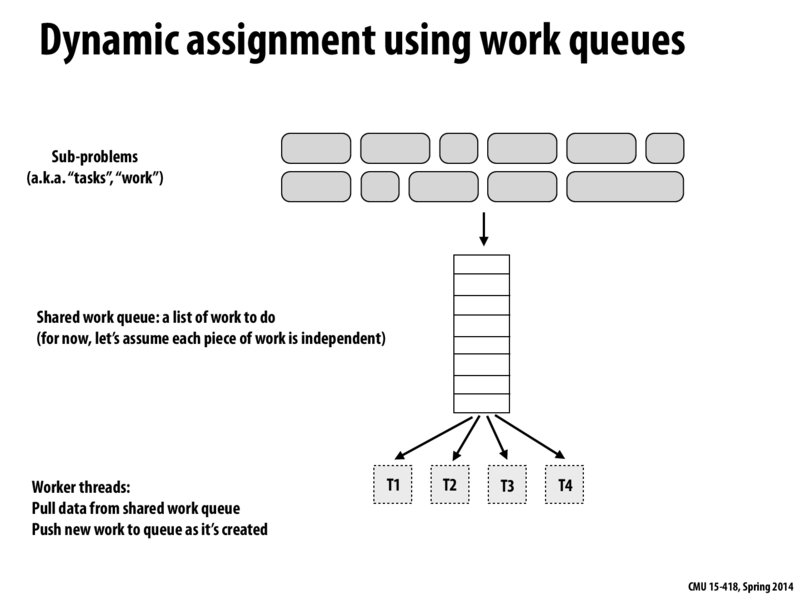
Is the queue just a FIFO queue? How does this help to balance the workload across threads then?
For example, we have tasks 1 through 8, and 4 threads, p1 to p4. The best balance happens when 1,2 go to p1, 3,4 go to p2, 5,6 go to p3, and 7,8 go to p4. In this case, if the queue was a FIFO queue, at runtime, the program would have to send 1,3,5,7,2,4,6,8 to the queue in order to balance workloads in a equal manner.
Does the program calculate all this before placing tasks into the queue, or do threads just pull tasks from the queue according to how much more work they need to become balanced with the other threads?
Another interesting queueing problem that can be mitigated with this strategy is the department store checkout queue or telephone operator queue. In the sense of work, each customer waiting brings an independent but potentially different amount of work. And by using a single queue for the system, whenever any operator or clerk gets blocked by a large amount of work, other operators or clerk can still receive work that may have been allocated to that blocked operator in a multi queue system.
This comment was marked helpful 0 times.
As I understand it, ISPC implements the
foreachconstruct by SIMD. Hence, work cannot be assigned dynamically to individual instances. However, it may be possible to achieve dynamic assignment with tasks. For example, with the prime example, we can launch N tasks that only works one number, and when that task is finished, ISPC will schedule another task on the CPU (can someone elaborate?).On the other hand, CUDA already has a way to achieve dynamic assignment with blocks. When a block finishes, CUDA pulls out another block, and reuses context of the finished block to execute the new one.
This comment was marked helpful 0 times.
I believe ISPC actually uses dynamic assignment to assign workers/pthreads to tasks. When you specify the number of tasks to launch in ISPC, you are specifying the granularity of each task aka the chunk of work to be executed by each worker.
This comment was marked helpful 0 times.
Is the queue just a FIFO queue? How does this help to balance the workload across threads then?
For example, we have tasks 1 through 8, and 4 threads, p1 to p4. The best balance happens when 1,2 go to p1, 3,4 go to p2, 5,6 go to p3, and 7,8 go to p4. In this case, if the queue was a FIFO queue, at runtime, the program would have to send 1,3,5,7,2,4,6,8 to the queue in order to balance workloads in a equal manner.
Does the program calculate all this before placing tasks into the queue, or do threads just pull tasks from the queue according to how much more work they need to become balanced with the other threads?
This comment was marked helpful 0 times.