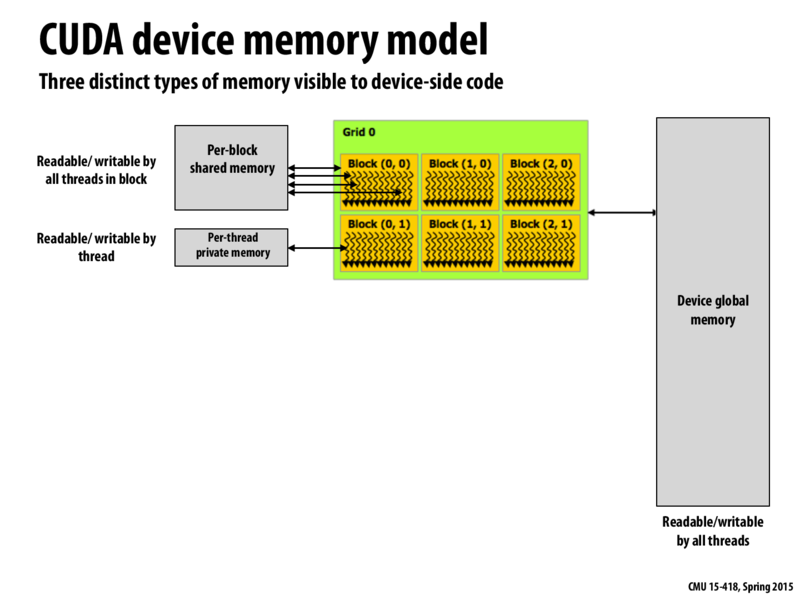
Is it safe to assume that the chip is designed in such a way that we shouldn't have to worry about bandwidth of transfers between global, shared, and private memory?
rbandlam
How can we visualize per-block shared memory and per-thread private memory in terms of hardware. Is it like that memory resides in cache? Or is it a simple abstraction in terms of implementation that enables threads of same block to access shared memory faster?
lament
@caretcaret No, that is not an acceptable assumption to make. You can think of these address spaces in a similar fashion as you would cache v.s. disk in the CPU; one is faster than the other and you want to take advantage of that. In the case of the GPU, I believe there are more requirements (from the programmer's perspective) for what goes in each address space than there are for CPUs (see below).
As mentioned later in the slides, thread blocks are run on one "core", allowing them to communicate faster via the shared memory. It is worth keeping in mind that part of the abstraction we are working with specifies that blocks of threads run together (and can communicate or be preempted) where as when blocks of threads are run in respect to one another is (also) entirely out of the programers hands.
caretcaret
@lament I understand that the memory hierarchy is set up to reduce latency, but is the on-chip bandwidth higher than the host-device bandwidth? If not, then the chip itself is a bottleneck that needs to be taken into consideration. If so, how low of an arithmetic intensity does the chip support?
Is it safe to assume that the chip is designed in such a way that we shouldn't have to worry about bandwidth of transfers between global, shared, and private memory?
How can we visualize per-block shared memory and per-thread private memory in terms of hardware. Is it like that memory resides in cache? Or is it a simple abstraction in terms of implementation that enables threads of same block to access shared memory faster?
@caretcaret No, that is not an acceptable assumption to make. You can think of these address spaces in a similar fashion as you would cache v.s. disk in the CPU; one is faster than the other and you want to take advantage of that. In the case of the GPU, I believe there are more requirements (from the programmer's perspective) for what goes in each address space than there are for CPUs (see below).
As mentioned later in the slides, thread blocks are run on one "core", allowing them to communicate faster via the shared memory. It is worth keeping in mind that part of the abstraction we are working with specifies that blocks of threads run together (and can communicate or be preempted) where as when blocks of threads are run in respect to one another is (also) entirely out of the programers hands.
@lament I understand that the memory hierarchy is set up to reduce latency, but is the on-chip bandwidth higher than the host-device bandwidth? If not, then the chip itself is a bottleneck that needs to be taken into consideration. If so, how low of an arithmetic intensity does the chip support?