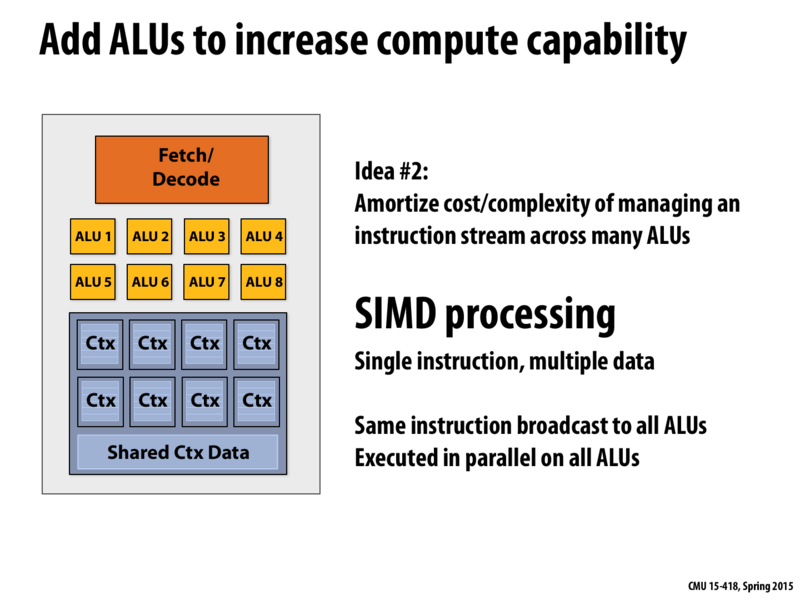
What's the reason why all of the ALUs have to be executing the same instruction? You'd figure that each ALU is capable of executing every possible instruction, and that the Fetch/Decode unit could also pass the ALU a unique instruction along with the unique data.
kayvonf
But in the fictitious processor above you only have one fetch/decode unit that decodes one instruction per clock. In other words, you have an instruction decode throughput of 1 instruction per clock. You don't have sufficient throughput to feed the eight execution units with eight unique instructions.
Note the similarity of this situation, in a sense, to the mismatched rates of bandwidth and compute capability described in the thought experiment on slide 61 at the end of the lecture.
In general, building execution units is relatively cheap. Building a memory system and instruction control paths to feed these execution units with data values and control information is costly. The key idea of SIMD processing is that there is a class of applications where amortizing instruction stream processing across many execution units is an effective optimization.
JuneBot
In the previous lecture, we saw a graph of the diminishing returns of superscalar execution. This graph had a knee at about 4 instructions per clock cycle, due to (as I understood the discussion on that slide) the fact that most benchmark programs allow a small amount of inherent parallelism; this small amount happens to max out at about 4 inst/clock. Is there a similar graph that can be drawn for the number of ALUs on a single core versus speedup? That is to say, is there a point at which some benchmark computations on data sets stop benefiting from data parallelism? Another way to phrase this question would be, if we had 1000 different processors, each with a different number (between 1 and 1000) of ALUs, which one would on average perform the fastest over computations on lots of different data sets?
rbandlam
I also similar question like @JuneBot above. Is there any hardware or data dependency constraints on number of ALU's that can exist per core? In above example, we have 8 ALU units per core.
TA-lixf
@JuneBot, @rbandlam:
The answer to your question ("...which one would on average perform the fastest over computations on lots of different data sets?") really depend on the type of benchmarks and how much parallelism is in the application.
Specifically, with the fake core above, we have only one Fetch/Decode unit and multiple ALUs, which means this core is perfect for n-wide SIMD (n == # of ALUs). Therefore, if the application makes use of this feature by issuing instructions that are n-wide vector instructions (e.g. 4 wide SSE instructions that you'll use for assignment 1), then the speedup would be pretty good.
Also, think about why GPUs have a huge number of ALUs to execute massively parallel instructions. This will perhaps help you with understanding that the speedup depends largely on the benchmark itself.
What's the reason why all of the ALUs have to be executing the same instruction? You'd figure that each ALU is capable of executing every possible instruction, and that the Fetch/Decode unit could also pass the ALU a unique instruction along with the unique data.
But in the fictitious processor above you only have one fetch/decode unit that decodes one instruction per clock. In other words, you have an instruction decode throughput of 1 instruction per clock. You don't have sufficient throughput to feed the eight execution units with eight unique instructions.
Note the similarity of this situation, in a sense, to the mismatched rates of bandwidth and compute capability described in the thought experiment on slide 61 at the end of the lecture.
In general, building execution units is relatively cheap. Building a memory system and instruction control paths to feed these execution units with data values and control information is costly. The key idea of SIMD processing is that there is a class of applications where amortizing instruction stream processing across many execution units is an effective optimization.
In the previous lecture, we saw a graph of the diminishing returns of superscalar execution. This graph had a knee at about 4 instructions per clock cycle, due to (as I understood the discussion on that slide) the fact that most benchmark programs allow a small amount of inherent parallelism; this small amount happens to max out at about 4 inst/clock. Is there a similar graph that can be drawn for the number of ALUs on a single core versus speedup? That is to say, is there a point at which some benchmark computations on data sets stop benefiting from data parallelism? Another way to phrase this question would be, if we had 1000 different processors, each with a different number (between 1 and 1000) of ALUs, which one would on average perform the fastest over computations on lots of different data sets?
I also similar question like @JuneBot above. Is there any hardware or data dependency constraints on number of ALU's that can exist per core? In above example, we have 8 ALU units per core.
@JuneBot, @rbandlam: The answer to your question ("...which one would on average perform the fastest over computations on lots of different data sets?") really depend on the type of benchmarks and how much parallelism is in the application. Specifically, with the fake core above, we have only one Fetch/Decode unit and multiple ALUs, which means this core is perfect for n-wide SIMD (n == # of ALUs). Therefore, if the application makes use of this feature by issuing instructions that are n-wide vector instructions (e.g. 4 wide SSE instructions that you'll use for assignment 1), then the speedup would be pretty good. Also, think about why GPUs have a huge number of ALUs to execute massively parallel instructions. This will perhaps help you with understanding that the speedup depends largely on the benchmark itself.