In lecture, after the contention demo it was asked how we might solve the problem of multiple requests contending for the same resource, specifically without changing our set of resources. The accepted suggestion was to stagger our requests--let R1 get sent out, wait a bit, then send R2, and so on.
This doesn't really solve anything, though, right? Holistically speaking, we're still spending just as much time as if all the requests waited for the resource simultaneously. Staggering gives each individual request the illusion that it got instant access to the resource, but no time was saved overall.
What kind of use cases exist for this kind of solution which solves the problem on a request level but doesn't reduce our overall time spent?
This comment was marked helpful 0 times.
retterermoore
Maybe if there was some other work that each person needed to do, then the second person could start on that work during the staggering time (like if each person both needs to walk to Kayvon, shake hands, and come back AND read a few pages of some book, then person A could start walking while person B reads at first and then later starts walking - this would make the total time spent for both people to complete their operations less, much like the laundry example).
I definitely agree that it won't give any benefit in this specific case though, if there's nothing for the people to do while waiting to be sent to Kayvon.
This comment was marked helpful 0 times.
mchoquet
Also, the students in our in-class demo were very well-behaved and waited their turns without having to settle who got to shake hands when. There are some lock implementations for which the work of arranging who gets access to the resource in what order is non-constant with respect to the number of waiting people, and can in fact get quite large. In such a situation, the sum latency across all the requests would be worse if they arrived at once than if each arrived just as the previous one was done. My understanding is that this sort of thing will become particularly important once we start talking about cache coherence.
This comment was marked helpful 0 times.
mchoquet
Possible situation 2: the number of requests coming in is very very very high (say you're Google, for example, and updating some sort of global info every time a query comes in). Now, suppose our locking scheme is perfect so the problem I posed above isn't an issue; you might still encounter slowdowns because storing a large number of requests waiting on a lock takes space, and could easily grow your working set until it overflows your cache. If that's allowed to happen, then either your server must be overprovisioned so that it can still handle requests fast enough (which is expensive), or users could start to experience high latency spikes. Making the stream of requests more regular by stalling some of them would make the behavior of the server more predictable.
The author ends the post with some of the following unanswered questions:
Why doesn't the use of non-temporal instructions double bandwidth for the single core programs? It only went up 50%.
Why aren't the AVX instructions on one core able to saturate the bandwidth ?
These problems are focusing on why full memory bandwidth was not achieved using a single core, even using SIMD execution and non-temporal instructions (doesnt save to cache). Could the reason for this underutilization be because of contention?
When the same code is run on multiple cores, suddenly the theoretical max bandwidth was achieved. Contention here makes sense since a single core would not be able to handle that much memory at once (or rather would be slowed by contention), while multiple cores would not face this problem (or face this problem to a lesser extent).
This comment was marked helpful 0 times.
mchoquet
I'm not sure I understand. Contention is between threads, so if the code is being run on only one core, then I don't see how there can be any contention at all. Would you mind going into more detail?
This comment was marked helpful 0 times.
jinsikl
Pseudocode for implementing barriers using messages:
I imagine we would delegate one thread as master, who will run the following:
for (int i = 0; i < num_procs - 1; i++) {
sync_recv(chan0);
}
// now master thread has received notification from every thread
for (int i = 0; i < num_procs - 1; i++) {
async_send(chan1);
}
And the other threads will run the following:
async_send(chan0); // notify master thread
sync_recv(chan1); // wait for master to notify back
This corresponds to the flat communication on this slide. The "hot spot" in this case is the master thread. If the number of threads is too high, this simple implementation might be too slow. I think a way to solve it is to have a way to broadcast a message to a group of threads, instead of sending one message at a time.
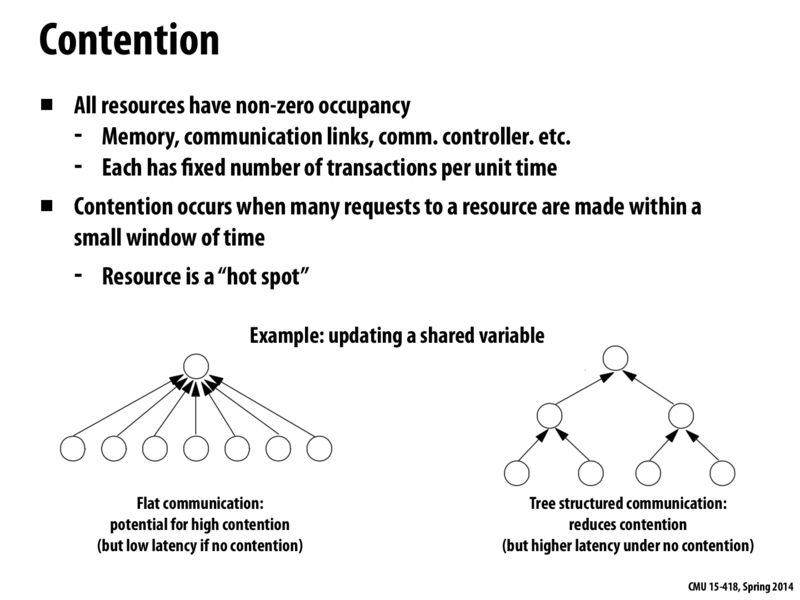
In lecture, after the contention demo it was asked how we might solve the problem of multiple requests contending for the same resource, specifically without changing our set of resources. The accepted suggestion was to stagger our requests--let R1 get sent out, wait a bit, then send R2, and so on.
This doesn't really solve anything, though, right? Holistically speaking, we're still spending just as much time as if all the requests waited for the resource simultaneously. Staggering gives each individual request the illusion that it got instant access to the resource, but no time was saved overall.
What kind of use cases exist for this kind of solution which solves the problem on a request level but doesn't reduce our overall time spent?
This comment was marked helpful 0 times.
Maybe if there was some other work that each person needed to do, then the second person could start on that work during the staggering time (like if each person both needs to walk to Kayvon, shake hands, and come back AND read a few pages of some book, then person A could start walking while person B reads at first and then later starts walking - this would make the total time spent for both people to complete their operations less, much like the laundry example).
I definitely agree that it won't give any benefit in this specific case though, if there's nothing for the people to do while waiting to be sent to Kayvon.
This comment was marked helpful 0 times.
Also, the students in our in-class demo were very well-behaved and waited their turns without having to settle who got to shake hands when. There are some lock implementations for which the work of arranging who gets access to the resource in what order is non-constant with respect to the number of waiting people, and can in fact get quite large. In such a situation, the sum latency across all the requests would be worse if they arrived at once than if each arrived just as the previous one was done. My understanding is that this sort of thing will become particularly important once we start talking about cache coherence.
This comment was marked helpful 0 times.
Possible situation 2: the number of requests coming in is very very very high (say you're Google, for example, and updating some sort of global info every time a query comes in). Now, suppose our locking scheme is perfect so the problem I posed above isn't an issue; you might still encounter slowdowns because storing a large number of requests waiting on a lock takes space, and could easily grow your working set until it overflows your cache. If that's allowed to happen, then either your server must be overprovisioned so that it can still handle requests fast enough (which is expensive), or users could start to experience high latency spikes. Making the stream of requests more regular by stalling some of them would make the behavior of the server more predictable.
This comment was marked helpful 0 times.
Related to this github from piazza: https://github.com/awreece/codearcana/blob/master/content/performance/achieving_maximum_memory_bandwidth.md
The author ends the post with some of the following unanswered questions:
These problems are focusing on why full memory bandwidth was not achieved using a single core, even using SIMD execution and non-temporal instructions (doesnt save to cache). Could the reason for this underutilization be because of contention? When the same code is run on multiple cores, suddenly the theoretical max bandwidth was achieved. Contention here makes sense since a single core would not be able to handle that much memory at once (or rather would be slowed by contention), while multiple cores would not face this problem (or face this problem to a lesser extent).
This comment was marked helpful 0 times.
I'm not sure I understand. Contention is between threads, so if the code is being run on only one core, then I don't see how there can be any contention at all. Would you mind going into more detail?
This comment was marked helpful 0 times.
Pseudocode for implementing barriers using messages:
I imagine we would delegate one thread as master, who will run the following:
And the other threads will run the following:
This corresponds to the flat communication on this slide. The "hot spot" in this case is the master thread. If the number of threads is too high, this simple implementation might be too slow. I think a way to solve it is to have a way to broadcast a message to a group of threads, instead of sending one message at a time.
This comment was marked helpful 0 times.