



Question: In 15-213's web proxy assignment you gained experience writing concurrent programs using pthreads. Think about your motivation for programming with threads in that assignment. How was it different from the motivation to create multi-threaded programs in this class? (e.g., consider Assignment 1, Program 1)
Hint: What is the difference between concurrent execution and parallel execution?
This comment was marked helpful 0 times.

In the proxy, we primarily focused on concurrent execution. That is, we wanted the ability to execute multiple tasks at the same time so that they could be serviced fairly. A large request, such as a video download, should not substantially delay smaller requests, such as those involving simple plain text, from being processed.
If we had only one core, the CPU could context-switch between these requests, so that they could be serviced. So, we could first process the large request for a bit, then switch over to smaller requests and complete those, before getting back to the large request.
We didn't really think about mapping the requests to individual cores explicitly (which would allow multiple requests to actually run simultaneously, without necessitating context-switching). If we had several cores, we could have processed these requests concurrently by doing them in parallel.
So, concurrent execution has to do mainly with the notion that we can have multiple tasks in the state of being processed at any one time. Parallel execution has to do with processing these requests simultaneously, on separate cores.
This comment was marked helpful 3 times.
Question: for those that have OS experience... Give some performance reasons why an OS might want to context switch separate threads (or processes) on a single-core machine? How are these new examples related to the use of concurrency in the 15-213 proxy assignment?
p.s. @arjunh, sweet answer above.
This comment was marked helpful 0 times.
Perhaps there is an OS related answer to this which I'm not familiar with, but @arjunh: I understand the difference between concurrency and parallelism, but about the motivation for proxy lab, why couldn't parallelism be used anyway? Assuming that there isn't a difference in the difficulty of writing the actual code for both. For instance, give one core the large request to work with, while keeping on giving the small requests to other cores to keep them busy. That way (theoretically?) no time is lost on context switch for the big task.
This comment was marked helpful 0 times.
@selena731: The execution of the proxy pthreads can theoretically be done in parallel (the only resource shared among the pthreads is the cache; we can resolve this problem by introducing locks to ensure safe access). However, this is assuming that there are additional cores to run the pthreads.
Additionally, in most parallel programs, the programmer needs to provide a cue that the threads can be executed in parallel, which may require special language frameworks (such as OpenMP, CUDA, etc). This parallelism simply can't be realized by the compiler, as the code is rather complex, making it difficult to ensure that there are no dependencies that could affect the correctness of the program.
Lastly, it is difficult to ensure the the work-load is distributed evenly; doing so requires analyzing the workload of all the processors at any given time (when we want to run a new thread on a core). Again, there are parallel languages that can abstract away the low-level hardware details, but it is still a challenging problem.
From the 213 perspective, this objective was simply unnecessary.
This comment was marked helpful 0 times.

I think the OS's perspective of using pthreads in proxy lab is to use hardware efficiently, specifically network resources in this case (because the tasks are IO bounded in proxy). That is, we don't want the network to rest while processing some logic. Providing small latency, as @arjunh said, is also very important.
This comment was marked helpful 0 times.

The CPU is much faster than memory, and memory is faster than most of I/O device. Suppose we have two threads: thread A is I/O consuming, while thread B is CPU consuming. Then when thread A is on CPU and waiting for some late I/O , the CPU is idle. So OS will block the thread A and switch thread B running on CPU, to make the system more efficient.
This comment was marked helpful 1 times.

In the proxy lab of 15-213, we use PThreads to let the proxy be able to process multiple requests at the same time. In my opinion, concurrency means that multiple tasks can happen independently of each other and each task completes in overlapping time periods. It doesn't mean that the tasks are running literally at the same time. For example, multiple task running on single-core processor.
Parallelism literally means that the tasks are running simultaneously on different cores. To some degree, parallelism is a form of concurrency.
This comment was marked helpful 2 times.

Concurrent Execution implies that we are performing multiple tasks but we switch between them as we have hardware capability to perform only one probably at any given time. Parallel Execution implies multiple tasks can be executed on different cores at the same time.
This comment was marked helpful 0 times.

I think the main difference between the motivation of using threads for proxy and creating multi-threaded programs in this class is that:
for proxy (concurrency): we want to solve multiple problems (handle multiple tasks) at the same time (even when there is a single processor).
for this class (parallelism): we want to solve a single computation-heavy problem by using multiple computation resources.
This comment was marked helpful 1 times.

I think the main use of threads on a single core is as an abstraction to the CPU resources. It certainly would be possible to craft a single thread to perform the function of multiple threads by carefully choosing different items to work on in a sequential manner, however this would be cumbersome and error prone. By using the OS or a library to facilitate this abstraction it allows the programmer to clearly delineate different workflows. Further, in the presence of multiple cores, multi-threaded programs can scale in a way single-threaded programs cannot. In proxylab we used threads to serve multiple requests, and while it certainly would be possible to do so without threads it would be extremely painful and thus we insert a layer of abstraction between the programmer and the CPU to ease development.
In this class we do not use threads so much as an abstraction than as a tool to increase processing throughput by exploiting true parallelism on modern CPUs/GPUs.
This comment was marked helpful 0 times.

Additionally, coming back to this topic after the 1/15 lecture, using multiple threads on a single core can hide latency for time intensive kernel tasks, such as fetching data from main memory or the hard drive, by switching to a different thread when a stalling instruction is encountered and returning to the thread after the stalling instruction is completed.
This comment was marked helpful 1 times.

I agree with many of the previous comments. In proxy lab, we used pthreads so that we could hide the latency for larger, more time consuming requests. Concurrency allowed us to switch between requests, reducing the total time (in comparison to a sequential proxy) the proxy took to handle multiple requests. I also think that parallelism is a form of concurrency. To me, concurrency means being in the process of executing multiple tasks at the same time. Parallelism specifies that we are using multiple resources to execute those tasks.
This comment was marked helpful 0 times.

OS might want to context switch separate threads on a single-core machine because thread is waiting for some external event (relative to CPU) to happen. The event could be waiting for a local disk read, or response from a remote server as in the case of 15-213 proxy. Since CPU will sit idle for a relatively long period, other threads can take use of the time.
This comment was marked helpful 0 times.

Concurrency is relevant when we have multiple tasks that compete for scarce resources such as the CPU. This usually involves techniques that maximize computing resources by minimized idle time on the CPU and I/O devices. Parallelism however is concerned with the problem of optimally breaking up one large task into subtasks and distributing these tasks to many computing resources (cores on a machine).
This comment was marked helpful 0 times.

Concurrency means that each task gets a chance to run for a while on a single core computer, but at any moment only one task is running. Parallel means that we can run multiple tasks on multiple cores, at any moment there might be multiple tasks running on the cores.
This comment was marked helpful 0 times.

Concurrency is a way to give every program a chance to run. Mainly to avoid starvation and give the user a feeling that various programs could run at the same time. Parallelism is a way to utilize the computational power to achieve faster computation. And this sometimes might increase the work but as long as the span is shortened, everything is fine.
This comment was marked helpful 0 times.


One person had to add up 15 numbers which took them 35s.
Then two people performed the same task with different numbers. They could only communicate with each other through passing a sheet of paper. This took 34s for the final sum to be computed. Since we have 2 processors, we would expect the work to be done twice as fast but took the exact same amount of time. Due to communication overhead.
To reduce the latency in communication of the processors, move them closer together or improve the communication speed.
This comment was marked helpful 0 times.

How would moving them closer make things better? Also, from a programming perspective, if the communication protocol was pre-defined (aka the students could've spoken to each other before they knew that they could only communicate later via paper), that would also create a speedup.
This comment was marked helpful 0 times.

I think the point that was being made was that multiple factors contribute to communication overhead. Moving two communicating objects closer makes things better because it takes less time, but this decrease in time for processors may be negligible for processors on the same computer in comparison to other factors, as the time it takes would probably not be a substantial part of the overhead.
This comment was marked helpful 0 times.


So, for a very simple example, if 1 processor executes in 20ms, and the execution time using 4 processors is 5ms, then the speedup would be 4.00x.
This comment was marked helpful 0 times.


I was thinking about Monte Carlo algorithms, which can give good runtimes at the cost of sometimes yielding an incorrect answer. Even though there are algorithms which are guaranteed to give the correct answer, Monte Carlo algorithms run faster and tend to have a low probability of failing (and may be run multiple times to further reduce that chance). Analagously, problems which can be solved in parallel usually require thread communication/synchronization, which are costly, but will guarantee a correct outcome. Are there problems where limiting that synchronization is preferable, even though the solution may be slightly incorrect as a result?
This comment was marked helpful 0 times.
Just as in Monte Carlo algorithm, you are essentially hurting "correctness" to achieve better runtime. Other cases where you want to limit synchronization at the cost of correctness might be: 1. When you only want an estimation of the answer rather than the exact. 2. When the probability of one type of result shows up much more frequently. e.g. password checking where you know when the password is wrong really fast and double check on correct password.
This comment was marked helpful 1 times.

There's a bit of a false dichotomy here; Monte Carlo is naturally parallel because the result of one random trial doesn't depend on the results of the other trials. Monte Carlo's popular for board game AIs for this reason (Go, Chess, Reversi etc). It's asymptotically faster than finding the perfect moves (polynomial vs. exponential (and in Go's case practically impossible)), and the additional throughput from simulating games in parallel is more than worth the synchronization overhead.
I think the key thing to remember is that overhead matters less the more you can get done between communications. I think prioritizing limiting synchronization is usually only better for problems pertaining to small amounts of data.
This comment was marked helpful 0 times.

For Monte Carlo algorithms, there is polynomial-time correctness checking, which guarantees the algorithms output the correct answer at the end. While we can do the same checking for parallel programs without synchronization to get the correct results, is there any chance the absence of communication leads to the low-level errors and eventually crashes the program?
This comment was marked helpful 0 times.
Sometimes, the communication cost is minimized but the program is still not able to achieve anticipated speedup. In this case, it is because there are some unnecessary communications between processes. For example, in a master-slave model, the slaves do not need to know information from each other, so collect information from each process only at the master level might be able to eliminate unnecessary communications.
This comment was marked helpful 0 times.



I think that is why MapReduce Framework will pre-process the data uploaded by user. It will divide data into several parts of relative same size. The number of parts will correlation to the number of compute nodes available at that time. However, pre-process can't guarantee the distribution of work will be perfect, there are always some parts that are slow, and what MapReduce does is to generate some new tasks to help complete these extremely slow parts to smooth the worst case.
This comment was marked helpful 0 times.
This came up during assignment 1: having the same size doesn't always guarantee the computation will take the same amount of time. In this case, how does MapReduce determine whether one process is being too slow or not and decide to add more tasks?
This comment was marked helpful 0 times.

@mpile13 I'm not sure MapReduce tries to solve that problem. It's main concern is providing a reliable distributed computing that scales. As far as I know MapReduce will spawn a map task for each block, and never has a block being processed by multiple tasks.
This comment was marked helpful 0 times.

@mpile13 I believe jinsikl is correct, MapReduce add more tasks based on whether one process is too slow or not. Remember that MapReduce is used on very large scale computations. If a single node's input of data is abnormal and causes some kind of error or simply takes too long to compute, we can alert the user and they can either manually examine the case or simply discard that worker. With a very large network, the contribution of a single worker is not very significant (think wordcount for a million pages, for example) and you will get a very close approximate answer regardless.
I am not sure what black is saying when about MapReduce generating new tasks when some are extremely slow. Pure speculation: it might be possible that if we expect a large variance in computation time, but have no way of predicting it, then when a certain worker node takes too long to complete, the master can duplicate the work that was assigned to that node and split it into N parts to N idle workers. I think this would work very well if we expect either very short computation time OR very long computation time, because there will be more and more idle workers as the entire algorithm is bottlenecked by the reducers. However, I have no idea if there is any mapreduce framework that handles anything like this.
This comment was marked helpful 0 times.



Just to recap, I believe the two proposed solutions for this problem (counting the total number CS courses all the students in the room are enrolled in) were: 1. Parallelize by pairing up students, summing the number of courses between them, then pairing the sums, summing those, etc., which would be log(n) time. 2. Parallelize summing each row and being limited by either the longest row or number of rows.
The context of the problem is what made the second solution more efficient in the classroom, due to communication overhead (trying to pair people up around the room could take a long time).
Does anyone have examples of real-world contexts of parallelism where the theoretically optimized solution is less effective than the "best" one? I'm having trouble coming up with something very different to what we did in class.
This comment was marked helpful 0 times.

@snshah I'm not sure if this applies, but one thing that came to mind is the case when you’re dealing with specific tools or frameworks, like Hadoop. You need to finely tune the amount of data per map and the number of maps; among other things, for the optimized solution to be efficient. For example, processing small blocks of data is not efficient (as it is optimized for large ones) and having too many maps can cause scheduling overhead.
I found this post which talks about it in more detail.
This comment was marked helpful 0 times.
To add to @aaguilet's comment I have myself seen this happen. Theoretically Hadoop was supposed to perform better on my dataset with a big cluster but it performed much worse. The reason we later found out was that each mapper had a IO output buffer which wasn't enough. It led to what ( in Hadoop terms ) is known as "spilling" after every map task and that caused us to lose any speedups gained by the parallelization achieved with hadoop. This was mainly because I/O costs took away all the speedups.
This comment was marked helpful 0 times.
Communication really need to take into consideration when we implement parallel program. MapReduce makes reducer created at the very beginning and fetch the data once there is a mapper finished its task. Then the data transfer time can be reduced significantly because of this technology!
This comment was marked helpful 0 times.

Even looking at how MapReduces are implemented, you notice they don't exactly use the tree structure mentioned above, but rather work on several big chunks of memory and generally process data within each chunk sequentially. This lets you take advantage of both parallelism and computers' ability to work extremely quickly on sequential tasks, and it demonstrates the tradeoff between the costs and benefits of parallelism. And of course, you can make this more efficient using latency-reducing techniques like described by black above.
This comment was marked helpful 0 times.

I feel like the analogy breaks down between the demo and a real parallel program in that there was no "algorithm". If we were told beforehand that we were to pass our partial sums to the left and then front of the classroom, we would have taken much less time.
However, even if we had meticulously planned out the O(log(n)) span "reduce" function from 150/210, I believe that we would find it to be slower than the O(sqrt(n)) span "row by row" solution. The main reason is that in the "row by row" solution, all communications occur between neighbors, while the "reduce" algorithm requires long distance communication. I believe the same would be true on supercomputers, which are commonly laid out as grids/tori (http://en.wikipedia.org/wiki/Torus_interconnect).
This comment was marked helpful 1 times.

Question: When determining if a parallel program scales, what are some of the main things to look at other than the 3 listed above? I imagine that finding a way to split up work effectively and minimize communication overhead is part of the answer, but what are other common considerations that need to be made?
This comment was marked helpful 0 times.

Having just taken Distributed Systems last semester, first thing that comes to mind is data. How the amount of input and intermediate data scales (or does not scale), where it is stored, how it is used, etc. Will this be a theme of much importance in the scope of this course?
This comment was marked helpful 0 times.

How does a parallel programming language work? Since all programming languages are just converted into assembly, does that mean assembly languages for computers with multiple cores have special instructions that allow parallelism?
This comment was marked helpful 0 times.
@sbly There are extensions to the x86 instruction set; the first was 3DNow! introduced by AMD. Intel responded with SSE. These instruction sets provide SIMD (Single-Instruction, Multiple Data) based instructions.
The idea behind SIMD is that one instruction can be executed on a sequence of data (eg a mapping function is applied to a sequence of elements; the mapping function doesn't change, only the data).
These instruction sets provide vector registers and instructions to handle both scalar (ie single variables) and packed (ie sequences of values) types. Here's an example (taken from wikipedia), where we want to add two 4-component vectors. The first code snippet is the operation we want to perform; the second is the x86 code generated (in the SSE instruction set):
Python:
vec_res.x = v1.x + v2.x;
vec_res.y = v1.y + v2.y;
vec_res.z = v1.z + v2.z;
vec_res.w = v1.w + v2.w;
movaps xmm0, [v1] ;xmm0 = v1.w | v1.z | v1.y | v1.x
addps xmm0, [v2] ;xmm0 = v1.w+v2.w | v1.z+v2.z | v1.y+v2.y |v1.x+v2.x
movaps [vec_res], xmm0
Most languages (eg C) aren't very 'parallel-code generation' friendly (that is, the compiler typically will not recognize that SIMD can be exploited in the code). To get around this problem, we typically use parallel languages such as CUDA, OpenMP, etc, where users can explicitly state that parallelism exists through the means of language-specific keywords (which just translate to the instructions in the x86 instruction extensions mentioned above).
This comment was marked helpful 1 times.

One thing you might have to consider when you need to make scalable code is that most programs are only scalable up to a certain point because only certain sections are parallelizable. So instead of just decomposing the existing code into independent pieces, you might have to rewrite the code to be more parallelizable, even if that makes the code "ugly" and unintuitive.
This comment was marked helpful 0 times.

@arjunh So are there any languages that automatically 'parallel-code generation' friendly? And what occasion do these languages be used at? Since it seems to me that for compilers the detection of 'parallel capable' in higher level codes is not that hard.
This comment was marked helpful 0 times.

Furthermore, where do functional programming languages fit in to this discussion of languages that are able to recognize parallel code? For example, does the SML compiler automatically assign expressions to run on different threads based on various dependencies in the program? I would imagine that this is the case since functional languages are referentially transparent and side-effect free, a perfect combination for parallel execution.
This comment was marked helpful 0 times.

There are languages that are inherently parallel like Haskell. While I do not know about the specifics of how Haskell implements this, one can read more about it here: http://www.haskell.org/haskellwiki/Parallel
SMLNJ is not parallel at all although I believe Mlton is. It is difficult to make a blanket statement about how functional languages are referentially transparent and side-effect free since SML is a clear counter example to both of them. However, we do see that Haskell has provided an interface for executing parallel code depending on whether it involves IO or non-IO. So we presumably, the implementation of this parallelism takes into account the lack of side effects in the code block
This comment was marked helpful 0 times.
Divide and conquer is just naturally a means of writing parallel programs.
This comment was marked helpful 0 times.


Question: It is common (but quite imprecise) to use the terms efficiency and performance interchangeably in discussions of parallel programming. Also, we often hear students use the term "speedup" to generally refer to a parallel program "running faster" (It sped up!). These terms are related but actually mean different things. How are the terms performance, efficiency, and speed-up different and related?
This comment was marked helpful 0 times.

The concepts of work and span, which should be familiar to you from 150 and 210, are important to keep in mind here. The total "work" done by a program is the total amount of computation done by all processors, whereas the "span" of the program is the length of the longest chain of operations that must be done sequentially.
In the more algorithmically-focused 150 and 210, you mostly assumed you had an idealized infinitely-parallel machine and tried to minimize span when possible. We'll talk about some difficulties with this approach in real programs, including some cases where it's beneficial to increase the total work of the program to reduce the need for communication between different processing units.
This comment was marked helpful 0 times.

In class, we discussed the "2x speedup on a 10 core machine" in the context of "would your boss fire you or give you a raise with this result?"
There were justifications on both end of the spectrum --
"Fire you" -- If the program has the potential to be more parallel, then 2x on a 10 core machine could be a waste of resources. This speedup may not be worth the resources, especially if speed is not important, yet cores are expensive.
"Give you a raise" -- If cores are cheap, and/or the speedup is valuable. The example given was a 2x speedup with stock trading, where this increase in speed may result in "billions of dollars of profit". This would probably be worth the cost of a 10 core machine, even though it is not executing at full efficiency.
This comment was marked helpful 0 times.

Here is how I currently view the above terms.
- Performance: An absolute measure of speed (ie. execution time/problem size)
- Efficiency: Speed-up/#processors
- Speed-up: As given in class, [Execution time with 1 Processor]/[Execution time with P processors]
This comment was marked helpful 0 times.
Question: According to the definition of speed-up, the speed-up is bounded by the # of processors. (equal if we assume there's perfect distribution of work and no communication overhead.) Does this mean for a really slow algorithm can only get linear speed-up?
This comment was marked helpful 0 times.
@lixf I believe that the constraint is tighter than that; while an increase in the number of processors (assuming perfect distribution of work and no communication overhead) will yield speedup, there is a bound given by Amdahl's Law. The law essentially states that the speedup for a program is bounded by the fraction of the program that is inherently sequential (ie there are dependencies in the code that prevent parallel execution).
For example, suppose that 25% of our program is inherently sequential, while the remaining 75% is parallelizable. If we have enough processors, we could theoretically perform the parallelizable portion completely in parallel. However, the remaining 25% of the program has to be done sequentially. This bounds the speedup by 4x; no matter how many processors you utilize, your speedup will be no better than 4x.
This comment was marked helpful 1 times.
Question: I'm still not sure about how are we measuring efficiency. Isn't it related to the percentage of the resources used in a specific period of time? Let's say you are doing video processing and need to deliver 30fps, and you can achieve that with a slow processor working 100% of the time period, or with a faster processor working 20% of the time. Isn't the slow processor more efficient? (the faster processor would use more power, to begin with...)
This comment was marked helpful 0 times.
@aaguilet: I think efficiency, just like in physics, is a term measuring (amount of work done)/(prices paid doing the work). So the way of computing the prices paid matters. In your case, if we take the money paid for processors as the price, and the fast processor is only 2 times expensive, the slow processor still has lower efficiency (the fast one could do other work meanwhile).
This comment was marked helpful 0 times.

They way I like thinking about the terms is as follows...
Performance - Performance is how much work was accomplished within a given time and resources. So for instance, if you have a job and your boss has to measure your performance, he will look at how much you work you have completed in the given deadlines(time constraints) and resources that he has given to you
Efficiency - I think efficiency is a measure of how many resources you need and the benefit you get by using that many resources. So as someone mentioned, it is the speed-up divided by the number of resources used to complete the job.
Speed-up - As defined in lecture the speed up does not refer to if a job runs faster but it compares the execution time with one processor in comparison with p processors.
This comment was marked helpful 0 times.
Efficiency can be thought of as work done per unit resource. That resource might be money, transistors (chip area), power expended, etc.? Whatever the case, a program is efficient if it is doing more with less.
This definition goes beyond the domain of computing for sure. For example, when you are efficient with your time, it means you got a lot done in a fixed amount of time. Example: "Wow, I had a really efficient day today. I wrote five comments on the 15-418 web site!"
This comment was marked helpful 1 times.

an interesting example that utilize the efficiency in term of cost, among other resources, is the MapReduce programming model. It only depends on commodity machines and is highly scalable.
This comment was marked helpful 0 times.
Question: If Performance means the workload done by given amount of time / resources, then isn't that Performance works the same with Efficiency? If the only difference is Efficiency implies the work done per unity resource.
This comment was marked helpful 0 times.

This ambiguity is why I prefer kkz's definition of performance, which I understand as a measure solely of the time taken for a program to complete on a given workload. We can improve the performance of a program on some workload by giving it more resources, without changing the program itself. We can make a more efficient program by changing the code itself to make better use of resources.
This comment was marked helpful 0 times.











The first thing I thought about when I saw this slide was hyper-threading. From my understanding, hyper-threading is just an implementation of a hardware processor core to allow for superscalar execution. Each processor core has 2 independent (computationally) logical processors on the same core, which allows for executing more instructions in parallel even if there is only 1 processor core. http://en.wikipedia.org/wiki/Hyper-threading There are other variations to modern processor implementations that allow for more ILP, but it seems to be incredibly difficult to find improvements in this area. Since companies are tying more cores together (thus increasing hardware parallelism), it makes sense to me that the idea of improving software parallelism has more potential than improving hardware parallelism.
This comment was marked helpful 0 times.

While reading the article you mentioned and looking at some further information about hyper-threading, I feel like is is more similar to multi-core parallelism rather than ILP. My understanding of Hyper-threading is that the OS sees multiple processors for each processor core but each of the hyper-threading units share an execution unit but they can load resources in parallel. Here is one source I looked at:
http://rti.etf.bg.ac.rs/rti/ir4par/materijali/
This comment was marked helpful 0 times.
@pwei, @vrkrishn, I can clear this up. Take a look at this post for a good description of Hyper-threading.
This comment was marked helpful 0 times.

I was wondering how much of a role compilers played in finding instructions that could benefit from ILP, and found this (potentially outdated) article: http://www.hpl.hp.com/techreports/92/HPL-92-132.pdf
The article talks about how both compilers and processors identify ILP, but mentions that compilers cannot directly communicate these locations to hardware and can only order instructions to facilitate their discovery (see page 10). Has this changed much since the article was written, aside from SIMD instructions? It seems like it would be beneficial!
This comment was marked helpful 0 times.
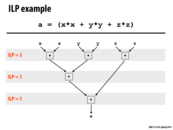
Question: If you were designing a superscalar processor that only had to run the program on this slide, how many instructions per clock would you design it to support? Why?
This comment was marked helpful 0 times.

I think 2 is enough, need 3 cycles and good usage.
This comment was marked helpful 4 times.

I agree: two instructions per cycle is the minimum amount of parallelism required to run the program as fast as possible (3 cycles), so supporting any more than that would be needless complexity.
This comment was marked helpful 3 times.

I was interested in how this would scale, so I looked it a little bit (i.e. if your program is the sum of the squares of k numbers, how does the minimum instruction per clock that lets you achieve the fastest time, scale with k? (in this example k = 3, mipc = 2)
The first few are pretty easy to calculate:
1:1
2:2
3:2
4:4
Which suggests a pattern (1, 2, 2, 4, 4, 4, 4, etc.)
If this pattern held for k = 5, the mipc for fastest runtime would be 4. But I don't think that pattern actually holds - the best you can do with 5 numbers is 4 steps (step 1 square all numbers, step 2 add 2 pairs of them, steps 3 and 4 finish the addition), but you can achieve this with only 3 instructions per clock:
Step 1: aa, bb, cc
Step 2: dd, ee, aa + bb
Step 3: dd + ee, aa + bb + cc
Step 4: aa + bb + cc + dd + ee
Can anyone come up with a consistent pattern for the scaling of mipc that does hold? (also, how does math notation work in this comment system?)
This comment was marked helpful 0 times.

@retterermoore This is a good question to think about. It might also be good to think about what other concerns might arise as you increase k. Would other properties of the hardware begin to become more important? What kind of assumptions that are valid when k is 5, versus when k is 10000 (perhaps in terms of how to get hold of the data in x, y, z, ...)?
As for your question about markdown, be sure to check out the markdown tutorial for a brief overview.
This comment was marked helpful 0 times.

So one thing that's important for the pattern is that the number of steps will increase by one every time a new power of two is passed. That is, when at most 4, there are at most 3 clock steps needed (probably a bad term for it), where at 5 there are 4 needed, and at 9 5 are needed by properties of logs and trees.
Also, when we have a power of two as our number of values, we need enough instructions in a clock step to calculate all of the squares in a single step. So 16 would need 16 instructions per clockstep available to complete in 5 steps.
I'm not entirely sure how to generalize from here, though. It's clear that for any n, we need at most n instructions per clock step and lg(n) steps in order to complete the problem, but I'm not sure how to reduce the number of instructions per clock step needed further.
This comment was marked helpful 0 times.

I don't quite get the answer to the question. Can someone clarify how the answer of 2 instructions per clock cycle was arrived? What does minimum instructions per cycle exactly mean?
This comment was marked helpful 0 times.

@ruoyul Someone can correct me if I'm wrong, but there are a total of 6 instructions. As we can see, the (xx) is independent from (yy) which is independent from (zz). So we could have 3 instructions per clock cycle. But looking at the next step, we see that in order to add all of these three quantities together, we must first add (xx) then (yy) before we can additionally add (zz). This would mean in the second and third cycles, we would have the capability to read in 3 instructions, but we would actually only be performing one instruction. So going back to the first step, let's have only two instruction reads per clock cycle. Thus we can assign the work in the following manner:
Cycle 1
(x * x)
(y * y)
Cycle 2
(z * z)
(x * x)+(y * y)
Cycle 3
(zz)+(xx)+(y*y)
Comparing vs the 3 instructions per cycle we see
Cycle 1
(x * x)
(y * y)
(z * z)
Cycle 2 (x * x)+(y * y)
Cycle 3 (z * z)+(x * x)+(y * y)
Having more than 2 instructions per cycle would also unnecessarily complicate the design and not be as optimal as we would like as @yanzhan2 and @mchoquet pointed out. And so minimum instructions per cycle means what is the fewest amount of instructions we execute per cycle so that we maximize parallelism.
This comment was marked helpful 0 times.


Although the logic behind the slide makes sense as given in lecture, how reliable is this data if it's from a survey of programs in 1991? Compilers have definitely changed in the last twenty years.
This comment was marked helpful 0 times.
@wrichto, this is a good question. Keep in mind this not a situation of a compiler finding the parallelism and automatically generating parallel code. Instead, this chart plots the benefits of superscalar logic in a processor when running instruction streams from a benchmark suite. This logic must inspect an instruction stream and then analyze instruction dependencies in order to find independent work that can be executed in parallel. As a CPU tries to fill more and more execution units (as we move down the X axis of the graph), it has to work even harder to analyze the program to find work (look over a wider and wider window of future instructions). At some point, even if a program had a lot of parallelism, there's more cost put in to analyze all the dependencies than to just run the code!
Of course, instead of having a CPU find the ILP dynamically, a compiler could analyze the code off-line, and generate explicitly parallel instructions for a processor to execute, such as is the case in a VLIW architecture. Even so this is a very difficult problem that has not yielded much success. There simply isn't much local parallelism in most instruction streams, and trying to find global parallelism in software written in a C-like language remains an open research problem.
That doesn't mean there's not much parallelism in programs, it's just hard for compilers and processors to find it unless they are given really strong hints. It is simply much easier to have the application developer explicitly parallelize code, or write in a constrained programming model where the parallelism is easy for compiler/architecture to find (you will write code in such models in all assignments in this class).
Of course, having to thinking about parallelism usually makes things harder on the application developer though, one of the reasons why 15-418 exists.
This comment was marked helpful 1 times.
Yihua mentioned super linear scaling to me in a piazza post (The ability to reach a speedup of greater than p when there are only p processors used - http://en.wikipedia.org/wiki/Speedup#Super_linear_speedup. I'm slightly confused on how this procedure works. Can processors easily access caches associated with other processors? And if not, wouldn't there be a good amount of communication overhead (figuring out if certain information exists in any one of the p caches)?
This comment was marked helpful 0 times.
This graph is a bit confusing...why is this the case? What is the main reason for preventing further speedup utilizing more ILP per processor?
This comment was marked helpful 0 times.
@DunkMaster. Real-world programs don't have large numbers of independent instructions, so those extra units often have nothing to so. (insufficient parallelism in an instruction stream).
This comment was marked helpful 0 times.
Kayvon mentioned VLIW architectures so I thought I'd leave this link about The Mill CPU. The Mill CPU replaces stacks and registers with something called the "belt". Every cycle the CPU starts multiple instructions with operands from the belt and when they're finished they push the result on the front of the belt. It's a really interesting concept and I'd definitely encourage reading about it.
This comment was marked helpful 1 times.


The green line represents the benefit of using smaller and smaller transistors, which can fit more on a chip. As indicated in the graph (with a logarithmic scale on the vertical axis), this is currently the way speedups are being achieved as technology is developing, as the other curves have pretty much leveled off. Writing good parallel software, then, is becoming increasingly important as a way to utilize more chips rather than making a single chip faster.
This comment was marked helpful 0 times.

As someone who doesn't know a lot about computer hardware, it was unclear to me in lecture why the use of smaller transistors is related to having more processors. I understand that more processors means more potential for speedup with parallelism, but I'm not quite clear on what a transistor is and why smaller ones enable more processors and better performance in a machine. Can someone explain this concept?
This comment was marked helpful 0 times.

@arsenal Having smaller transistors lets you fit more of them in a processor without increasing its size. Having more transistors is what gives you better performance: more transistors let you have more cache, increase throughput, etc. Having smaller transistors also means that you can make each core small enough such that you fit several in one processor, thus allowing for multi-core processors without needing more physical space.
This comment was marked helpful 0 times.
@arsenal: A transistor is simply a semiconductor device, used primarily to amplify and switch signals and electrical power. The actual working of a transistor is fairly complicated and depends on the model (such as BJT's or MOSFET's). In general, however, you make use of doped semi-conductor materials (such as germanium, silicon, etc, with added impurities to given them conductive properties) to control the direction of electric current. This is explained in much greater detail here.
The creation of smaller transistors doesn't mean that they are substantially less powerful than their larger counter-parts; it means that it is possible to place more transistors in a given chip (i.e., increase in transistor density). These transistors can be used for a multitude of purposes, ranging from improving the power of the ALU's, such as local cache memories, prefetchers, branch predictors and other components.
Of course, more transistors doesn't translate to better performance; a higher transistor count also results in more heat dissipation, which is one of the barriers to improvements in chip design.
This comment was marked helpful 0 times.
In class we discussed how power limits caused frequency scaling tapped out (power increases non-linearly). But this chart's green line shows the transistor size continues to shrink. Chip architects are increasingly choosing to turn these extra transistors into more processing cores per chip (rather than more advanced features in a single core, such as wide superscalar execution).
Not discussed on this slide or in lecture, but for the interested...
Until recently, shrinking transistor size implied lower-power transistors. That is, as technology progressed you could cram more transistors onto a fixed area of silicon and when using all those transistors, the chip consumed about the same amount of power. This is referred to as Dennard Scaling. However, it is possible we may reach a point where this is no longer the case---as voltage cannot be dropped further without reaching a point of transistor reliability. That is, we could place increasingly more transistors on a chip, but it may soon be possible that we use them all at the same time!
For those that want to learn more, you might enjoy this paper, which triggered a bit of discussion and controversy: Dark Silicon and the End of Multi-Core Scaling or Power Challenges May End the Multicore Era. But don't let the pessimistic titles get you too down!
This comment was marked helpful 0 times.

I remember in lecture someone said that the speed of light can be a potential barrier to processor speed. Can someone elaborate on this?
This comment was marked helpful 0 times.
Going back to transistors, for example, we know that their states are essentially altered by the current which sets the input voltage of the transistor to the appropriate value. By "states" I mean the output of the transistor (for digital model "high voltage output" = logic 0 & "low voltage output" = logic 1). The faster the current passes through to change that input voltage, the faster the transistor would output the right value, so technically, the faster our processor would work.
So what is that current? Basically, it's just the flow of electrons through wires or metal on a chip. However, as they travel through, they will meet some form of electrical resistance that is intrinsic to the material it's going through, that will consequently "slow them down". But what if we develop that material to have less and less resistance so the electrons pass by faster and faster? Ultimately, nothing (yet) is faster than the speed of light, thus if we manage to transfer information at the speed of light, we would sort of hit a dead end...
This comment was marked helpful 0 times.

Are we going to be able to keep the increasing trend of the green line for a foreseeable future? What are some of the barriers that may hinder the trend, and what are some potential solutions if there are indeed barriers?
This comment was marked helpful 0 times.
There are bunch of factors that could potentially mess with Moore's law such as ways of actually making the smaller transistors, speed of light, power, I guess. This is a brief summary of Moore's Law and current, past and future technologies, if you're interested.
This comment was marked helpful 0 times.

Smaller transistors also lead to faster transistors. In a FET transistor, the gate is essentially a capacitor. The smaller the physical gate is, the lower the capacitance is, and the faster the gate's charge can be changed, so the clock speed can increase
Another way to increase the speed of a transistor is to increase the drive voltage, but this leads to increased power consumption.
This comment was marked helpful 0 times.

Speaking of problems that arise with tiny transistors, I remember reading an article a while (5+ years) back about potential problems as transistors get smaller. If I recall, one potential problem is that as chips get denser, the amount of air between electrical pathways on the physical chip gets so small that you might have short circuits. I'll see if I can dig up more later.
Actually, I just noticed one of the slides in the link @selena731 posted is about this.
This comment was marked helpful 0 times.

How would something like quantum computing affect this chart and how we think about parallelism?
Edit: I guess what I meant by this is that in quantum computing, we have qubits instead of bits, which can be the superposition of several states. It seems to me that such a representation can be used to further parallelize programs or process more at a time, as yet another implementation to an abstraction over parallelizing programs. If this is true, and quantum computing becomes something more than just research, then I wonder how its performance will compare against this graph.
This comment was marked helpful 0 times.

@sluck As far as my research into quantum computation has gone, parallelism would not effect it very much, but distributed computation would. The largest factor against quantum computers right now is noise, which can render a computation useless. This noise can be created from literally anything getting into the computer. Therefore, these machines would likely need to be separated quite a bit, meaning that a distributed system of them is much more likely to exist.
However, when you can search an unsorted list in $O(\sqrt{n})$, anything is possible =P
This comment was marked helpful 0 times.


Why do the CPUs cap out at 95W while the GPUs cap out at 250W? If the GPUs are not melting why would more power melt a CPU. It seems almost as if the GPUs are pushing the boundaries of power consumption more than CPUs. Can they not continue to increase power consumption and clock frequency in CPUs?
This comment was marked helpful 0 times.
We will cover this in more detail in future lectures so hopefully you will be able to answer your own question in a few weeks. To give you some idea of what to think about, know that GPUs are designed to solve specific types of parallel workloads and so they can make a bunch of assumptions about what type of programs they should optimize for. On the other hand CPUs are still designed to solve problems in a world largely dominated by sequential code and should perform well on any reasonable program. With that in mind, if you know the workloads are more parallel and having the equation above, can you see how GPUs might be able to get around some of the constraints on CPUs?
This comment was marked helpful 1 times.

This is an interesting question, and I would like to know the answer too. I'll take a stab at it though, so here's my best guess:
Maybe die size has something to do with it. A Haswell CPU has a 177 mm^2 die, and a GTX 780 GPU has a 561 mm^2 die. I would assume that capacity for heat transfer (preventing the chip from melting) increases as surface area increases; or on the flip side, perhaps junction temperature increases as surface area decreases.
TL;DR: I think maybe you can pump more power into a GPU because it's easier to keep it cool.
This comment was marked helpful 0 times.
@mofarrel and @dfarrow, I'd like to hear your thoughts on this question after the next lecture.
This comment was marked helpful 0 times.

Would it be unrealistic to have some sort of "cooling units" that could keep the chips cooler so they could use more power? I'm sure people have thought of this, but I'm not sure why it's not a good idea.
This comment was marked helpful 0 times.
I would assume it's because it's just too much power. If you have a computer already drawing as much power as half a microwave and then you add and huge cooler to cool the computer, then you would be using so much energy. Energy is a resource too, so it's important to make efficient use of it.
This comment was marked helpful 0 times.
@ycp on a PC (assuming you mean something more effective than just a simple heatsink+fan) that's definitely an option; I'm thinking about liquid cooling in particular. You can actually find a liquid cooling kit for relatively cheap, $50 here, but they can get pretty expensive. I think liquid cooling is probably used almost exclusively by the hardcore-gaming/enthusiast/special-purpose market though - by those who are into overclocking and are comfortable with building their PCs from scratch.
For mobile phones, tablets, etc., I think we're pretty much stuck with passive cooling, and it is hard to want to overclock my phone when my hand is the heatsink.
This comment was marked helpful 2 times.
The bigger the surface it has, the easier it will be cooling down. But modern computer industry is pursuing smaller chips, which increase the difficulty to cool down.
This comment was marked helpful 0 times.
@ycp When people push the limits of chips, they frequently use super cooled liquid gases.
This comment was marked helpful 0 times.

With the increased use of centralized data centers that keep servers cool on a massive scale and allow distributed computing over a network instead of computing everything locally, would this mitigate the need to worry about power consumption and cooling individual PC's and their chips?
This comment was marked helpful 0 times.
@kayvonf, I'm still not entirely certain why there's such a large TDP difference between consumer CPUs and GPUs. I'm trying to think in terms of architecture now. I guess the question is: how does one architecture (GPU) allow the chip to have a higher TDP without melting than another (CPU). I totally appreciate that the GPU is executing a ton of instructions simultaneously, so it makes sense that it would give off more heat than a CPU would per cycle. But it seems to me like the TDP of a processor shouldn't depend on the specific architecture of that processor, but rather on how much power you can give it without it melting. Which leads me to the "greater surface area = more heat transfer = higher TDP" theory. Any other hints?
This comment was marked helpful 0 times.

I can't see the relationship between the frequency and voltage in the formula. Power is a linear function to frequency. And quadratic to voltage. How is voltage and frequency related?
This comment was marked helpful 0 times.

@paraU There is not a direct relation between voltage and frequency. You can scale the frequency of a processor independent of the voltage. However, the peak frequency of the processor is decided by the voltage, as you can tell from slide 28. If the frequency is set above peak frequency, the processor can malfunction due to circuit failure.
This comment was marked helpful 0 times.
@dfarrow Since GPUs do not have the same requirements with respect to sequential performance, can you think about what kind of constraints on CPU manufacturers have been lifted for GPU manufacturers? Think about why GPUs can afford a larger surface area.
This comment was marked helpful 0 times.

CPUs, due to their need for higher sequential performance, need to run at much higher clock rates than GPUs. How does this link to running hotter though? It doesn't seem that CPUs run at significantly higher voltages than GPUs.
This comment was marked helpful 0 times.

?If this comment is not too late? In Cloud Computing Course, we learnt about that cost by the cooling system for a data center is significant; so I am thinking about what are the key tradeoffs here? (Heat-generation VS Frequency VS Number_of_Cores ?)
This comment was marked helpful 0 times.
The fact we know is the expense from cooling system of a data center is a significant portion of the total expense. So that anyone could share the idea of key tradeoffs here?
This comment was marked helpful 0 times.

@Benchoi TDP isn't directly linked to temperature. CPUs and GPUs actually run at similar temperature (around 65 C). TDP stands for Thermal Design Power, and it is a measure of how much power in watts is being dissipated by the chip via heat energy. While at any single point the temperature of a CPU or GPU are the same, because the GPU is larger, its surface is collectively dissipating more heat energy. Additionally, while TDP is a measure of heat energy it is also strongly correlated to power consumption by the chip, due to energy conservation laws.
This comment was marked helpful 0 times.
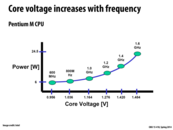


Intel's new Haswell architecture, which stresses low power consumption, is built for mobile devices. Does the development of low power chips help frequency scaling? How does this relationship work? (I'm guessing there are diminishing returns in power reduction as well.)
This comment was marked helpful 0 times.
@bwasti Your question is unclear to me, I think you are confused about the relation between P(ower), V(oltage), and f(requency). As stated in slide 27, P is proportional to V^2*f. In addition to that, f(peak) of a CPU is proportional to V. So if you set a CPU at its peak frequency (why not), its frequency (read performance) is proportional to V, while power consumption is proportional to V^3, its efficiency goes down by V^2. As you can see, the performance and the efficiency of the CPU are both decided by the voltage applied to it. As a result, using an ultra low power CPU is not a solution to improve performance, but in fact a compromise to battery life, CPU efficiency, and cooling. I hope this helps answering your question.
This comment was marked helpful 0 times.

I don't quite understand how low-frequency multi-core processors are faster than extremely high-frequency single-core processors. They would might give better user experience when the user runs multiple programs on his/her PC. If we just compare single cores from each type of processors, high-frequency single-core processor would win. I would need some more elaboration on the phrase "Architects are now building faster processors by adding processing cores" in the lecture slide.
This comment was marked helpful 0 times.
@taegyunk: I think if there is only one thread running, the single core must win. But this is not the case: OS already has many processes running together, and let alone the applications. Furthur more, we can now parallelize our traditional programs to get a speedup.
This comment was marked helpful 0 times.
@taegynk: The main idea is that computer chip architects are now using the extra transistors provided as per Moore's Law to add additional cores to chips, rather than making the pre-existing cores more powerful.
A powerful single core would have numerous facilities to speed up the parts of its execution (namely the process of fetching/decoding instructions, executing them and storing those results in registers). For example, you could have a smarter fetching mechanism, which can determine if there is ILP in the instruction stream, or you could have a caching facility to store frequently used values that can't fit in the set of registers.
Instead of going for these single-core enhancements, chip architects today instead decide to use the extra transistors to add extra cores. This means that any single core on a chip with multiple cores is less powerful than any single core on a chip with one enhanced core. However, in practice, chip designers are realizing that the extra parallelism realized by using multiple cores leads to significant speedup; it's now up to programmers exploit these extra cores with code that can be readily parallelized, with as few overheads as possible.
This comment was marked helpful 0 times.
@taegyunk: Consider the following case. Let's say the Pittsburgh airport is expecting a huge crowd of CMU students trying to get out to the west coast ASAP because they want to join Nest before it gets sold to Google for $3.2B dollars. (Oops, too late!)
You are the security manager of the airport, and you have funding budget of \$50/hr to pay all your TSA workers at the security check. You can tell worker A to come to work, who is a top-notch senior employee and can get 100 people through her line in an hour. However, due to her seniority and consistently high performance, she makes \$50/hr. Or you can tell workers B and C to come to work who are less experienced, and can only get 75 people each through their lines an hour. However, since they are new they each make only make \$25/hr.
Who do you tell to come to work today?
This comment was marked helpful 3 times.
@kayvonf: Definitely, hiring two less experienced would be better and that explains well! Thank you!
This comment was marked helpful 0 times.
Transistors are still shrinking, so we can use more transistors on a single chip. This makes sense. Then we have two choices, on a single core or multi cores. The answer is multi cores because with multi cores we can do multi tasks at the same time. But my problem is what is the relationship between transistor numbers and core performance. In my understanding, core performance is only correlated with frequency. But I'm quite curious about what the core would be if we give it more transistors.
This comment was marked helpful 0 times.
@paraU If you recall slide 22/23/25, other than frequency, performance is also related with ILP. Here is an equation that explains this:
Instrs/Second = (Instrs/Cycle) * (Cycles/Second)
Performance = ILP * Frequency
Given a single application, the processor's architecture decides how much ILP it can exploit. And more transistors are always a trade off for better architecture. Recall the example from slide 25, processing more instructions per cycle can improve ILP, however, it requires additional logic (implemented with transistors) to process multiple instructions. And the complexity of these logic increases exponentially with ILP it can exploit because you need to handle dependencies among more instructions.
This comment was marked helpful 0 times.

I'm sure I'm way oversimplifying things, but here's my understanding: with, say, a 22nm process, Intel figures it can put 1.5 billion transistors on a chip. To keep energy consumption and heat dissipation down to something reasonable, they can't possibly push the chip's clock speed past 3.5 GHz. But the wizards at Intel can basically divide up their fixed number of transistors into some combination of redundancy (for parallelism) and features (like dedicated hardware for specific operations and quicker fetch/decode logic.)
Here's my question, though: if there are some applications that are stubbornly serial, why doesn't Intel have any processors that devote practically all available transistors to single-threaded performance? It seems like the fastest single-threaded performance you can get from Intel today is in the i7-4960X, a 6-core chip! Turbo Boost can turn off the 5 unused cores and overclock the remaining core when doing serial-heavy tasks, but wouldn't that speed bump pale in comparison to the benefit of 4 of 5 cores' worth of extra transistors? I get that more and more programs are written for parallel processors, but would it be fair to say Intel has forsaken the ones that don't?
This comment was marked helpful 1 times.


I agree that parallelism seems to be one of the best ways to achieve higher performance. A great example would be the PS Vita. It has a quad core processor, compared to the single core processor of its predecessor (PSP) and as a result, it is capable of producing graphics near the level of a PS3 without any lag or delay whatsoever. The nintendo 3DS also has a dual-core processor and so does the iPhone 5S (which apple claims to be the fasted phone on the market, maybe not but it is still pretty darn good). The iPad has dual core CPUs and quad-core GPUs. All of these handheld devices from phones to tablets to gaming devices are only getting better and better through 1 main reason : multi-core processors. However, i do have one question, is the focus more towards upgrading GPU's or CPU's when it comes to multi-core faculties. It seems to be different for the various devices. The 3DS and PS Vita seem to like have a quad-core CPU but apple seems to like having the quad-core graphics more. Which would be better in the future?
This comment was marked helpful 0 times.
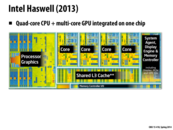

Although there are benefits and trade-offs to having more/fewer levels of caches, why would Intel settle on 3? I would think that the cost of cache coherence is very high, but at the same time memory accesses are huge bottlenecks in program execution so having more caches may be worth it.
This comment was marked helpful 0 times.
@bxb Having multiple levels of caches presents a trade off between (small,fast) and (big,slow). A bigger cache gives you higher chance to hit, but also has higher cache access latency (it takes more cycles to transfer cache lines to the core).
Also, using larger cache has diminishing return on hiding memory latency. As you will see in future lectures, there are other ways to hide memory latency. For example, GPUs do not use large cache, instead, it uses a large number of threads to hide memory latency.
This comment was marked helpful 0 times.

Just out of curiosity, are there any other chips anywhere that have different cache structures? More than 3 layers? Less than 3 layers? Why might that be the case?
This comment was marked helpful 0 times.

The (former) Crystal Well variant of Haswell has a fourth cache level. It's a "victim cache" for the L3 cache: a fully associative cache that only stores memory that has been evicted from the L3 cache, in order to optimize the small set of memory usage that actually is faster with full associativity.
For some other examples, see http://en.wikipedia.org/wiki/CPU_cache#Cache_hierarchy_in_a_modern_processor
This comment was marked helpful 0 times.

There are also chips with L2 cache but no L3 (definitely lots of very old ones, and it looks like probably recent Intel Atoms do as well?). This is presumably primarily from cost issues...
This comment was marked helpful 0 times.


It was mentioned that the GPU has thousands of cores, in constrast to current CPUs which have a much smaller number of cores (i.e. 4 or 6).
The reason for this, as Nvidia puts it, is that the cores in the GPU are smaller and more efficient, and designed to handle multiple tasks at the same time. On the other hand, the fewer CPU cores are optimized for more sequential processing.
This comment was marked helpful 0 times.
@RICEric22. I'll address this in class on Wed.
This comment was marked helpful 0 times.

As @RICEric22 has mentioned, GPU's and CPU's are optimized for different kinds of tasks. Today, GPU and CPU are used together (general-purpose computing on graphics processing units also known as GPGPU) to take advantage of the two different optimizations they provide. While the GPU handles parallel computation, the CPU handles sequential computations.
This comment was marked helpful 0 times.

@ffeng To expand your idea into a more general idea, putting GPUs and CPUs together into one computer system is a form of heterogeneous computing. The idea is to utilize different computing components/units in one system and allow each units to be specialize to a particular task and therefore can get the most efficiency out of the whole system. This idea is a result of the need for high performance computing when we hit the power-wall.
There will be at least one lecture dedicated to heterogeneous computing later in the course.
This comment was marked helpful 0 times.
Wondering if it possible for the future computer to have a simple CPU and carry out most of the computations on the GPUs.
This comment was marked helpful 0 times.

@DunkMaster thats a good question but I would be a bit skeptical about that since the cores in the GPU are already simple cores. My thought is that somewhere in the system you must have complex cores capable of executing sequential code very fast since at times you have no choice but to execute code serially.
This comment was marked helpful 1 times.


How does power constraints influence mobile system design? From these two designs, I think maybe NVIDIA uses a more powerful core and Apple A7 uses more lower power cores? Is this slide an example of slide 29?
This comment was marked helpful 0 times.

What I find really interesting about the Apple A7 is that it includes multiple 'sections' within it. Not just does it contain the processor, it also contains the 'enclave' that stores the fingerprint data for the iPhone 5s, and also the activity tracking chip too.
This comment was marked helpful 1 times.
@jinghuan This is not related to the idea presented on slide 29. This slide presents a trade off in system design in the context of mobile where power efficiency is crucial. Apple uses only dual-core, yet the entire system performance can rival that of a system with quad-core. On the other hand, a dual-core consumes less energy than a quad-core. As @idl mentioned, Apple builds many specialized circuitry such as activity tracking inside to compensate for the performance lost from using a dual-core.
This comment was marked helpful 0 times.
In situations like these where saving energy is a high priority, do processors still do things like run all arithmetic operations every clock cycle? Is that at all more expensive than running only one?
This comment was marked helpful 0 times.


Could having so many processors possibly lead to a performance problem for some specific problem? In the assignment 3 it was observed that having larger number of processors sometimes actually decrease the efficiency of the program. So it seems like having many processors does not always mean that it will always be better.
This comment was marked helpful 0 times.

Welcome to the Spring 2014 installment of 15-418! Please take some time to get acquainted with the course website, which allows you to comment on any of the lecture slides (and you are highly encouraged to do so!). Since this course does not use a textbook, your discussion of the slides will serve as the primary reference for you and your classmates.
I am always amazed how often the act of trying to write an idea down makes me realize I actually don't understand it, and forces me to reconsider or clarify my thinking. Here are some ideas and tips to help you make the type of comments that we would like to see. For a quick tutorial on the Markdown syntax used in comments, take a look at our 90-Second Guide to 15-418 Markdown.
This comment was marked helpful 0 times.