Why is there a sudden spike in the data bus traffic for radix sort when we move from cache line sizes of 64 to 128 and 128 to 256? Does this have something to do with the layout of the data in memory?
regi
LU appears to be factoring matrices (see the wiki page). The reason its data bus traffic is essentially constant is likely because the algorithm has good spatial locality. Each thread/processor might use all of the data in a cache line. In the other algorithms, false sharing (different cores requesting different data on the same cache line) may cause a line to bounce back and forth between caches, increasing traffic.
lament
If I had to guess, part of the reason you see the spike for radix sort is because the x-axis is exponentially scaled, and the y-axis is linear. The general graph for the radix sort and some of the others seem to be showing a positive-sloped, convex curve, which likely is partially due to scaling. I am not trying to say someone is trying to deceive you with the graphs, just that there is a sense where these relations may be "more linear" than they appear. Obviously that is not the only thing going on, but its worth keeping in mind.
subliminal
Since false sharing increases with cache line size, shouldn't we expect both the data bus and the address bus to see more activity (or at least somewhat constant activity on the address bus, since coherence messages are shouted out all the time, anyway)? Or do we see a decrease in the address bus traffic because of improved true sharing? In which case, shouldn't the data bus traffic also see some sort of compensation?
subliminal
On second thought, I think that fewer misses don't compensate for more data being pulled in (in programs with bad spatial locality), but they do compensate somewhat for coherence and memory read request traffic.
msebek
To be clear:
Address Bus is the bus that cache controllers yell onto when checking if someone else owns it
Data Bus is the bus that the cache controllers send lines back and forth on (which means this is a MESIF/MOESI processor)?
Am I interpretting the Data Bus incorrectly? If this is the Data Bus' job, then as cache lines increase, we definitely would expect more data to be shuffled back and forth between processors.
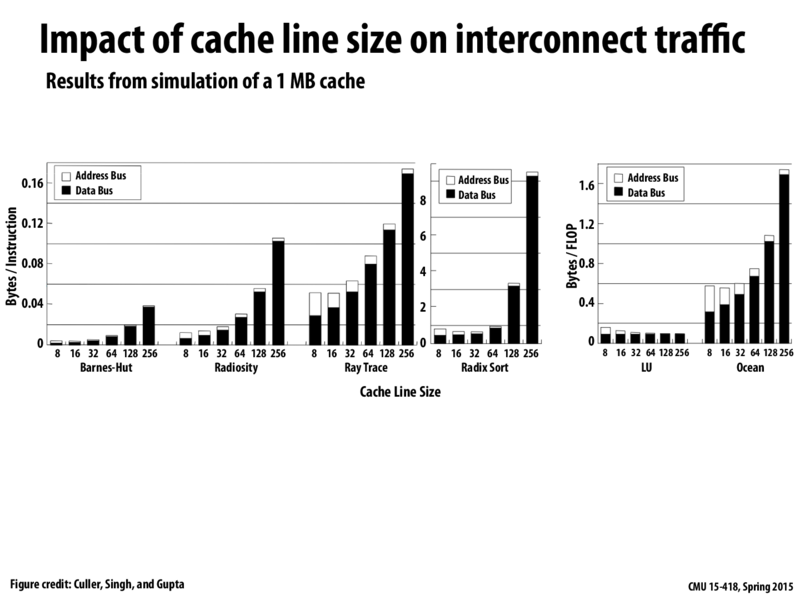
What is LU algorithm doing?
Why is there a sudden spike in the data bus traffic for radix sort when we move from cache line sizes of 64 to 128 and 128 to 256? Does this have something to do with the layout of the data in memory?
LU appears to be factoring matrices (see the wiki page). The reason its data bus traffic is essentially constant is likely because the algorithm has good spatial locality. Each thread/processor might use all of the data in a cache line. In the other algorithms, false sharing (different cores requesting different data on the same cache line) may cause a line to bounce back and forth between caches, increasing traffic.
If I had to guess, part of the reason you see the spike for radix sort is because the x-axis is exponentially scaled, and the y-axis is linear. The general graph for the radix sort and some of the others seem to be showing a positive-sloped, convex curve, which likely is partially due to scaling. I am not trying to say someone is trying to deceive you with the graphs, just that there is a sense where these relations may be "more linear" than they appear. Obviously that is not the only thing going on, but its worth keeping in mind.
Since false sharing increases with cache line size, shouldn't we expect both the data bus and the address bus to see more activity (or at least somewhat constant activity on the address bus, since coherence messages are shouted out all the time, anyway)? Or do we see a decrease in the address bus traffic because of improved true sharing? In which case, shouldn't the data bus traffic also see some sort of compensation?
On second thought, I think that fewer misses don't compensate for more data being pulled in (in programs with bad spatial locality), but they do compensate somewhat for coherence and memory read request traffic.
To be clear: Address Bus is the bus that cache controllers yell onto when checking if someone else owns it Data Bus is the bus that the cache controllers send lines back and forth on (which means this is a MESIF/MOESI processor)?
Am I interpretting the Data Bus incorrectly? If this is the Data Bus' job, then as cache lines increase, we definitely would expect more data to be shuffled back and forth between processors.