As the number of servers increases, the central database can become the bottleneck. Database replication is one way to distribute the load to other helper databases. Reads and writes have to be ordered correctly to make sure that each web server has a consistent view of the data. In the example in the slide, all database writes are serviced by the Master database. Reads on the other hand are serviced by a set of Slave databases that are replicates of the Master. Data written to the Master database will eventually propagate to the Slave databases, and data consistency is maintained. A setup like this works well in practice because there are generally many more reads than writes in such applications.
This comment was marked helpful 1 times.
rokhinip
If we had a single database, are all the operations - reads and writes - serialized? This seems to strongly parallel multiple processors accessing the single main memory and they can definitely read in parallel in the MESI protocol. I presume that something equivalent is also present for databases when multiple processes read from a single database?
This comment was marked helpful 0 times.
squidrice
A database server with parallel database query feature could automatically parse a query to several queries that can be executed in parallel. Some databases even allow users to set the parallel degree and generate different executions. Here is how Oracle does this: Parallel Query: Automating Parallelism.
This comment was marked helpful 0 times.
sluck
Another benefit to adding databases and replicating the data to them is that a single database is no longer a single point of failure. If one database goes down, our system can still remain up and servicing requests.
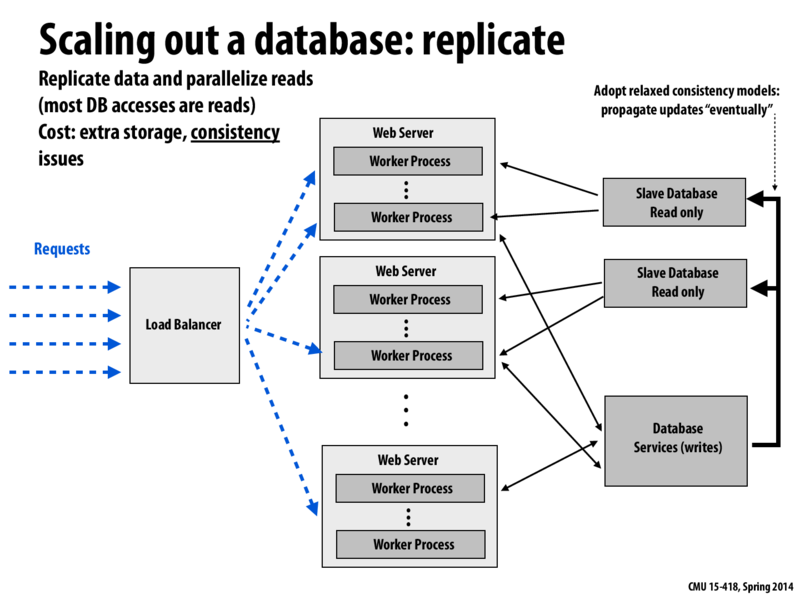
As the number of servers increases, the central database can become the bottleneck. Database replication is one way to distribute the load to other helper databases. Reads and writes have to be ordered correctly to make sure that each web server has a consistent view of the data. In the example in the slide, all database writes are serviced by the Master database. Reads on the other hand are serviced by a set of Slave databases that are replicates of the Master. Data written to the Master database will eventually propagate to the Slave databases, and data consistency is maintained. A setup like this works well in practice because there are generally many more reads than writes in such applications.
This comment was marked helpful 1 times.
If we had a single database, are all the operations - reads and writes - serialized? This seems to strongly parallel multiple processors accessing the single main memory and they can definitely read in parallel in the MESI protocol. I presume that something equivalent is also present for databases when multiple processes read from a single database?
This comment was marked helpful 0 times.
A database server with parallel database query feature could automatically parse a query to several queries that can be executed in parallel. Some databases even allow users to set the parallel degree and generate different executions. Here is how Oracle does this: Parallel Query: Automating Parallelism.
This comment was marked helpful 0 times.
Another benefit to adding databases and replicating the data to them is that a single database is no longer a single point of failure. If one database goes down, our system can still remain up and servicing requests.
This comment was marked helpful 0 times.