This and the previous slide seem to suggest that simply a measurement of load is what affects whether or not we initiate a new web server to service the extra requests. Other factors we might want to consider is the start up time for a web server.
For example, if we experience a brief interval of high workload which is registered in the performance monitor and then fire up a new web server, it is possible that by the time the web server is ready to handle requests, we would have gone back to having a low/regular load. In such a case, it is perhaps better for the work to be queued up to be completed if the interval of high load is small.
This comment was marked helpful 0 times.
retterermoore
It seems like some sort of learning algorithm could be potentially useful here - if you're running your server system for a long enough time to develop a dataset about traffic patterns, but additional servers have a long delay before they start up, you could use recent traffic and a learning algorithm to infer what the traffic will be after the startup delay and determine whether there will still be enough to make adding an additional server worth it.
This comment was marked helpful 1 times.
ycp
@retterermoore
Yea, that seems like a really good idea. Knowing peak hours/days would make it a lot easier to deal with higher loads because you can prepare for it rather than having to deal with it as it happens.
This comment was marked helpful 0 times.
DunkMaster
What if the number of requests varies around some certain critical point, which would force starting and killing web servers in a row and make the whole process very expensive?
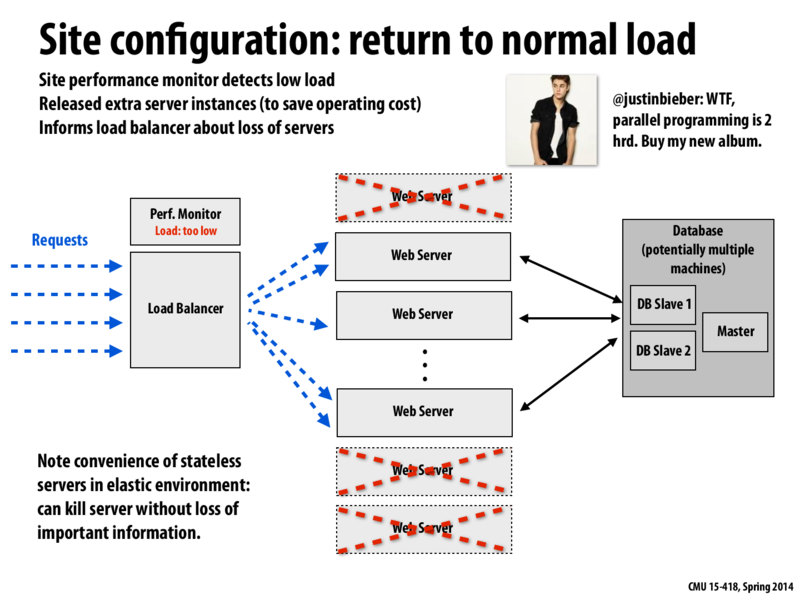
This and the previous slide seem to suggest that simply a measurement of load is what affects whether or not we initiate a new web server to service the extra requests. Other factors we might want to consider is the start up time for a web server.
For example, if we experience a brief interval of high workload which is registered in the performance monitor and then fire up a new web server, it is possible that by the time the web server is ready to handle requests, we would have gone back to having a low/regular load. In such a case, it is perhaps better for the work to be queued up to be completed if the interval of high load is small.
This comment was marked helpful 0 times.
It seems like some sort of learning algorithm could be potentially useful here - if you're running your server system for a long enough time to develop a dataset about traffic patterns, but additional servers have a long delay before they start up, you could use recent traffic and a learning algorithm to infer what the traffic will be after the startup delay and determine whether there will still be enough to make adding an additional server worth it.
This comment was marked helpful 1 times.
@retterermoore
Yea, that seems like a really good idea. Knowing peak hours/days would make it a lot easier to deal with higher loads because you can prepare for it rather than having to deal with it as it happens.
This comment was marked helpful 0 times.
What if the number of requests varies around some certain critical point, which would force starting and killing web servers in a row and make the whole process very expensive?
This comment was marked helpful 0 times.