














I'd just like to take a moment to appreciate the effort/color that went into this set of slides.
This comment was marked helpful 9 times.

@wcrichto The period is a little too big for my aesthetic tastes though.
This comment was marked helpful 0 times.






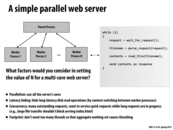
In response to the question, i think the answer depends on our definition of performance. Low latency would be important as it measures how fast we can access the site, and all its resources. If we want a web site that is fast to access for any single user, then we want low latency. Throughput is the transactions per second the site can handle. If the site has many hits at any 1 time, we want high throughput or else eventually, the hits will increase to a point where the site gets overloaded, and it either crashes or becomes staggeringly slow for users. If we measure performance by how much load a site is able to handle (i.e., being able to function normally even with a high amount of hits), then high throughput is more important.
This comment was marked helpful 1 times.
Previously in the course, we've seen that throughput tends to have an inverse relation with latency. However, it seems to be the case here (as @elemental03 noted) that on the web we find more of a direction relation between the two. Adding more servers probably doesn't reduce latency in the same way a scheduler might optimize throughput by increasing individual latencies. Here, giving more throughput almost always decreases the latency of transferring files to clients.
This comment was marked helpful 0 times.

@wcrichto I don't really understand your comment. The slide you linked is showing how a single core might context switch between multiple processes in order to increase throughput. One side effect is that this will increase latency as the core might not be running a process as soon as it becomes runnable. So adding a new server isn't analogous to adding a new context for a core to run, it's like adding an entirely new core. And adding an extra core should decrease latency, as long as there's enough work to be done.
This comment was marked helpful 1 times.

I think the answer is both. In the common situation, if the system have a short latency it could have a higher throughput because the execution time of each task is shorter.
This comment was marked helpful 0 times.

Some websites are persuing low latency in order to give clients good using experiences. Think about using Facebook, you don't want to sit there for several seconds just waiting for latest posts, so Facebook may feed you with some posts (maybe not latest) as fast as they can. In this scenario, clients feels good with low latency, while high throughput does not give us a direct feeling.
This comment was marked helpful 0 times.

From a practical perspective, how much can a programmer control latency hiding? Are there ways to explicitly signal to the OS when to context switch? If so, are they commonly used? I would imagine that with VMs, context switching becomes more complicated.
This comment was marked helpful 0 times.

@eatnow I don't see any particular reason that makes context switch more complicated. We use context switch to hide latency, so we can take use of CPU times while waiting for some other resources. Same principle applies to server computers. I don't think virtual memory as a technique to separate implementation from abstraction will be affected too much either. The whole memory system may get more complicated as we are trying to handle requests from a more diverse pool.
This comment was marked helpful 0 times.

@eatnow: To answer your first question, I don't believe that there are any methods to control context-switching from high-level code, but I also do not believe that they would be necessary. As I understand it, an OS will context-switch when no further progress can be made on a stalling thread, which should be the most optimal time to context-switch in any case.
This comment was marked helpful 0 times.

@eatnow, also consider what the use of asking for a context switch would be if you have no idea where the other process is in its instruction stream. Sure, you could have a barrier or a lock to make sure that it is in a certain place, but then to the same extent, why would you need the context switch in the first place?
This comment was marked helpful 0 times.
I think concurrency here is one of the most important things to keep in mind. A server would be pretty terrible if it had all worker processes serving (a) particularly large request(s), and not have any free to serve small incoming ones. I think this is one of the main differences between designing a web server and designing a 'local' system to parallelize computation: when we were writing the CUDA renderer, we of course never had to think about "okay what we we were handed another smaller circle while we're computing this big one?"
This comment was marked helpful 0 times.

@idl, I do think the reason for this is that we cannot control our input stream and it is not so much an issue of concurrency. In the circle renderer, we had the entire data set we needed to parallelize over in front of us. However, in a website, we receive requests as they come in which means that we need to design our website in a generic manner.
This comment was marked helpful 1 times.

It's definitely true that we don't have the entire dataset in front of us, but I think that just makes the parallelization problem more interesting. Based on the kind of site you have and the content you serve, you can make predictions on what the user would request next based on analysis of past traffic. For example, maybe in facebook when people click on a picture, they have a 80% chance of viewing the next x photos in the album, to the point where it would be more efficient to prefetch them. This probably isn't true and is a really simple example but I hope the concept is clear.
This comment was marked helpful 0 times.
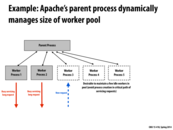
Another way to approach the problem is to use an nginx-style architecture. This means having a static number of processes (so you don't have to spawn a new process for every request, which gets memory intensive) and each process handles multiple requests concurrently with some clever event-based code.
This comment was marked helpful 1 times.

Maintaining several idle workers in pool could also hide latency (or setup cost) in a system with dynamic number of workers. Compared to system without idle workers, system here could send requests to idle workers when a burst happens, and at the same time, set up more workers to handle the flood of requests. In this case, a part of setup costs is hidden by the idle workers. A drawback of this strategy is the energy cost of the idle workers. However, this cost is insignificant in a system with a number of running workers.
This comment was marked helpful 0 times.

Error checking could easily be implemented in this model. If the application requires reliability, the parent process could send two requests to two workers and compare their results. The parent process could check the result itself or could send the results to a worker process. The second method is more desirable because it would not delay handling new client requests.
This comment was marked helpful 0 times.
@wcrichto sounds like the nginx architecture would then not be able to take advantage of hardware parallelism as much, since you're limiting the number of worker processes? The event-based system would then cause the static number of workers to alternate serving requests, thus lowering throughput.
This comment was marked helpful 0 times.

@idl Without reading the page that Will linked to, I'm assuming that the number of processes that nginx spawns is directly correlated to the number of processors on the machine that is running it. Either 1:1, or 2:1 to take advantage of hyper-threading like we are used to seeing. This way hardware parallelism is taken advantage of, at the core level (ignoring SIMD). I think the key point here is that yes, a static number of processes can be less than optimal, but you have to remember that hardware is also static, even more so.
I did, actually, read the page, so I can safely assert that is it up to the administrator running nginx to determine the number of processes (nginx calls them workers) to create initially. Typically this is 1:1 with the number of cores, but if most of the expected work is going to be I/O, the ratio might be 1.5:1 or 2:1.
This comment was marked helpful 1 times.
@traderyw if you're error checking by doing work multiple times I would think that it would be easiest to simply check a hash based signature of the results, which would take almost no time and avoids all the other pitfalls associated with more communication (latency and general work request overhead).
This comment was marked helpful 0 times.
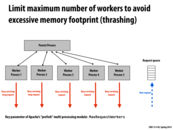

As discussed in lecture, this is also important when there the website's security is compromised. (We don't want to pay amazon a billion dollar bill :D)
This comment was marked helpful 0 times.

In this slide, "workers" is referring to threads (or processes) used by the web server on one box, not additional machines.
This comment was marked helpful 0 times.


What exactly does it mean by recycling workers?
This comment was marked helpful 0 times.
Killing the worker process and starting a new one. It's a common technique to combat the problem of memory leaks. (Albeit not a particularly satisfying solution to a purist.)
This comment was marked helpful 0 times.

@shabnam I think it means the zombie processes would be "reaped" by their parent process so their memory and resources could be used by other processes. Please correct me if I get it wrong.
This comment was marked helpful 0 times.

When might we want to use one partitioning configuration over the other? I can see that processes ensure safety when one worker crashes, and I imagine multi-threaded web servers tend to use less resources (since threads share resources). Are there any situations in which servers partitioned into processes are more efficient in terms of latency or throughput, or vice versa? Or is the fact that multi-threading introduces complications and possible race conditions the only difference?
This comment was marked helpful 0 times.
I would guess you might want to use multi-threaded if you want to have a simple server, and just like mentioned on this slide, if you know you will not be using any non-thread safe libraries nor writing any non-thread safe code. Also, I looked up Apache worker and it said "By using threads to serve requests, it is able to serve a large number of requests with fewer system resources than a process-based server." So depending on the system, you might want to use threads, since processes could be more expensive.
Side note, since I'm not familiar much with system stuff, does 1 thread crash really cause the whole server to crash?
This comment was marked helpful 0 times.

@selena731 Based on this man page, it seems like signals can be sent on either a process level or a thread level, so a thread crash could likely cause the whole process to crash.
This comment was marked helpful 0 times.

Also, there is no need to share communication between different requests in most cases. So it sounds more like process than thread at first glance.
This comment was marked helpful 0 times.
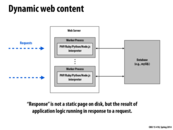

This isn't really related to parallel programming, but how exactly is a database different from a web server? I don't really know how they work. On Slide 19, we had a request go to a server, which then read a file off disk. This is also what we did in 213 proxy lab, if I recall correctly. So when do databases come into play? Are servers nowadays no longer reading off disk/ the server itself, but now going out to a database? Why is this better? Wouldn't this add extra latency?
This comment was marked helpful 0 times.

I'm not sure if you've gotten an answer to this already, but here goes...
You can think of a server and database as separate bits of application logic in your web application. Your server program is like the front-end that takes every client request, processes it, and returns a response to the requester. The server can do a wide variety of things in the processing stage, and what it decides to do depends on what's being requested. Some common examples are:
Retrieve and return the
index.htmlfile. Note that this doesn't have to mean reading the file off disk, though that's what it usually ends up being. index.html is really just a long string, so the server may dynamically generate that. Or, the file may be stored on disk on a separate machine altogether, and the server is going to have to connect to a program running on that other machine, which will then retrieve the file and send it back to the server (and the server will forward that back to the client).Perform some computation on the request parameters and return the result. This doesn't involve disk activity at all.
Extract the parameters of a database query from the request, forward those parameters to a database program, get the query result, and send it back to the client. Databases let you store and manage structured data that's more complex than, say, simple files that can be read in and served directly back to the client. For example, let's say you want to store a bunch of personal data records with the fields {First Name, Last Name, Age, Gender}. You want to be able to create new records, update existing records, query for records (eg. all records with First Name "Eric"), and delete records. Rather than putting these into a bunch of .txt files and having your server program read them in and parse them each time one of these operations is requested, you can move the relevant logic out of the server by using a database program, which are dedicated to doing these things. All your server then has to do is connect to the database program, make a create/read/update/delete (CRUD) request to the database, and the database will do the rest for you. Under the hood, the data is still stored as a bunch of files, but the key point is that the database specializes in dealing with these records and processing CRUD requests, so that you don't have to worry about these when writing your server program (you can almost think of a database as a specialized sort of server program).
Note that the logic to parse data is going to have to occur whether it occurs in the server program or database program, so whether you're using a database or not doesn't really affect your latency as much as where you're storing your data. For example, your database may be (and often is on small scale web applications) running on the same machine as the server, in which case talking to your database is in effect communicating between local processes. Or, when you have multiple server machines accessing data, a database becomes really helpful in managing the requests. One example of a modern database is MongoDB, which can shard (http://docs.mongodb.org/manual/sharding/); i.e. store and manage data across multiple machines, which is great for scalability.
This comment was marked helpful 5 times.

The database is pretty much where you keep the data needed for a web application (static or dynamic). It's really part of the web server. While its true in simpler programs you just read data off of a disk, it gets really messy and slow once you start scaling up. Thats where databases come in (implemented using software like MySql, Postgres, MongoDb). They make it fast and easy to access and manipulate large amounts of information.
All it is really is another level of abstraction above the files stored. Instead of just files sitting in a folder, a database will make optimized choices to store and load data. For example, it might store lookup data in a hash table or a B-tree and it might load data by optimizing the order in which data is retrieved from memory (in order is better than random order). You can think of it as a 'smart' file storage system.
This comment was marked helpful 1 times.
Thanks @LilWaynesFather @ron for the thorough explanations. I've always wondered how databases really worked under the hood and what their purpose was. It seems they do some really clever tricks to achieve their performance.
This comment was marked helpful 0 times.

In class it was mentioned that loading a single webpage such as a Facebook feed may require several hundred requests for various resources, which could be sent to multiple servers hosting files, images, data, etc. On more complex systems, resources can also be loaded from various sources without requiring the webpage frontend to load each one directly.
This comment was marked helpful 0 times.

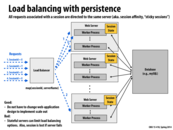

Depending on how the map function works, the load balancer could have an easy or difficult time (ie. mapping sessions based on identifiers like IP addresses or doing it "randomly") figuring out which session goes where. And as the name goes, this in turn affects the amount of traffic in any particular web server. In a situation like this the goal seems to be balancing the trade-off between server and load balancer.
This comment was marked helpful 0 times.
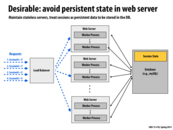
We want to move information about session state into the database for a couple of reasons:
- It allows the web server itself to be generic and so, we get an additional level of abstraction that separates the actual data from the computation/work that is being done in the web server itself
- Our web servers now don't need an internal database/infrastructure of any kind in order to keep track of session information. Presumably, when we had the session information stored on the web server - as in the previous slide - we had a limit on the amount of session state information we can keep track of. This is now, no longer a concern.
This comment was marked helpful 0 times.

Having the session state stored independently from the workers allows the load balancer to map different requests from the same person to different workers. This is because all the different workers will be able to access that persons session state.
This comment was marked helpful 0 times.
Another benefit of this is that this approach ensures that there is no restriction on the load balancing approach that the system can use.
This comment was marked helpful 1 times.
Elaborating on what @mofarrel said, if we stored session state in each worker, if the worker with session ID X was very busy servicing a large request for example, and another request for X comes in, assuming there is just 1 worker per session ID, that request would probably have to wait. Storing the state independently of the workers would let the load balancer distribute that work to other workers that might be idle at that time.
This comment was marked helpful 1 times.

For web applications that has multiple databases storing information about each client, session ID can also tell web process which database to look for this person's information.
This comment was marked helpful 0 times.
This model is also a more reliable scheme than the one in the last slide. Now if a worker went down for some reason, the load balancer could assign another worker to the user instead of creating a brand new session.
This comment was marked helpful 0 times.
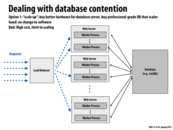

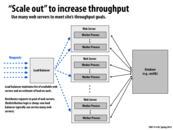
The term scale up typically means improving the performance of one node, such as adding more cores and memories. And scale out means adding more nodes in the system, such as using more web servers and database servers.
There are trade-offs betweens these two approaches, usually scale out would make things more complex, such as in this example, consistency issues and extra storage. While scale up could be expensive and limited, but not adding complexity to the network.
It seems to me that there is an analogy, scale up is like improve the performance of single computer, such as OoO, superscaler etc. While scale out is like multi-core processors and parallelize the work.
This comment was marked helpful 6 times.
One interesting (and unintuitive) point to make here is that scale-up parallelism leads to lower request latency than scale-out parallelism does. For example, suppose you have one machine handling a request stream, and the request rate doubles; adding a second machine allows you to serve requests with the same average latency as the original system, while doubling the speed of your machine halves the average latency. You can learn more about this in 15-359.
This comment was marked helpful 1 times.
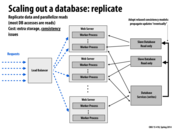

As the number of servers increases, the central database can become the bottleneck. Database replication is one way to distribute the load to other helper databases. Reads and writes have to be ordered correctly to make sure that each web server has a consistent view of the data. In the example in the slide, all database writes are serviced by the Master database. Reads on the other hand are serviced by a set of Slave databases that are replicates of the Master. Data written to the Master database will eventually propagate to the Slave databases, and data consistency is maintained. A setup like this works well in practice because there are generally many more reads than writes in such applications.
This comment was marked helpful 1 times.
If we had a single database, are all the operations - reads and writes - serialized? This seems to strongly parallel multiple processors accessing the single main memory and they can definitely read in parallel in the MESI protocol. I presume that something equivalent is also present for databases when multiple processes read from a single database?
This comment was marked helpful 0 times.
A database server with parallel database query feature could automatically parse a query to several queries that can be executed in parallel. Some databases even allow users to set the parallel degree and generate different executions. Here is how Oracle does this: Parallel Query: Automating Parallelism.
This comment was marked helpful 0 times.

Another benefit to adding databases and replicating the data to them is that a single database is no longer a single point of failure. If one database goes down, our system can still remain up and servicing requests.
This comment was marked helpful 0 times.
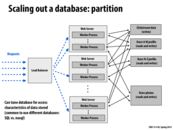

Which one is more commonly used: replicating or partitioning? I don't remember if this was mentioned in lecture. It seems like there are advantages and disadvantages to both, a sort of trade-off.
On the one hand, with replicating, contention is remedied better because if one duplicate of the database is busy, the worker can just try to access a different one instead of waiting. With partition, if there is contention for a profile in the same alphabetical range, the workers will have to wait. However, on average all parts of the alphabet will probably be accessed equally, or you can break up the letters such that it does work that way.
With writing it is also very different. It is a lot more effort to keep writes consistent with replication, since you are only writing to one database and then eventually updating the others. However, with partition, writing to one database will occupy that portion until the write can be completed. It's not immediately clear to me which one would be faster.
This comment was marked helpful 1 times.

Whether replicating or partitioning is better depends on the use case... if the application is such that there are a huge number of read requests but not many write requests (e.g. Google search), then replicating is a better way to go - it may be that tons of people are searching for the same keyword on Google due to recent trends, so partitioning would lead to one database server being very busy relative to the rest.
On the other hand, if there are a lot of writes made very frequently (suppose a central database is used to implement Facebook chat), the effort required to keep everything in sync would be huge and quite wasted. In such a situation, it would make sense to partition (e.g. every chat conversation could have an unique hash which specifies which database server it is stored on).
This comment was marked helpful 1 times.

It seems that, in general, replication is best when we have mostly read requests and partitioning is best when we have many write requests. However, if the distribution of reads to each partition is uneven, the contention for more common partitions may lead to higher request latency. I would think that writes to a partitioned database would be much more efficient than with a replicated one, because for each write you would have to propagate the change to every other slave database and the master. Is this correct, and are there any situations where this would not be true?
This comment was marked helpful 1 times.
I think you are right. Both are suitable for different read/write patterns. However there's a big advantage of using partition: space. Obviously you don't need to copy everything if you are partitioning. Thus the amount of data you can store is a lot more.
This comment was marked helpful 0 times.
My impression was that replication was mainly used to ensure that data on the databases isn't lost. I imagine that in a real system, data is partitioned out of necessity, then the partitions are replicated to ensure that every piece of data is always accessable.
This comment was marked helpful 1 times.

This is a commonly approach, specially in web based companies. For eg linkedin has separate "client service API's" that they used for many different kinds of requests including mobile, web, messaging etc.
This comment was marked helpful 0 times.

In addition to only separating different tasks to different servers, such as the recommender and advertising, there are many efforts to parallelize the generation of the static content of the page as well.
I can't claim to be an expert on the Mozilla Servo project, but different research tasks on the browser demonstrate the different parallel optimizations in the future. Some of the different goals:
Parallelizing rendering of page - The page can either be split into tiles and rendered in parallel, or independent subtrees that can be rendered in parallel. In addition, implementing a DOM tree that is shared between the content and layout tasks allow both to access the DOM tree at the same time.
Parallelizing parsing - Of JS, CSS, HTML
Decoding Resources in Parallel - independent resources
There is also an attached research paper at http://www.eecs.berkeley.edu/~lmeyerov/projects/pbrowser/pubfiles/paper.pdf that goes into some of the challenges of parallelizing the rendering of CSS attributes
For small scale pages, this parallelism might be limited to just one of the web servers but it is easy to see that on large pages with many objects, the front web server can identify different tasks and send all of the possible parallelization tasks to associated worker nodes
This comment was marked helpful 1 times.



For this kind of case where the traffic is pretty much predictable, would it be possible to schedule the scaling to accommodate the traffic beforehand, assuming that what you currently have is definitely not going to be enough when high traffic is coming? For instance, would it be possible to have an extra web server set up only during certain time and disable it otherwise?
This comment was marked helpful 0 times.

Sure, you could, but this still have problems which are nonexistent while using elastic cloud computing. What if your prediction of traffic is wrong? What will you do with the server when you don't need it? The fixed cost of servers which are only used < 10 % of each year will most likely outweigh the cost of ec2.
This comment was marked helpful 0 times.
To summarize the problem, since web traffic to some sites can depend on certain times of the year/month/week,
1) if you try to accommodate the times where the traffic is at its peak, you would face the cost of having those extra servers during times of moderate/normal traffic. Example: extra (physical) storage space + energy costs
but
2) if you try to accommodate the "bare minimum", a.k.a. normal traffic, you would face problems during peak times.
This comment was marked helpful 1 times.

As @woojoonk says, traffic can be pretty predictable in some cases, but I think @smklein is right in saying that elastic cloud computing is a good solution in terms of cost effectiveness. Still, it seems best to have some physical servers that support traffic at low periods, and then use elastic cloud computing on top of that to overall reduce the cost. For the case with the holiday shopping season, you might even rent servers for just a few weeks each year and that would be the cheapest option. It also might be useful to be able to anticipate very brief spikes that need to be supported, as ec2 instances take a while to become available.
This comment was marked helpful 0 times.
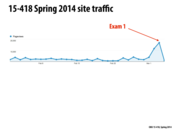
LOL :D
This comment was marked helpful 1 times.
History will repeat itself once more...
This comment was marked helpful 1 times.

Exactly why cloud computing is needed.
This comment was marked helpful 0 times.

To clarify, this is different from the worker management system adopted by Apache described in the beginning of the lecture since that was handling the case of scaling the number of worker processes in one web server while this idea of elasticity is about adding a whole new web server to the existing set of web servers handling the requests.
This comment was marked helpful 1 times.
@rokhinip You are absolutely correct.
This comment was marked helpful 0 times.
Is adding or removing web servers the only change to the system? So there will be no change in the way we scale out databases or in the way load is balanced among the web servers correct?
This comment was marked helpful 0 times.

@elemental03 If you are asking about Amazon EC2, I think the answer is yes. EC2 has a mechanism called Auto-Scaling Group, which would automatically add or shut down servers behind the Elastic Load Balancer based on our customized rules.
This comment was marked helpful 0 times.

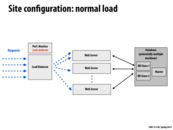

The arrows in the left most represent incoming request stream. Do we assume that this request is coming all at once ? or that requests are coming in different time intervals ? The second set of blue dotted arrows are kind of misleading (to me at least). It makes me assume that what ever comes into the server (load balancer) is forwarded as it is to the web server. If that's the case, Does the load balancer guarantee that the web servers will always have equal amounts of work? Does it have to remember anything to decide ?
This comment was marked helpful 0 times.
Requests to a site can be made simultaneously by multiple users or over different time intervals. The latter case is trivial to handle and so mainly consider the case of multiple simultaneous requests as represented by the left most blue arrows. The second set of blue arrows are not misleading because the requests coming into the site are directly forwarded to the web-servers through the load balancer.
As evidenced by the name, the load balancer simply determines which web server should service a request. The heavy lifting and computation is done by the web server. The load balancer doesn't guarantee equal amounts of work because it cannot know beforehand about the amount of work for each request. Moreover, this is also dependent on the way each web server further splits up the work amongst the worker processes. It can however, use some heuristics to possibly estimate the work load of each web server.
How the load balancer decides to allocate requests to web servers is analogous to asking how any kind of scheduling mechanism works. In this case, there is presumably some querying about the resource availability of each web server. There might also be information in the incoming request which indicates how long it could take (like we do in our homework) and the load balancer might use this information to influence its scheduling policy.
I think an interesting parallel is that of how ISPC tasks are run. We can think of each request to the site here as being 1 ISPC task. Each ISPC task is handled in any order and by any core, much like the requests here are handled in any order (according to the scheduling policy of the load balancer) and by any web server. And finally, the allocation of an ISPC task to a worker/core is dependent on resource availability and busyness of workers and presumably, those factors also come into play here.
This comment was marked helpful 0 times.
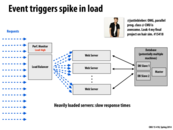

I believe throughput will be fairly high/maximum possible under heavy load since all of our resources are busy servicing requests at any given time. Am I right to say so?
This comment was marked helpful 0 times.

@rokhinip I think that's a reasonable assumption to make, but there are a few things that could possibly reduce the net throughput when the system is under heavy load. These things have to do with the physical limitations of the communication lines that carry the worker responses to the clients and the overheads that arise from substantial sharing of such resources:
Packet Loss: Network congestion leads to switches and routers dropping off packets due to long wait queues. Also, I think that higher congestion will lead to more invalid packets being received due to bit errors, simply because greater network congestion leads to more noise/interference over the communication lines
Collisions: Network congestion also leads to more packets colliding with each other. Policies to handle collisions typically involve some mechanism where the sender detects other messages being sent over the interconnect and waits for a random period of time before resending (similar to the 'snooping' mechanism used in our cache coherence algorithms). An example of such algorithms is Carrier sense multiple access with Collision Detection (CSMA/CD). Either way, this incurs a performance hit on the system throughput.
This comment was marked helpful 1 times.
@arjunh I think what you said makes sense, though I don't think Packet Loss and Collisions are not going to affect the server throughput because those scenarios would only likely to happen once there is already a long queue. Once we have a big queue, the server is already always busy.
This comment was marked helpful 0 times.
@rokhinip Yes you're right to say so. The fact that all resources are busy is really good for throughput. However, the negative side of this is that latency might be affected because the resources available to the system are shared by so many users.
This comment was marked helpful 0 times.
All resources are being well used under high load, this means that they are achieving a high throughput. Increasing the amount of resources (eg. servers) may still increase throughput by allowing us to service more requests at once. Adding these servers would hopefully allow us to drain the queues as well (decreasing latency).
If the throughput is higher than the input, the queues will drain. If the throughput is to lower then the queues will build (adding latency).
This comment was marked helpful 1 times.

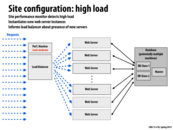
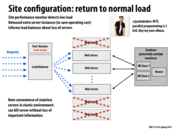
This and the previous slide seem to suggest that simply a measurement of load is what affects whether or not we initiate a new web server to service the extra requests. Other factors we might want to consider is the start up time for a web server.
For example, if we experience a brief interval of high workload which is registered in the performance monitor and then fire up a new web server, it is possible that by the time the web server is ready to handle requests, we would have gone back to having a low/regular load. In such a case, it is perhaps better for the work to be queued up to be completed if the interval of high load is small.
This comment was marked helpful 0 times.

It seems like some sort of learning algorithm could be potentially useful here - if you're running your server system for a long enough time to develop a dataset about traffic patterns, but additional servers have a long delay before they start up, you could use recent traffic and a learning algorithm to infer what the traffic will be after the startup delay and determine whether there will still be enough to make adding an additional server worth it.
This comment was marked helpful 1 times.
@retterermoore
Yea, that seems like a really good idea. Knowing peak hours/days would make it a lot easier to deal with higher loads because you can prepare for it rather than having to deal with it as it happens.
This comment was marked helpful 0 times.
What if the number of requests varies around some certain critical point, which would force starting and killing web servers in a row and make the whole process very expensive?
This comment was marked helpful 0 times.



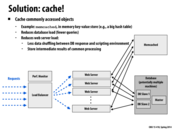
Although memcached is tried and true, it's worth noting that the up-and-coming redis has a larger feature set and seems to do everything memcached does but better.
This comment was marked helpful 0 times.

It was mentioned in lecture that going to disk is worse than going to network and fetching the data from a in memory cache. I thought it was a little bit counterintuitive, since network is unreliable and also slow (maybe even lower bandwidth?). Does anyone have stats comparing the latency and bandwidth of the two approaches?
This comment was marked helpful 0 times.
Someone can check my numbers, but in general it's must easier to get data stored in another machine's memory than it would be to read off local disk. The real advantage is latency. Disk latency is typically measured on the order of a few milliseconds (average seek time). Network latency in a datacenter with quality switches can be measured in a few microseconds.
In terms of throughput, 10 Gbit ethernet is common these days (with 40 and 100 Gbit available and becoming a lot more common quickly). In contrast, 1 Gbit/sec per disk head might be possible in an absolute best case scenario for large contiguous file IO but in practice applications will realize much less. Striping data across multiple disks can improve throughput by adding more heads.
This comment was marked helpful 5 times.
http://brenocon.com/dean_perf.html
Here's the "Numbers Everyone Should Know" from Jeff Dean, which states that
Round trip within same datacenter 500,000 ns 0.5 ms Disk seek 10,000,000 ns 10 ms
Read 1 MB sequentially from network 10,000,000 ns 10 ms Read 1 MB sequentially from disk 30,000,000 ns 30 ms
so it does seem like it much cheaper to take the network route!
This comment was marked helpful 1 times.

Why don't people run memcached on the web server itself? That would remove the network latency, and if the web server can be fitted with enough memory, it seems like that would work equally as well.
This comment was marked helpful 0 times.
It's common to use the term "server" can mean an independent software component of the web site. For example, the web server (e.g., Apache, nginx) is a system that handles http requests and provides responses, the database server handles database queries (e.g., mySql, Mongo), and memcached and Redis) is an in-memory key-value stores that handle get/put requests. All the these "servers" may be running on the machine machine, but for modularity purposes they are distinct systems.
Moreover, they might be running on different virtual machines, which ultimately end up on the same physical box.
This comment was marked helpful 0 times.

Facebook is using Memcached to support their billions of requests per second. And they also came up with an idea called 'lease' to fix the memcached data consistency problems as they put data physically in several data centers around the world.
This comment was marked helpful 0 times.
Wait, but if you get the data from another machine's memory, don't you have to wait for both network latency and disk latency, since that machine has to get the requested data from its own memory?
This comment was marked helpful 0 times.
It's in memory (RAM), not in disk of the other machine.
This comment was marked helpful 0 times.


Consistency in a memcache seems like a very difficult problem. I imagine the approaches to achieve this are similar to the approaches to achieve cache consistency we saw earlier in the course. However, with many large scale sites (Facebook has been mentioned), eventual consistency seems to satisfy a large number of requirements.
This comment was marked helpful 0 times.
True. What makes the consistency here really difficult is that communication now depends on slow and unreliable network rather than the fast and reliable inter-connect. Besides, synching time is extremely difficult in this distributed working environment.
This comment was marked helpful 0 times.
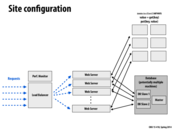

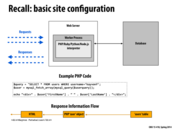
Summary of this picture: We have requests coming in from clients. The load balancer assigns these requests to different workers in the system in a way that should ensure evenness of work distribution among all its active workers. Meanwhile, the performance monitor checks to see that the system is still performing within an acceptable throughput range. If so, nothing changes; if not, it might tell the system to boot up more workers.
The servers themselves handle the requests as necessary, in some cases reading files from disk, performing computations on the inputs, or making a call to the database. When making calls to the database, they first make requests to the memcached servers to check if the desired database query has already been performed. If so, they retrieve that value directly; otherwise they make the database call and then later store the result in the cache.
The database is often replicated, as in the picture, to contain a master database with all the write updates, as well as "slaves", copies of the master which can be easily read from. This enables more efficient access to the database, since the load on the database is spread out instead of being directed to a single master.
This comment was marked helpful 0 times.


For more (recent) information on how Facebook uses memcached, Facebook researchers/engineers gave a presentation at NSDI 2013 and published a paper on scaling memcached.
This comment was marked helpful 2 times.
Awesome. Thanks Tom. I hadn't seen that.
This comment was marked helpful 0 times.
What does unacceptable latency mean?
This comment was marked helpful 0 times.
I'm not exactly sure on the exact latency, but it means that the latency is long enough that it would not be considered acceptable for its users. Usually latency above 200-250ms would be considered unacceptable.
This comment was marked helpful 0 times.
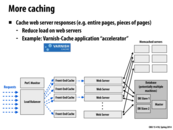

Question: I'm not sure I understand from this slide what the difference between Varnish-Cache and memcached is. It seems like Varnish-Cache caches whole server responses (i.e. as we did in our proxy server in 213) whereas memcached is only for objects returned from database queries. Does this seem right? If so, does this mean that a server that processes mostly writes would be better serviced by memcached since the whole page in Varnish would be invalidated whereas memcached would still contain individual entries for the different parts of the page that was written to? For example, in a comment based page such as this one, adding a new comment would invalidate the whole page in Varnish, but memcached would still contain entries for each of the older comments, only needing to add the new one to the key-value store.
This comment was marked helpful 0 times.
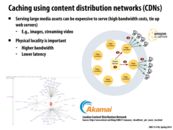

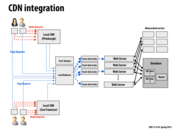
It was mentioned in lecture that things stored in a CDN are not only expensive to serve, but also tend to not change. This is important because updating changes to something on the CDN requires quite a bit of time to propagate to every local CDN server, anywhere from 60 minutes to hours. So, for content that changes often, CDNs are not the greatest idea.
This comment was marked helpful 0 times.

It was also mentioned in lecture that Akamai and other companies like it specialize in content delivery so that smaller companies who can't afford to create their own CDN can share with other companies. Therefore, ec2 cloud computing is to servers what akamai is to CDN's, so that smaller companies and startups can scale their product quickly and affordably depending on their load.
This comment was marked helpful 0 times.

Akamai's biggest customer is Apple. If you're in Pittsburgh browsing iTunes, all the search and navigation requests you make are probably being serviced by Apple's North Carolina datacenter. But when you hit "Buy Song" the content is probably downloaded from an Akamai CDN node less than 50 miles away.
This comment was marked helpful 0 times.

Oh look, it works!
{kind=link}
This comment was marked helpful 5 times.



YEAH!!!!! :D (oh wait... it's over...)
This comment was marked helpful 1 times.
LOL....
This comment was marked helpful 0 times.