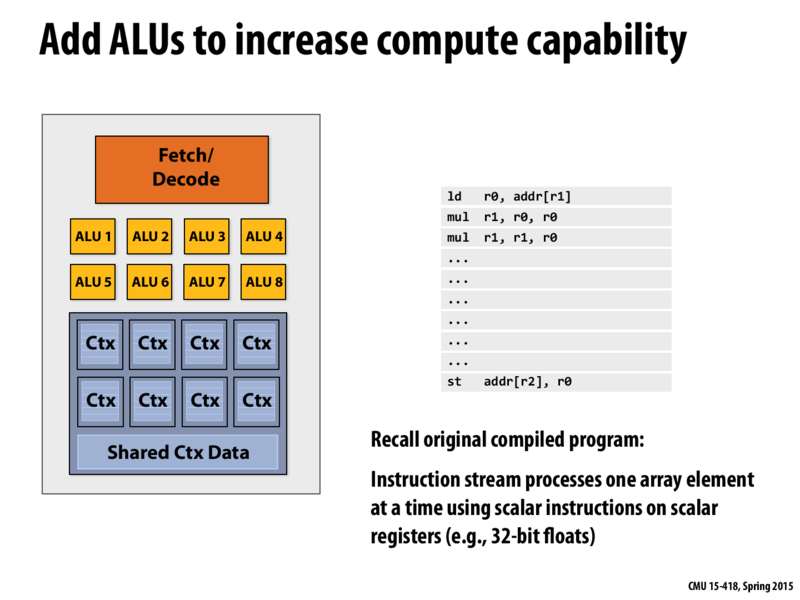
I want to make sure that my understanding of how having multiple ALU's for single fetch/decode block is helping us. If there is an array with 8 elements, i could execute same instruction but with different data element of array on distinct ALU unit of same core. So, we can decode instruction once but execute on group of data on different ALU units of same core. Is this right?
So if there is an array of 16 elements, i could execute on 2 cores since each core has 8 ALU units for each fetch/decode execution. Please correct if i am wrong?
paluri
The way I understand it, because of the multiple ALUs, you can, in effect, perform 8 different additions, for example, in the time of one instruction. And in reality, it really is just one instruction, but a special instruction that can operate independently on 8 pairs of values instead of just one pair. You are correct that it all operates on the same core.
Just as a clarification, if there are 8 binary operations (i.e. 2 operands) that you are trying to perform at once, then yes, you can do that on one core if they are the same binary operation. As further clarification, it's more than just having them in an array - I'm guessing if you looked into the AVX intrinsics library you may or may not be able to better understand what's actually happening.
afa4
@rbandlam I think your understanding is correct.
kayvonf
Here's a way to think about it that might help:
The explanation below describes SIMD processing using AVX instructions on Intel CPUs. It's what referred to as an "explicit SIMD" approach to SIMD execution on slide 34. An "implicit SIMD" implementation, discussed on slide 35 is slightly different, but I recommend understanding the explicit formulation first.
In addition to scalar registers (for example, a 32-bit float), an AVX-instructor-capable processor also supports vector registers (for example, a 256-bit register containing a vector of 32-bit values). 8-wide SIMD instructions are instructions that operate on all eight elements of the vector at once.
For example, in AVX the 256-bit registers are ymm0, ymm1, ..., etc.
The AVX instruction:
vmul ymm0 ymm0 ymm1
Performs an element-wise multiply of 8-wide vector in ymm0 and the 8-wide vector in ymm1, storing the result in ymm0. One instruction ("multiply two vectors") is fetched/decoded by the processor and the execution of that instruction involves eight multiplies, one for each vector element (aka vector "lane"). In my illustrations in this lecture, each ALU box can perform one scalar multiply.
I want to make sure that my understanding of how having multiple ALU's for single fetch/decode block is helping us. If there is an array with 8 elements, i could execute same instruction but with different data element of array on distinct ALU unit of same core. So, we can decode instruction once but execute on group of data on different ALU units of same core. Is this right?
So if there is an array of 16 elements, i could execute on 2 cores since each core has 8 ALU units for each fetch/decode execution. Please correct if i am wrong?
The way I understand it, because of the multiple ALUs, you can, in effect, perform 8 different additions, for example, in the time of one instruction. And in reality, it really is just one instruction, but a special instruction that can operate independently on 8 pairs of values instead of just one pair. You are correct that it all operates on the same core.
Just as a clarification, if there are 8 binary operations (i.e. 2 operands) that you are trying to perform at once, then yes, you can do that on one core if they are the same binary operation. As further clarification, it's more than just having them in an array - I'm guessing if you looked into the AVX intrinsics library you may or may not be able to better understand what's actually happening.
@rbandlam I think your understanding is correct.
Here's a way to think about it that might help:
The explanation below describes SIMD processing using AVX instructions on Intel CPUs. It's what referred to as an "explicit SIMD" approach to SIMD execution on slide 34. An "implicit SIMD" implementation, discussed on slide 35 is slightly different, but I recommend understanding the explicit formulation first.
In addition to scalar registers (for example, a 32-bit float), an AVX-instructor-capable processor also supports vector registers (for example, a 256-bit register containing a vector of 32-bit values). 8-wide SIMD instructions are instructions that operate on all eight elements of the vector at once.
For example, in AVX the 256-bit registers are
ymm0,ymm1,..., etc.The AVX instruction:
vmul ymm0 ymm0 ymm1Performs an element-wise multiply of 8-wide vector in
ymm0and the 8-wide vector inymm1, storing the result inymm0. One instruction ("multiply two vectors") is fetched/decoded by the processor and the execution of that instruction involves eight multiplies, one for each vector element (aka vector "lane"). In my illustrations in this lecture, each ALU box can perform one scalar multiply.