Although the logic behind the slide makes sense as given in lecture, how reliable is this data if it's from a survey of programs in 1991? Compilers have definitely changed in the last twenty years.
This comment was marked helpful 0 times.
kayvonf
@wrichto, this is a good question. Keep in mind this not a situation of a compiler finding the parallelism and automatically generating parallel code. Instead, this chart plots the benefits of superscalar logic in a processor when running instruction streams from a benchmark suite. This logic must inspect an instruction stream and then analyze instruction dependencies in order to find independent work that can be executed in parallel. As a CPU tries to fill more and more execution units (as we move down the X axis of the graph), it has to work even harder to analyze the program to find work (look over a wider and wider window of future instructions). At some point, even if a program had a lot of parallelism, there's more cost put in to analyze all the dependencies than to just run the code!
Of course, instead of having a CPU find the ILP dynamically, a compiler could analyze the code off-line, and generate explicitly parallel instructions for a processor to execute, such as is the case in a VLIW architecture. Even so this is a very difficult problem that has not yielded much success. There simply isn't much local parallelism in most instruction streams, and trying to find global parallelism in software written in a C-like language remains an open research problem.
That doesn't mean there's not much parallelism in programs, it's just hard for compilers and processors to find it unless they are given really strong hints. It is simply much easier to have the application developer explicitly parallelize code, or write in a constrained programming model where the parallelism is easy for compiler/architecture to find (you will write code in such models in all assignments in this class).
Of course, having to thinking about parallelism usually makes things harder on the application developer though, one of the reasons why 15-418 exists.
This comment was marked helpful 1 times.
devs
Yihua mentioned super linear scaling to me in a piazza post (The ability to reach a speedup of greater than p when there are only p processors used - http://en.wikipedia.org/wiki/Speedup#Super_linear_speedup. I'm slightly confused on how this procedure works. Can processors easily access caches associated with other processors? And if not, wouldn't there be a good amount of communication overhead (figuring out if certain information exists in any one of the p caches)?
This comment was marked helpful 0 times.
DunkMaster
This graph is a bit confusing...why is this the case? What is the main reason for preventing further speedup utilizing more ILP per processor?
This comment was marked helpful 0 times.
kayvonf
@DunkMaster. Real-world programs don't have large numbers of independent instructions, so those extra units often have nothing to so. (insufficient parallelism in an instruction stream).
This comment was marked helpful 0 times.
tchitten
Kayvon mentioned VLIW architectures so I thought I'd leave this link about The Mill CPU. The Mill CPU replaces stacks and registers with something called the "belt". Every cycle the CPU starts multiple instructions with operands from the belt and when they're finished they push the result on the front of the belt. It's a really interesting concept and I'd definitely encourage reading about it.
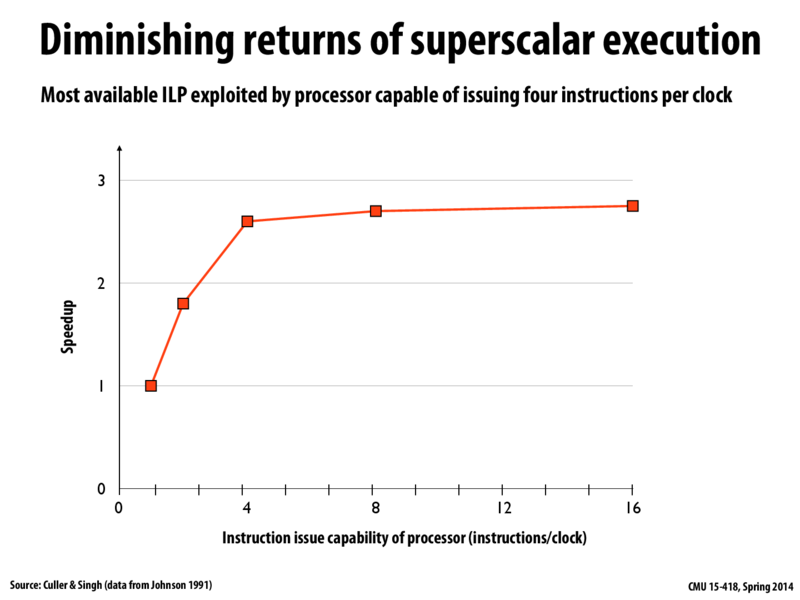
Although the logic behind the slide makes sense as given in lecture, how reliable is this data if it's from a survey of programs in 1991? Compilers have definitely changed in the last twenty years.
This comment was marked helpful 0 times.
@wrichto, this is a good question. Keep in mind this not a situation of a compiler finding the parallelism and automatically generating parallel code. Instead, this chart plots the benefits of superscalar logic in a processor when running instruction streams from a benchmark suite. This logic must inspect an instruction stream and then analyze instruction dependencies in order to find independent work that can be executed in parallel. As a CPU tries to fill more and more execution units (as we move down the X axis of the graph), it has to work even harder to analyze the program to find work (look over a wider and wider window of future instructions). At some point, even if a program had a lot of parallelism, there's more cost put in to analyze all the dependencies than to just run the code!
Of course, instead of having a CPU find the ILP dynamically, a compiler could analyze the code off-line, and generate explicitly parallel instructions for a processor to execute, such as is the case in a VLIW architecture. Even so this is a very difficult problem that has not yielded much success. There simply isn't much local parallelism in most instruction streams, and trying to find global parallelism in software written in a C-like language remains an open research problem.
That doesn't mean there's not much parallelism in programs, it's just hard for compilers and processors to find it unless they are given really strong hints. It is simply much easier to have the application developer explicitly parallelize code, or write in a constrained programming model where the parallelism is easy for compiler/architecture to find (you will write code in such models in all assignments in this class).
Of course, having to thinking about parallelism usually makes things harder on the application developer though, one of the reasons why 15-418 exists.
This comment was marked helpful 1 times.
Yihua mentioned super linear scaling to me in a piazza post (The ability to reach a speedup of greater than p when there are only p processors used - http://en.wikipedia.org/wiki/Speedup#Super_linear_speedup. I'm slightly confused on how this procedure works. Can processors easily access caches associated with other processors? And if not, wouldn't there be a good amount of communication overhead (figuring out if certain information exists in any one of the p caches)?
This comment was marked helpful 0 times.
This graph is a bit confusing...why is this the case? What is the main reason for preventing further speedup utilizing more ILP per processor?
This comment was marked helpful 0 times.
@DunkMaster. Real-world programs don't have large numbers of independent instructions, so those extra units often have nothing to so. (insufficient parallelism in an instruction stream).
This comment was marked helpful 0 times.
Kayvon mentioned VLIW architectures so I thought I'd leave this link about The Mill CPU. The Mill CPU replaces stacks and registers with something called the "belt". Every cycle the CPU starts multiple instructions with operands from the belt and when they're finished they push the result on the front of the belt. It's a really interesting concept and I'd definitely encourage reading about it.
This comment was marked helpful 1 times.