It might be interesting to note that one optimization to the classic RISC pipeline is to forward data from later stages to minimize stalls. In the classic pipeline here, it is not until the writeback stage that the decode stage can get the latest data from computation. So one way to decrease the stall that might happen is to forward data straight from the ALU in the execute stage, to the decode stage.
This comment was marked helpful 0 times.
kayvonf
Question: Let's say the "execute" phase of the above pipeline took significantly longer than the other pipeline stages. What might you consider to speed up the pipeline's execution?
This comment was marked helpful 0 times.
retterermoore
Maybe you could build some sort of specialized hardware that was optimized for the execute phase (if this was a frequently used enough construction that that was worth the money/effort), and then have a dedicated thread just running the execute phase while the others cycle through the other phases.
This comment was marked helpful 0 times.
benchoi
We could speed up the pipeline's execution by having multiple ALUs. That way we could fetch and decode more instructions and write back more data while waiting for one execution to complete, ensuring that the other resources are always kept busy.
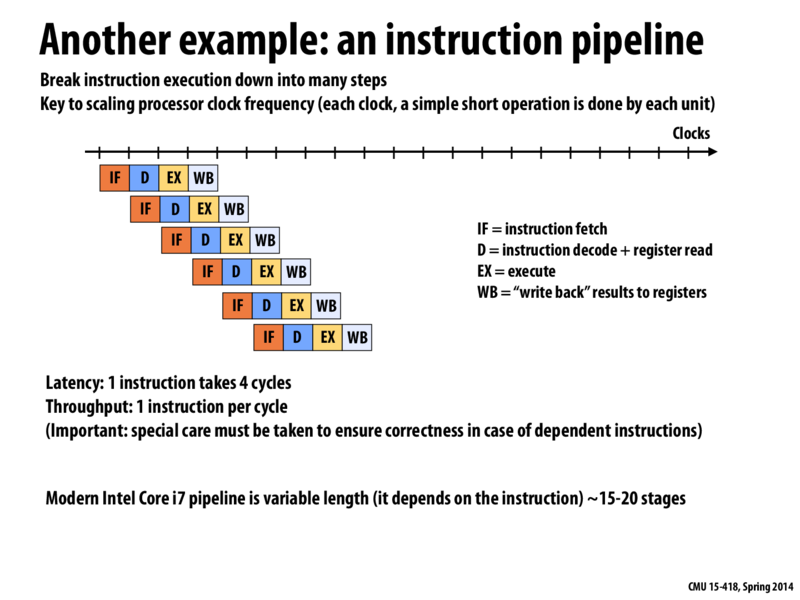
It might be interesting to note that one optimization to the classic RISC pipeline is to forward data from later stages to minimize stalls. In the classic pipeline here, it is not until the writeback stage that the decode stage can get the latest data from computation. So one way to decrease the stall that might happen is to forward data straight from the ALU in the execute stage, to the decode stage.
This comment was marked helpful 0 times.
Question: Let's say the "execute" phase of the above pipeline took significantly longer than the other pipeline stages. What might you consider to speed up the pipeline's execution?
This comment was marked helpful 0 times.
Maybe you could build some sort of specialized hardware that was optimized for the execute phase (if this was a frequently used enough construction that that was worth the money/effort), and then have a dedicated thread just running the execute phase while the others cycle through the other phases.
This comment was marked helpful 0 times.
We could speed up the pipeline's execution by having multiple ALUs. That way we could fetch and decode more instructions and write back more data while waiting for one execution to complete, ensuring that the other resources are always kept busy.
This comment was marked helpful 0 times.