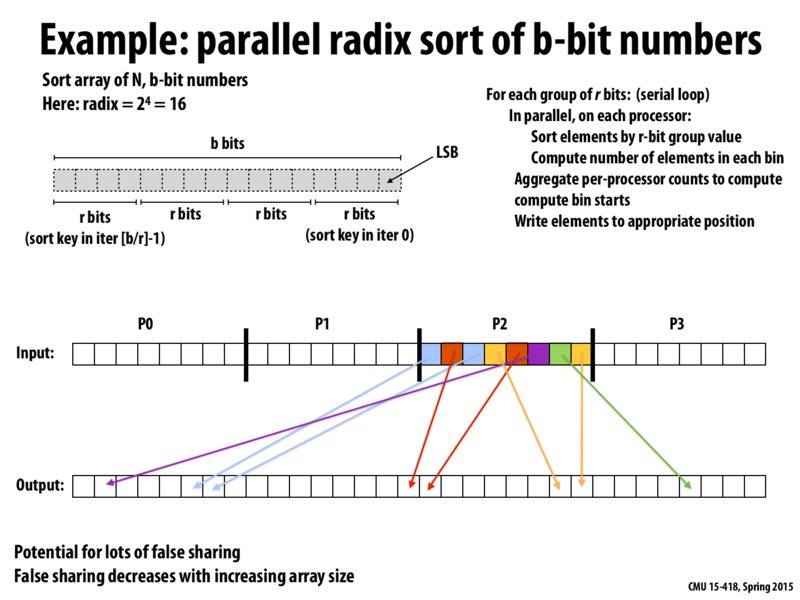
Increasing array size will decrease false sharing for elements in the input array. But false sharing will still be present for the output array, right?
srw
@afa4 I think it would have to be. We have no guarantees about the size of each bin in the output. For instance, we might have only 2 purples, 2 yellows, but 20 greens. Since we can't assume anything about the input, we can't reliably avoid false sharing in the output.
On the other hand, if we increase the array size this means each processor will be sorting more numbers on average, even in the output array, so we should expect less false sharing on average for a random input.
russt17
In the lecture video Kayvon said that for this algorithm increasing number of processors increased false sharing, and increasing the array size N decreases false sharing. I didn't understand the explanation of why, can anyone explain? Is the false sharing just happening on the edges between the processors, and the lower the data-per-processor ratio is the more elements are near the edges? Couldn't you just divide up the data slightly unevenly so that each processor had a chunk of the array that doesnt fill a partial cache line?
Increasing array size will decrease false sharing for elements in the input array. But false sharing will still be present for the output array, right?
@afa4 I think it would have to be. We have no guarantees about the size of each bin in the output. For instance, we might have only 2 purples, 2 yellows, but 20 greens. Since we can't assume anything about the input, we can't reliably avoid false sharing in the output.
On the other hand, if we increase the array size this means each processor will be sorting more numbers on average, even in the output array, so we should expect less false sharing on average for a random input.
In the lecture video Kayvon said that for this algorithm increasing number of processors increased false sharing, and increasing the array size N decreases false sharing. I didn't understand the explanation of why, can anyone explain? Is the false sharing just happening on the edges between the processors, and the lower the data-per-processor ratio is the more elements are near the edges? Couldn't you just divide up the data slightly unevenly so that each processor had a chunk of the array that doesnt fill a partial cache line?