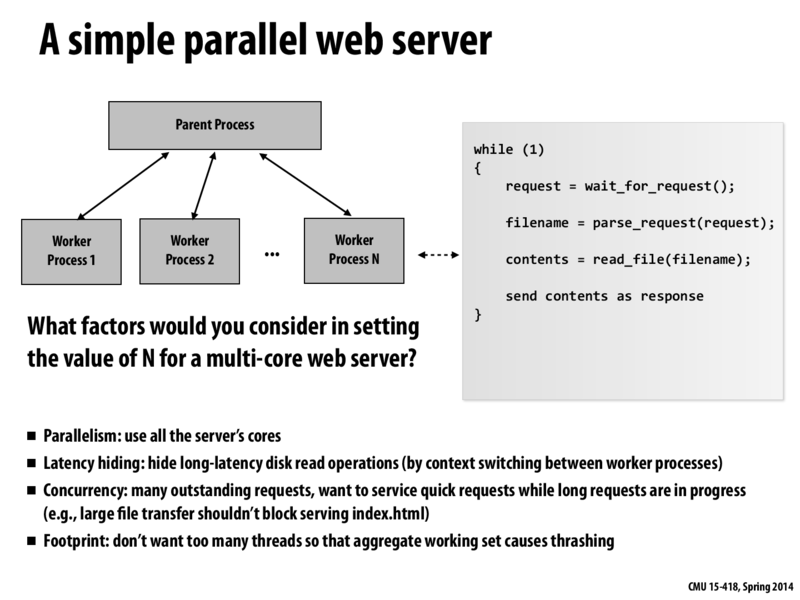
From a practical perspective, how much can a programmer control latency hiding? Are there ways to explicitly signal to the OS when to context switch? If so, are they commonly used? I would imagine that with VMs, context switching becomes more complicated.
This comment was marked helpful 0 times.
crs
@eatnow I don't see any particular reason that makes context switch more complicated. We use context switch to hide latency, so we can take use of CPU times while waiting for some other resources. Same principle applies to server computers. I don't think virtual memory as a technique to separate implementation from abstraction will be affected too much either. The whole memory system may get more complicated as we are trying to handle requests from a more diverse pool.
This comment was marked helpful 0 times.
spilledmilk
@eatnow: To answer your first question, I don't believe that there are any methods to control context-switching from high-level code, but I also do not believe that they would be necessary. As I understand it, an OS will context-switch when no further progress can be made on a stalling thread, which should be the most optimal time to context-switch in any case.
This comment was marked helpful 0 times.
ycp
@eatnow, also consider what the use of asking for a context switch would be if you have no idea where the other process is in its instruction stream. Sure, you could have a barrier or a lock to make sure that it is in a certain place, but then to the same extent, why would you need the context switch in the first place?
This comment was marked helpful 0 times.
idl
I think concurrency here is one of the most important things to keep in mind. A server would be pretty terrible if it had all worker processes serving (a) particularly large request(s), and not have any free to serve small incoming ones. I think this is one of the main differences between designing a web server and designing a 'local' system to parallelize computation: when we were writing the CUDA renderer, we of course never had to think about "okay what we we were handed another smaller circle while we're computing this big one?"
This comment was marked helpful 0 times.
rokhinip
@idl, I do think the reason for this is that we cannot control our input stream and it is not so much an issue of concurrency. In the circle renderer, we had the entire data set we needed to parallelize over in front of us. However, in a website, we receive requests as they come in which means that we need to design our website in a generic manner.
This comment was marked helpful 1 times.
nrchu
It's definitely true that we don't have the entire dataset in front of us, but I think that just makes the parallelization problem more interesting. Based on the kind of site you have and the content you serve, you can make predictions on what the user would request next based on analysis of past traffic. For example, maybe in facebook when people click on a picture, they have a 80% chance of viewing the next x photos in the album, to the point where it would be more efficient to prefetch them. This probably isn't true and is a really simple example but I hope the concept is clear.
From a practical perspective, how much can a programmer control latency hiding? Are there ways to explicitly signal to the OS when to context switch? If so, are they commonly used? I would imagine that with VMs, context switching becomes more complicated.
This comment was marked helpful 0 times.
@eatnow I don't see any particular reason that makes context switch more complicated. We use context switch to hide latency, so we can take use of CPU times while waiting for some other resources. Same principle applies to server computers. I don't think virtual memory as a technique to separate implementation from abstraction will be affected too much either. The whole memory system may get more complicated as we are trying to handle requests from a more diverse pool.
This comment was marked helpful 0 times.
@eatnow: To answer your first question, I don't believe that there are any methods to control context-switching from high-level code, but I also do not believe that they would be necessary. As I understand it, an OS will context-switch when no further progress can be made on a stalling thread, which should be the most optimal time to context-switch in any case.
This comment was marked helpful 0 times.
@eatnow, also consider what the use of asking for a context switch would be if you have no idea where the other process is in its instruction stream. Sure, you could have a barrier or a lock to make sure that it is in a certain place, but then to the same extent, why would you need the context switch in the first place?
This comment was marked helpful 0 times.
I think concurrency here is one of the most important things to keep in mind. A server would be pretty terrible if it had all worker processes serving (a) particularly large request(s), and not have any free to serve small incoming ones. I think this is one of the main differences between designing a web server and designing a 'local' system to parallelize computation: when we were writing the CUDA renderer, we of course never had to think about "okay what we we were handed another smaller circle while we're computing this big one?"
This comment was marked helpful 0 times.
@idl, I do think the reason for this is that we cannot control our input stream and it is not so much an issue of concurrency. In the circle renderer, we had the entire data set we needed to parallelize over in front of us. However, in a website, we receive requests as they come in which means that we need to design our website in a generic manner.
This comment was marked helpful 1 times.
It's definitely true that we don't have the entire dataset in front of us, but I think that just makes the parallelization problem more interesting. Based on the kind of site you have and the content you serve, you can make predictions on what the user would request next based on analysis of past traffic. For example, maybe in facebook when people click on a picture, they have a 80% chance of viewing the next x photos in the album, to the point where it would be more efficient to prefetch them. This probably isn't true and is a really simple example but I hope the concept is clear.
This comment was marked helpful 0 times.