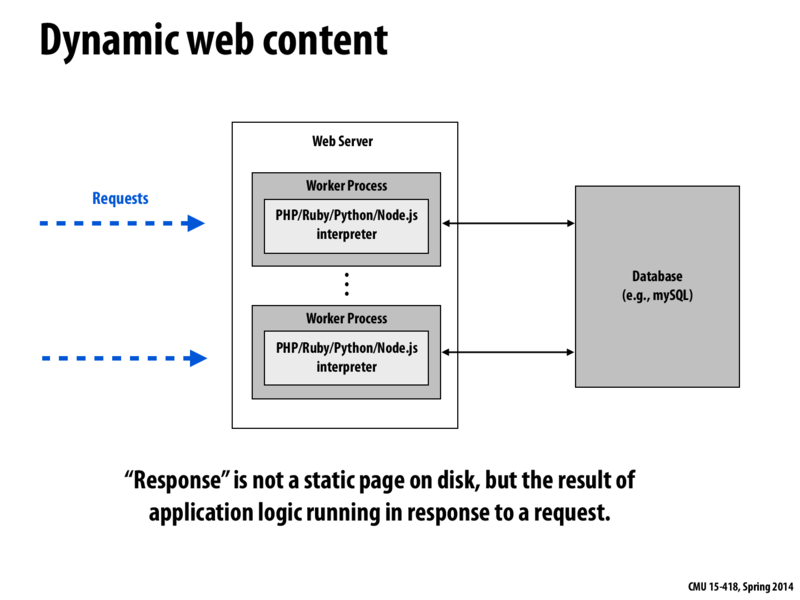
This isn't really related to parallel programming, but how exactly is a database different from a web server? I don't really know how they work. On Slide 19, we had a request go to a server, which then read a file off disk. This is also what we did in 213 proxy lab, if I recall correctly. So when do databases come into play? Are servers nowadays no longer reading off disk/ the server itself, but now going out to a database? Why is this better? Wouldn't this add extra latency?
This comment was marked helpful 0 times.
ron
I'm not sure if you've gotten an answer to this already, but here goes...
You can think of a server and database as separate bits of application logic in your web application. Your server program is like the front-end that takes every client request, processes it, and returns a response to the requester. The server can do a wide variety of things in the processing stage, and what it decides to do depends on what's being requested. Some common examples are:
Retrieve and return the index.html file. Note that this doesn't have to mean reading the file off disk, though that's what it usually ends up being. index.html is really just a long string, so the server may dynamically generate that. Or, the file may be stored on disk on a separate machine altogether, and the server is going to have to connect to a program running on that other machine, which will then retrieve the file and send it back to the server (and the server will forward that back to the client).
Perform some computation on the request parameters and return the result. This doesn't involve disk activity at all.
Extract the parameters of a database query from the request, forward those parameters to a database program, get the query result, and send it back to the client. Databases let you store and manage structured data that's more complex than, say, simple files that can be read in and served directly back to the client. For example, let's say you want to store a bunch of personal data records with the fields {First Name, Last Name, Age, Gender}. You want to be able to create new records, update existing records, query for records (eg. all records with First Name "Eric"), and delete records. Rather than putting these into a bunch of .txt files and having your server program read them in and parse them each time one of these operations is requested, you can move the relevant logic out of the server by using a database program, which are dedicated to doing these things. All your server then has to do is connect to the database program, make a create/read/update/delete (CRUD) request to the database, and the database will do the rest for you. Under the hood, the data is still stored as a bunch of files, but the key point is that the database specializes in dealing with these records and processing CRUD requests, so that you don't have to worry about these when writing your server program (you can almost think of a database as a specialized sort of server program).
Note that the logic to parse data is going to have to occur whether it occurs in the server program or database program, so whether you're using a database or not doesn't really affect your latency as much as where you're storing your data. For example, your database may be (and often is on small scale web applications) running on the same machine as the server, in which case talking to your database is in effect communicating between local processes. Or, when you have multiple server machines accessing data, a database becomes really helpful in managing the requests. One example of a modern database is MongoDB, which can shard (http://docs.mongodb.org/manual/sharding/); i.e. store and manage data across multiple machines, which is great for scalability.
This comment was marked helpful 5 times.
LilWaynesFather
The database is pretty much where you keep the data needed for a web application (static or dynamic). It's really part of the web server. While its true in simpler programs you just read data off of a disk, it gets really messy and slow once you start scaling up. Thats where databases come in (implemented using software like MySql, Postgres, MongoDb). They make it fast and easy to access and manipulate large amounts of information.
All it is really is another level of abstraction above the files stored. Instead of just files sitting in a folder, a database will make optimized choices to store and load data. For example, it might store lookup data in a hash table or a B-tree and it might load data by optimizing the order in which data is retrieved from memory (in order is better than random order). You can think of it as a 'smart' file storage system.
This comment was marked helpful 1 times.
sbly
Thanks @LilWaynesFather @ron for the thorough explanations. I've always wondered how databases really worked under the hood and what their purpose was. It seems they do some really clever tricks to achieve their performance.
This isn't really related to parallel programming, but how exactly is a database different from a web server? I don't really know how they work. On Slide 19, we had a request go to a server, which then read a file off disk. This is also what we did in 213 proxy lab, if I recall correctly. So when do databases come into play? Are servers nowadays no longer reading off disk/ the server itself, but now going out to a database? Why is this better? Wouldn't this add extra latency?
This comment was marked helpful 0 times.
I'm not sure if you've gotten an answer to this already, but here goes...
You can think of a server and database as separate bits of application logic in your web application. Your server program is like the front-end that takes every client request, processes it, and returns a response to the requester. The server can do a wide variety of things in the processing stage, and what it decides to do depends on what's being requested. Some common examples are:
Retrieve and return the
index.htmlfile. Note that this doesn't have to mean reading the file off disk, though that's what it usually ends up being. index.html is really just a long string, so the server may dynamically generate that. Or, the file may be stored on disk on a separate machine altogether, and the server is going to have to connect to a program running on that other machine, which will then retrieve the file and send it back to the server (and the server will forward that back to the client).Perform some computation on the request parameters and return the result. This doesn't involve disk activity at all.
Extract the parameters of a database query from the request, forward those parameters to a database program, get the query result, and send it back to the client. Databases let you store and manage structured data that's more complex than, say, simple files that can be read in and served directly back to the client. For example, let's say you want to store a bunch of personal data records with the fields {First Name, Last Name, Age, Gender}. You want to be able to create new records, update existing records, query for records (eg. all records with First Name "Eric"), and delete records. Rather than putting these into a bunch of .txt files and having your server program read them in and parse them each time one of these operations is requested, you can move the relevant logic out of the server by using a database program, which are dedicated to doing these things. All your server then has to do is connect to the database program, make a create/read/update/delete (CRUD) request to the database, and the database will do the rest for you. Under the hood, the data is still stored as a bunch of files, but the key point is that the database specializes in dealing with these records and processing CRUD requests, so that you don't have to worry about these when writing your server program (you can almost think of a database as a specialized sort of server program).
Note that the logic to parse data is going to have to occur whether it occurs in the server program or database program, so whether you're using a database or not doesn't really affect your latency as much as where you're storing your data. For example, your database may be (and often is on small scale web applications) running on the same machine as the server, in which case talking to your database is in effect communicating between local processes. Or, when you have multiple server machines accessing data, a database becomes really helpful in managing the requests. One example of a modern database is MongoDB, which can shard (http://docs.mongodb.org/manual/sharding/); i.e. store and manage data across multiple machines, which is great for scalability.
This comment was marked helpful 5 times.
The database is pretty much where you keep the data needed for a web application (static or dynamic). It's really part of the web server. While its true in simpler programs you just read data off of a disk, it gets really messy and slow once you start scaling up. Thats where databases come in (implemented using software like MySql, Postgres, MongoDb). They make it fast and easy to access and manipulate large amounts of information.
All it is really is another level of abstraction above the files stored. Instead of just files sitting in a folder, a database will make optimized choices to store and load data. For example, it might store lookup data in a hash table or a B-tree and it might load data by optimizing the order in which data is retrieved from memory (in order is better than random order). You can think of it as a 'smart' file storage system.
This comment was marked helpful 1 times.
Thanks @LilWaynesFather @ron for the thorough explanations. I've always wondered how databases really worked under the hood and what their purpose was. It seems they do some really clever tricks to achieve their performance.
This comment was marked helpful 0 times.